
IUPAC Nomenclature
IUPAC nomenclature uses the longest continuous chain of carbon atoms to determine the basic root name of the compound.
The root name is then modified due to the presence of different functional groups which replace hydrogen or carbon atoms in the parent sturcture.
There are a number of different ways to modify the root name to indicate the functional groups present.
Substitutive : (most common) : the highest priority functional group modifies the suffix of the root name, while all other groups, or substituents, are added as prefixes to the root name.
Functional group : names the compound based on the highest priority functional group, i.e. as an alcohol, ketone, alkyl halide, etc.
Replacement : used to indicate when an atom, usually carbon, is replaced by another atom.
Conjunctive : used to combine named subunits (i.e. cyclohexanecarboxylic acid).
Common or trivial : due to widespread use, some compunds with simple names have been adopted into basic IUPAC nomenclature.
| These pages focus primarily on the substitutive and functional group nomenclature but also include examples of all systems in cases where the name is generated by a combination of methods. |
Remember:
that organic molecules can in general be either chains (also known as acyclic) or cyclic or a combination of both. In most cases this doesn't make a difference. The general rules for cyclic systems will be developed for cycloalkanes and can be applied to other scenarios.
molecules are not restricted to a single functional group, they can have several functional groups. A common example are amino acids which have both an amine and a carboxylic acid present.
However, the most important feature of nomenclature is that given a complete name, a single unique structure can be drawn |
Basic rules
The IUPAC systematic name of an organic compound can be constructed based on a series of steps and rules:
Identification of the principal functional group and substituents
Identification of the longest continuous chain containing the principal functional group.
Assign locants (i.e. numbering) to the principal functional group and substituents.
Misconception Alert! When assigning the numbers (i.e. the locants) while naming an organic compound there is NO rule based on summing the numbers. |
The steps and rules are summarised below, more details are provided as the cases are encountered.
Principal Functional group |
|
| Longest chain |
|
| Numbering (i.e. assigning locants) |
|
What's in a name?
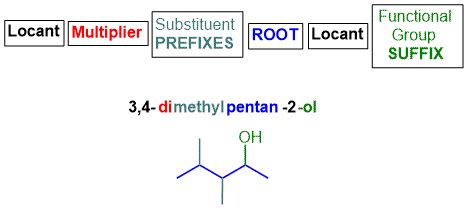
The IUPAC name of an organic molecule is assembled from components that describe various features and parts of the molecule.
Functional group suffix
This is added to the end of the name based on the principal functional group.
Root
This defines the number of atoms (usually carbon atoms) in the longest continuous chain that contains the principal functional group.
Substituent prefix
Any groups other than the principal functional group appended to the root chain are called substituents, i.e. they have replaced an H atom on that root chain.
Substituents are added to the beginning of the name and are listed in alphabetical order.
Multiplier
If a functional group or substituent occurs more than once, a simple multiplier (e.g. di, tri, tetra, etc.) is used to indicate how many times it occurs.
Locants
Locants are numbers (or occasionally letters e.g. N-) that define the position of the principal functional group and substituents. Typically there needs to be a locant for each functional group and each substituent. The 1993 modifications requires that the locant for the principal functional group is placed before the functional group suffix, e.g. pentan-2-ol, see below. Note that the functional group priority order (see functional group page) only applies if the group is being named as the principal functional group (i.e. it contributes as the functional group suffix), and the priority order does not apply if the group is named as a substituent.
The basic structure of the IUPAC name is shown schematically below :
| |
Functional Groups
Here is a list of the more important functional groups arranged in decreasing priority order for a nomenclature perspective.
Note that aromatic systems (arenes) such as a benzene ring should also be thought of as a functional group, but they don't fit into the priority order list shown below.
This priority order is important in nomenclature as the higher priority group is the principal functional group and it is typically numbered such that it has the lowest number (the lowest locant).
You need to learn to recognise these functional groups not just for nomenclature but in order to recognise their reactions later.
In each case the fundamental functional group unit is shown, it is this that you need to be able to recognise - pay attention to the atoms involved and the bonding patterns.
Note the "R" is used to represent generic groups based on C (such as a methyl group) or just H.
All the 3D-JSMOL structures can be manipulated using your computer mouse (e.g. zoom, rotate)
Functional | Formula | Structure |
Carboxylic Acids |
| |
Acid Anhydrides |
| |
Esters |
| |
Acyl Halides |
| |
Amides |
| |
Nitriles |
| |
Aldehydes |
| |
Ketones |
| |
Alcohols |
| |
Thiols |
| |
Amines |
| |
Ethers |
| |
Sulfides |
| |
Alkenes |
| |
Alkynes |
| |
Alkyl Halides |
| |
Nitro |
| |
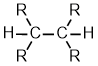
Alkanes |
|
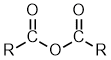
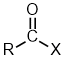
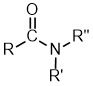
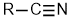
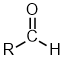
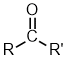
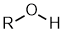
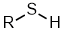
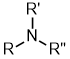
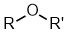
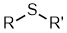
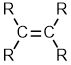
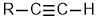
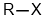
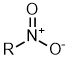
Root names
Here is a list of the root names for naming the parent hydrocarbon chains of C1 to C12 and a few other biologically important chains.
This list is very important as it provides the foundation for all IUPAC nomenclature : you will have to learn the names.
You can see models of C1-C10 by using the buttons above the box.
|
Alkanes
| Nomenclature | Formula | 3D structure |
| Functional group suffix = -ane Substituent name = alkyl Structural unit : alkanes contain only C-C and C-H bonds. Note: alkanes are the simplest organic compounds and are the minimum present in an organic molecule. | 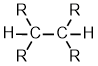 |
| Propane CH3CH2CH3 | |
| Cyclopropane
|

Simple Branched Alkanes
Simple branched alkanes are really alkanes with alkyl substituents. The principles covered here will apply to other substituted systems in general.
The substituent is named in a similar way to the parent alkane. It is named based on the number of carbon atoms in the branch plus the suffix -yl.
| CH3- | methyl |
| CH3CH2- | ethyl |
| CH3CH2CH2- | propyl |
| CH3CH2CH2CH2- | butyl |
| CH3CH2CH2CH2CH2- | pentyl |
In general an alkane type substituent becomes an alkyl group (often represented as "R-")
The name is then constructed in the standard way with locant + substituent prefix + root name based on the basic rules.
When constructing the name, hyphens separate locants and letters, commas separate locants. No spaces.
Consider the following examples:
2-methylpentane | 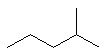 CH3CH2CH2CH(CH3)2 |
3-ethylpentane | 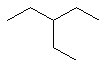 CH3CH2CH(CH2CH3)CH2CH3 |
3,3-dimethylhexane | 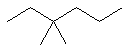 CH3CH2C(CH3)2CH2CH2CH3 |
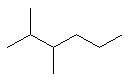
2,3-dimethylhexane |
(CH3)2CHCH(CH3)CH2CH2CH3 |
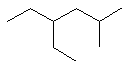
4-ethyl-2-methylhexane |
(CH3CH2)2CHCH2CH(CH3)2 |
Common names for alkyl substituents
Certain alkyl substituents are very common, and you should be able to recognise and name them quickly, these are listed below.
In each case, the structural formula of the substituent is given where the C that is attached to the rest of the molecule is in bold. A line drawing of a generic example and the molecular models of the series of alkyl bromides are also available.
Notes:
the the prefix iso is not hyphenated.
the symbol "R" is commonly used to generically represent an alkyl group, e.g. R-X
| Structural formula | Name | Symbol | Generic line drawing |
| CH3- | methyl | Me | 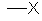 |
| CH3CH2- | ethyl | Et | 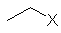 |
| CH3CH2CH2- | propyl | Pr |  |
| (CH3)2CH- | isopropyl | iPr | 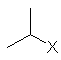 |
| CH3CH2CH2CH2- | butyl |  | |
| CH3CHCH2CH3 | sec-butyl or s-butyl | 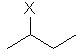 | |
| (CH3)2CHCH2- | isobutyl | 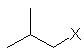 | |
| (CH3)3C- | tert-butyl or t-butyl | tBu | 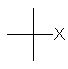 |
Complex names for alkyl substituents
The list of common alkyl substituents is quite short and it is therefore quite limited in its scope. In order to deal with other substituents (but it can also be applied to the common branched substituents too), there is a methodology for dealing with more complex substituents. This essentially involves treating the substituent as if it were a molecule on its own, see below.
For the substituent:
determine the point of attachment to the chain that defines the parent root (i.e. the longest continuous chain)
the first carbon in the substituent is regarded as the C1 of the substituent
from C1, find the longest continuous chain originating from C1 - this is the root for the substituent.
identify any substituents off this chain
list these alphabetically with appropriate multipliers
insert locants as required remembering that the point of attachment is defined as C1.
Now include this "complex" substituent in the overall name...
the complex substituent appears in brackets proceeded by its locant
the complex substituent is alphabetised based on the first letter of the name in the bracket : this includes the multiplier e.g. di
this is because the term in brackets is the name of the whole complex substituent and not several substituents.
syntax: locant numbers separated from letters by hyphens, e.g. 1-methyl, locant numbers from locant numbers by commas e.g. 1,1-dimethyl, no spaces.
Consider the following examples:
First work out the name of the complex substituent - this is shown in bold in the figure:
Complex substituent name : 2-methylpropyl | 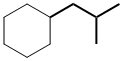 | |
Now work on the whole structure:
(2-methylpropyl)cyclohexane | 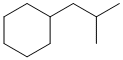 |
First work out the name of the complex substituent - this is shown in bold in the figure:
Complex substituent name : 1,1-dimethylethyl | 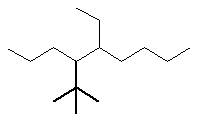 | |
Now work on the whole structure:
4-(1,1-dimethylethyl)-5-ethylnonane | 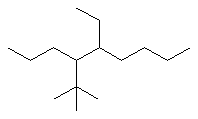 |
Of course, the common alkyl substituents can also be named in this more systematic way. Both methods are used and you should be familiar with both methods. The following table list the common alkyl substituents with both naming methods.
| Alkyl group, R- | Common name | Complex name (if different) |
| CH3- | methyl | |
| CH3CH2- | ethyl | |
| CH3CH2CH2- | propyl | |
| (CH3)2CH- | isopropyl | (1-methylethyl) |
| CH3CH2CH2CH2- | butyl | |
| CH3CH2CHCH3 | sec-butyl or s-butyl | (1-methylpropyl) |
| (CH3)2CHCH2- | isobutyl | (2-methylpropyl) |
| (CH3)3C- | tert-butyl or t-butyl | (1,1-dimethylethyl) |
Remember that if a structure has two chains of equal length, then the choice that gives the simplest branches is chosen, see below for an example.
3-ethyl-2,4-dimethylhexane | 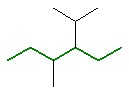 or 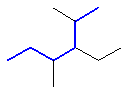 |
Substituted Cycloalkanes
Substituted cycloalkanes are named in an analogous fashion to regular alkanes (also referred to as acyclic alkanes, i.e. non-cyclic alkanes).In principle, a substituted cycloalkane could be name in two ways, either as an alkyl substituted cycloalkane, or as a cycloalkyl substituted alkane
When the ring size (e.g. number of C atoms) is larger than the longest continuous chain, then the ring becomes the parent and hence the system is treated as a alkyl cycloalkane.
If a ring is monosubstituted then no locant is required since the substituent must be at C1.
If a ring is polysubstituted then each substituent requires a locant to unambiguously assign their relative positions.
2-cyclopropylbutane | 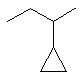 |
ethylcyclohexane | 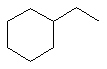 |
1-ethyl-2-methylcyclohexane | 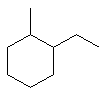 |
Polycyclic alkanes
There are four basic types of polycyclic systems based on how the rings are connected together. There are slight differences in the way in which they are named.The systems can be further classified according to the number of rings present (e.g. 2 = bicyclic, 3 = tricyclic, 4 = tetracyclic etc.). The examples shown below are all bicyclic systems.
If you mouseover the images, then the common atoms and bonds will be highlighted.
(1) Substituted systems The ring systems have no common atoms. In naming, it should be treated as a subsituted cycloalkane where the smaller ring is regarded as a substituent of the larger ring. The simplest example is the C6 system shown to the right.
| |
| (2) Spiro ring systems Spiro ring systems share a single common atom. Hence the rings join at a single "point". The simplest example is the C5 system shown to the right.
| |
| (3) Fused ring systems Fused ring systems share two common atoms in one common bond, hence the rings share one side. The simplest polycyclic system is the C4 system shown to the right where the rings share two atoms (one common side).
| |
| (4) Bridged ring systems Bridged ring systems share more than two common atoms. The simplest polycyclic system is the C5 system shown to the right where the rings contain three common atoms (two common sides). If we view the two rings as been the one on the left and the other on the right, then the highlighted C atoms are common to both (mouseover image).
| 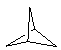 |
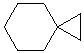
Spirocyclic alkanes
The root name is based on the number of C atoms in the ring structures.
The prefix spiro[x.y] is added where x and y are the number of atoms in the links as defined below.
The size of the rings is indicated in square brackets by counting the number of atoms in the links that make each ring, x and y, excluding the spirocenter.
The number of atoms in the links is listed smallest first, i.e. spiro[x.y] where y > x
For substituted spiroalkanes, the rings are numbered starting on the smallest ring adjacent to the spirocenter.
If that does not resolve the numbering, then the other rules for determining locants are applied in order (i.e. principal functional group, first point of difference, alphabetisation).
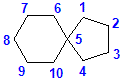 |
STUDY TIP |
spiro[2.2]pentane |
|
spiro[2.5]octane |
|
5-methylspiro[3.5]nonane | 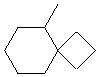 |
1-methylspiro[3.5]nonane | 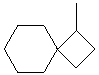 |
Fused and bridged bicycloalkanes
The root name is based on the total number of C atoms in the ring structures.
The prefix bicyclo[x.y.z] is added where x, y and z correspond to the number of atoms in the "links" as defined below.
The size of the rings is indicated in the square brackets by counting the number of atoms in the links that make each ring, x, y and z, excluding the bridgehead atoms
The number of atoms in the links are listed largest first, i.e. bicyclo[x.y.z] where x > y > z
For substituted bicycloalkanes, the rings are numbered starting at a bridgehead atom and proceeding round the rings, the largest ring first.
If that does not resolve the numbering, then the other rules for determining locants are applied in order (i.e. principal functional group, first point of difference, alphabetisation).
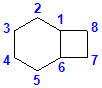
For example, in the structure shown above, the bridgehead atoms are C1 and C6. The three links are x= C2,C3,C4,C5, y = C7,C8 and the final link z has no atoms in it, so this is a [4.2.0] system.
STUDY TIP |
bicyclo[1.1.0]butane |
|
bicyclo[2.2.1]heptane | 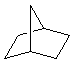 |
bicyclo[4.3.1]decane |  |
1,3-dimethylbicyclo[3.3.1]nonane | 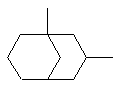 |
Alkenes
| Nomenclature | Formula | 3D structure |
| Functional group suffix = -ene Substituent name = alkenyl Structural unit : alkenes contain C=C bonds. |
|
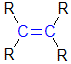
The root name is based on the longest chain containing both ends of the alkene unit, the C=C.
The chain is numbered so as to give the alkene unit the lowest possible numbers.
The locant for the first carbon of the alkene is used in the name.
If the position of the alkene is unambiguous, the locant is not required, see examples below.
As we will see later, in certain cases we will also need to specify the stereochemistry. We are going to ignore stereochemistry on this page to deal with the basics first.
propene | CH3CH=CH2 |
but-2-ene or 2-butene | CH3CH=CHCH3 |
but-1-ene or 1-butene | CH3CH2CH=CH2 |
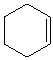
cyclohexene |
|
4-methylpent-2-ene or 4-methyl-2-pentene | 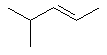 |
3-methylhex-3-ene or 3-methyl-3-hexene | 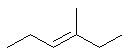 |
If alkenes have two different substituents at each end of the C=C then they can exist as stereoisomers (as geometric isomers).
This is because there is restricted rotation of the double bond due to the pi bond which means they don't readily interconvert.
Examples:
all terminal alkenes i.e. those with a C=CH2 unit can not exist as cis- and trans- isomers.
similarly, all 1,1-symmetrically disubstituted alkenes i.e. those with a C=CR2 unit can not exist as cis- and trans- isomers.
the terms cis- and trans- are assigned based on the relative arrangement of the alkyl groups that form the root name on the alkene unit. In general terms, that means including the principal functional group.
alkenes with the R1-CH=CH-R2 unit can exist as cis- and trans- isomers.
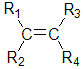
There are two ways to name these types of isomers, one is the cis / trans method which is described here, the other is E / Z method that is described on the next page.
Misconception Alert! cis ¹ Z and trans ¹ E In general terms there is NO specific relationship between cis and trans / E and Z as they are based on fundamentally different naming rules. |
1,2-disubstituted alkenes are described as:
cis- if the two alkyl groups, R-, that form the longest chain (i.e. the root name) are on the same side of the C=C
trans- if the two alkyl groups, R-, that form the longest chain (i.e. the root name) are on opposite sides of the C=C.
these terms are inserted into the name as prefixes.
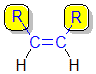 | 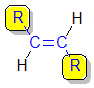 |
| cis- | trans- |
For example, but-2-ene, where both R = methyl :
| trans-but-2-ene | 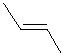 | 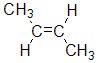 | |
| cis-but-2-ene | 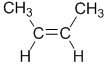 |
Tri- or tetrasubstituted alkenes are described as cis- and trans- based on the relative arrangement of the groups that form the parent hydrocarbon carbon chain that gives the root name. In the example shown the below, the longest carbon chain that gives the root name is highlighted in blue:
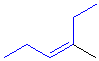 | ||
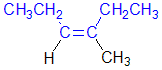 | ||
| trans-3-methylhex-3-ene | cis-3-methylhex-3-ene |
E- and Z-nomenclature of alkenes
On the previous pages, we looked at naming alkenes as cis- and trans-.
Misconception Alert! cis ¹ Z and trans ¹ E In general terms there is NO specific relationship between cis and trans / E and Z as they are based on fundamentally different naming rules. |
It is important to note that the two methods are different (i.e. they are based on different rules) and they are NOT interchangeable, see below for an example.
The cis- / trans- style is based on the longest chain whereas the E/Z style is based on a set of priority rules.
You need to know both styles.
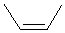 | 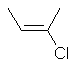 |
| cis-but-2-ene or (Z)-but-2-ene | cis-2-chlorobut-2-ene |
The E- and Z- style is more reliable and particularly suited to tri- or tetra-substituted alkenes, and especially when the substituents are not alkyl groups.
The Cahn-Ingold-Prelog priority rules are used for naming geometric isomers (e.g. E- or Z-alkenes) and other stereoisomers (see later).
In order to apply the Cahn-Ingold-Prelog priority rules to alkenes:
Imagine each alkene as two pieces, each piece containing one of the sp2 C atoms
Assign the priority (high = 1, low = 2) to each atom attached to each sp2 C based on atomic number
Subrules:
Isotopes: H vs D ? Since isotopes have identical atomic numbers, the mass number is used to discriminate them so D > H
Same atom attached ? By moving out away from the C=C one atom at a time, locate the first point of difference and apply the priority rule there.
Determine the relative position of the two higher priority groups
If they are on the same side then it is a (Z)-alkene (German; zusammen = together)
If they are on opposite sides then it is an (E)-alkene (German; entgegen = opposite)
If there is more than one C=C that can be E/Z, then the locant and the stereochemistry of each alkene needs to be included e.g. (2E,4Z)-
Example: but-2-ene
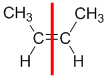 | 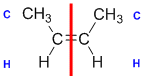 | 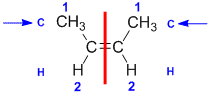 | <img src="http://www.chem.ucalgary.ca/courses/351/WebContent/orgnom/alkenes/alkenes-31d.gif" alt="relative positions" width="210" height="96" "=""> | |
| Step 1: Split the alkene | Step 2: List the attached atoms looking for the first point of difference. Here we have C and H atoms attached. | Step 3: | Step 4: Look at the relative positions of the higher priority groups: same side = Z, hence (Z)-but-2-ene | |
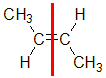 | 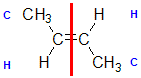 | 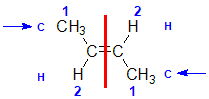 | 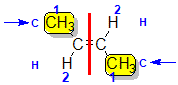 | |
| Step 1: Split the alkene | Step 2: List the attached atoms looking for the first point of difference. Here we have C and H atoms attached. | Step 3: Assign the relative priorities. Since the atomic numbers C > H then the -CH3 group is higher priority. | Step 4: Look at the relative positions of the higher priority groups: opposite side = E, hence (E)-but-2-ene | |
Example: 3-methylpent-2-ene
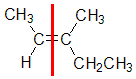 | 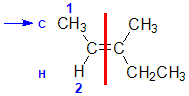 | 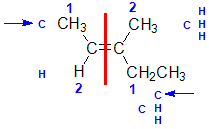 | 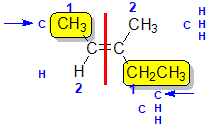 | |
| Step 1: Split the alkene | Step 2: Assign the relative priorities. The two atoms attached to the left end C are C and H, so since the atomic numbers C > H then the -CH3 group is higher priority. | Step 3: | Step 4: Look at the relative positions of the higher priority groups : opposite side = E, hence(E)-3-methylpent-2-ene. |
Alkenes as substituents
In some cases, a group containing an alkene may need to be treated as a substituent.
In these cases the substituent is named in a similar fashion to simple alkyl substituents.
The method is required when the alkene is not the priority group.
The substituent is named in a similar way to the parent alkene.
It is named based on the number of carbon atoms in the branch plus the suffix -yl. i.e. alkenyl
There are two common names that are widely used:
| Alkenyl group | Common name | Systematic name |
| CH2=CH- | vinyl- | ethenyl |
| CH2=CHCH2- | allyl- | 2-propenyl |
| CH3CH=CH- | 1-propenyl |
trans-3-ethenylhexa-1,4-diene | 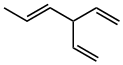 CH3CH=CHCH(CH=CH2)2 |
Polyenes
The term polyene simply implies the presence of several alkenes. To be more specific, a diene has two C=C, a triene has 3 C=C etc.Polyenes are named in a similar manner to alkenes themselves.
The root name is based on the longest chain containing both ends of all the alkene units.
The chain is numbered so as to give the one of the alkene units the lowest possible number (i.e. first point of difference).
The locant for the lowest numbered carbon of each alkene is used in the name.
The appropriate multiplier (i.e. di- for two, tri for three) is inserted before the -ene suffix.
In order make the name pronounceable, -a- is inserted after the root.
If there is more than one C=C that can be E/Z, then the location needs to be included with the locants and listed in numerical order, e.g. (2E,4Z)-
Or, if using cis/trans- then the terms are listed in locant order e.g. trans,cis-
buta-1,3-diene |  CH2=CHCH=CH2 |
(E)-penta-1,3-diene or |  CH3CH=CHCH=CH2 |
2-methylpenta-1,4-diene or | 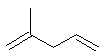 CH3C(CH3)=CHCH=CH2 |
(2E,4Z)-hepta-2,4-diene | 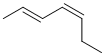 |
Alkynes
| Nomenclature | Formula |
| Functional group suffix = -yne Substituent prefix = alkynyl Structural unit : alkynes contain C≡C bonds. |
|
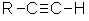
The root name is based on the longest chain containing both ends of the alkyne unit, the C≡C.
The chain is numbered so as to give the alkyne unit the lowest possible number.
but-1-yne or 1-butyne | CH3CH2C≡CH |
but-2-yne or 2-butyne | CH3C≡CCH3 |
Polyynes
The term polyyne simply implies the presence of several alkynes. To be more specific, a diyne has two C≡C, a triyne has three C≡C etc.Polyynes are named in a similar manner to alkynes themselves and to polyenes.
The root name is based on the longest chain containing both ends of all the alkyne units.
The chain is numbered so as to give the one of the alkyne units the lowest possible number (i.e. first point of difference).
The locant for the lowest numbered carbon of each alkyne is used in the name.
The appropriate multiplier (i.e. di- for two, tri for three) is inserted before the -yne suffix.
In order make the name pronounceable, -a- is inserted after the root.
hexa-1,4-diyne or | 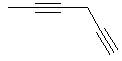 CH3C≡CCH2C≡CH |
Enynes
The term enyne simply implies the presence of both an alkene and an alkyne.Enynes are named in a similar manner to alkenes, alkynes and polyenes.
The root name is based on the longest chain containing both ends of the alkene and alkyne units.
The alkene suffix "ene" minus the last "e" is inserted after the root with its locant before the root.
The alkyne suffix, "yne" is added at the end with its locant preceding it.
Hence alkene + alkyne = enyne.
The chain is numbered in accord with the first point of difference rule to either the alkene or alkyne units the lowest possible locant.
The locant for the lowest numbered carbon of the alkene or alkyne is used in the name.
If there is a choice, then the C=C takes priority and is given the lowest locant.
hex-1-en-4-yne |
CH2=CHCH2C≡CCH3 |
cis-hex-4-en-1-yne |
CH3CH=CHCH2C≡CH |
pent-1-en-4-yne |
CH2=CHCH2C≡CH |
Haloalkanes / Alkyl halides
| Nomenclature | Formula | 3D structure |
| Functional group suffix = halide (i.e. fluoride, chloride, bromide, iodide) Substituent name = halo- (i.e. fluoro, chloro, bromo, iodo) Structural unit : haloalkanes contain R-X where X = F, Cl, Br, I etc. Notes :
|
|
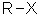
Haloalkane style:
The root name is based on the longest chain containing the halogen.
This root give the alkane part of the name.
The type of halogen defines the halo prefix, e.g. chloro-
The chain is numbered so as to give the halogen the lowest possible number
The root name is based on the longest chain containing the halogen.
This root give the alkyl part of the name.
The type of halogen defines the halide suffix, e.g. chloride
The chain is numbered so as to give the halogen the lowest possible number.
Haloalkane style:
bromoethane Alkyl halide style:
ethyl bromide | CH3CH2Br |
Haloalkane style:
1-chloropropane | CH3CH2CH2Cl |
Alkyl halide style:
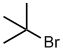
tert-butyl bromide Haloalkane style:
2-bromo-2-methylpropane |
(CH3)3CBr |
Haloalkane style:
4-bromobut-1-ene |
|
Alcohols
| Nomenclature | Formula | 3D structure |
| Functional class name = alkyl alcohol e.g. ethyl alcohol Substituent suffix = -ol e.g. ethanol Substituent prefix = hydroxy- e.g. hydroxyethane Structural unit : alcohols contain R-OH |
|
The root name is based on the longest chain with the -OH attached.
The chain is numbered so as to give the alcohol unit the lowest possible number.
The alcohol suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -ol = -anol or -ene + ol = -enol.
ethanol | CH3CH2OH |
propan-2-ol or 2-propanol | 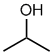 CH3CH(OH)CH3 |
but-3-en-1-ol or 3-buten-1-ol | CH2=CHCH2CH2OH |
Diols (or polyols)
The term diol simply implies the presence of two alcohols. Polyols contain two or more -OH groups.The root name is based on the longest chain containing both the alcohol groups.
The chain is numbered so as to give the one of the alcohol groups the lowest possible number (i.e. first point of difference).
The appropriate multiplier (i.e. di- for two, tri for three etc.) is inserted before the -ol suffix or before the root.
ethane-1,2-diol | HOCH2CH2OH |
propane-1,2-diol 1,2-propanediol | 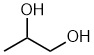 CH3CH(OH)CH2OH |
butane-1,4-diol 1,4-butanediol | HOCH2CH2CH2CH2OH |
cyclohexane-1,2-diol 1,2-cyclohexanediol | 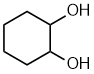 |
Thiols
| Nomenclature | Formula |
| Functional class name = alkyl mercaptan Substituent suffix = -thiol e.g. ethanethiol Substituent prefix = sulfanyl- e.g. Structural unit : alcohols contain R-SH Note: Thiols are the sulfur analogues of alcohols |
|
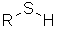
The root name is based on the longest chain with the -SH attached.
The chain is numbered so as to give the thiol unit the lowest possible number.
The thiol suffix is appeneded after the hydrocarbon suffix : e.g. -ane + -thiol = -anethiol or -ene + thiol = -enethiol.
propane-2-thiol | CH3CH(SH)CH3 |
Ethers
<td font-weight:="" bold;"="" style="vertical-align: middle; width: 400px;">Functional class name = alkyl alkyl ether e.g. ethyl methyl etherSubstituent prefix = alkoxy- e.g. methoxyethane
| Nomenclature | Formula | 3D structure |
|
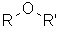
Examples of how each of the types of nomenclature are applied are given below. No one method is more correct than the other, but some guidance on the common practices is given.
Note : the examples chosen are to illustrate the naming subsystem.
In practice, the examples labelled (*) would probably all be named as alkyl alkyl ethers.
"Simple" ethers
If both groups are simple alkyl groups, then the ether is usually named as alkyl alkyl ether
The alkyl groups are listed in alphabetical order
If the two alkyl groups are the same, then it's a dialkyl ether
ethyl methyl ether | CH3CH2OCH3 | |
| CH3CH2OCH2CH3 |
"Intermediate" ethers
If one of the groups is more complex then the ether group is usually treated as an alkoxy substituent (i.e. R-O-).
The ether is treated as a substituent (i.e. it is not the principal functional group).
The more complex group (i.e. longer chain, principal functional group, more branched, other substituents) defines the root.
1-methoxypropane * | CH3CH2CH2OCH3 | |
2-methoxypropane * | CH3CH(OCH3)CH3 | |
4-methoxybut-1-ene | CH3OCH2CH2CH=CH2 | |
* In reality, these examples are simple enough that they would typically be named as alkyl alkyl ethers | ||
"Complex" ethers
If both groups are complex then the ether can be named using -oxa which treats the oxygen as a substituent in the chain.
The ether is treated as a substituent (i.e. it is not the principal functional group).
| CH3OCH2CH2CH3 | |
| CH3OC(CH3)3 | |
| * In reality, these examples are simple enough that they would typically be named as alkyl alkyl ethers | ||
Epoxides
| Nomenclature | Formula | 3D structure |
| Functional class name = alkene oxides e.g. ethene oxide Substituent suffix = -ene oxide e.g. ethene oxide Substituent prefix = epoxy- e.g. epoxyethane Note: The term oxirane is also used to describe epoxides. |
|
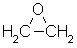
Epoxides are cyclic ethers, a 3 membered ring (see above diagram). Their reactivity is such that they are essentially a separate functional group.
There are two methods for naming epoxides:
as the oxide of the corresponding alkene (this relates to a method of synthesising them).
using the prefix epoxy- to indicate the epoxide as a substituent.
The root name is for the corresponding alkene (think of removing the oxygen and adding a C=C at that location).
Add the suffix oxide.
This is common for very simple epoxides.
Epoxy-
The root name is based on the longest chain with the two C-O bonds attached.
The chain is numbered so as to give the epoxide unit the lowest possible locant (again like alkenes)
The epoxide prefix is inserted prior to the root name along with both locants e.g. 1,2-epoxypropane.
Both locants are included since this method is also used for naming other cyclic ethers.
Alkene oxide style:
propene oxide Epoxy style:
1,2-epoxypropane |
| |
Alkene oxide style:
cyclohexene oxide Epoxy style:
1,2-epoxycyclohexane | 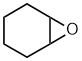 | |
Alkene oxide style:
5-methyl-2-hexene oxide Epoxy style:
2,3-epoxy-5-methylhexane | 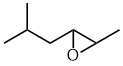 |
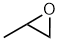
Thioethers or sulfides
| Nomenclature | Formula | 3D structure |
| Functional class name = alkyl alkyl sulfide e.g. ethyl methyl sulfide Substituent suffix = sulfide Substituent prefix = alkylthio- e.g. methylthioethane Substitutive = -thio- Structural unit : thioethers contain R-S-R | 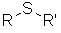 |
Thioethers are named in much the same way as their oxygen cousins, ethers.
If both groups are simple alkyl groups, then the thioether is usually named as alkyl alkyl thioether
The alkyl groups are listed in alphabetical order
If the two alkyl groups are the same, then it's a dialkyl thioether
ethyl methyl sulfide | CH3CH2SCH3 | |
dimethyl sulfide | CH3SCH3 |
If one of the groups is more complex then the thioether group is usually treated as an alkylthio- (i.e. R-S-) substituent.
The more complex group (i.e. longer chain, more branched, other substituents) defines the root.
1-methylthiopropane | CH3CH2CH2SCH3 |
"Complex" thioethers
If both groups are complex then the ether can be named using -thio
| CH3SCH2CH2CH3 |
Amines
| Nomenclature | Formula | 3D structure |
Functional class name = alkylamines or alkanamines
|
|
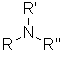
There are slight differences between amines depending on whether they are primary, secondary or tertiary (based on number of R groups attached to the N)
Primary amines
Primary amines have one alkyl group attached to the N.
The root name is based on the longest chain with the -NH2 attached.
The chain is numbered so as to give the amine unit the lowest possible number.
The amine suffix is appended to the appropriate alkyl root or alkana- root.
butan-2-amine or 2-butylamine | CH3CH2CH(NH2)CH3 |
Secondary amines
Secondary amines have two alkyl groups attached to the N.
The root name is based on the longest chain with the -NH attached.
The chain is numbered so as to give the amine unit the lowest possible number.
The other alkyl group is treated as a substituent, with N as the locant.
The N locant is listed before numerical locants, e.g. N,2-dimethyl....
The amine suffix is appended to the appropriate alkyl root or alkana- root.
N-methylethylamine | CH3NHCH2CH3 |
Tertiary amines
Tertiary amines have three alkyl group attached to the N.
The root name is based on the longest chain with the -N attached.
The chain is numbered so as to give the amine unit the lowest possible number.
The other alkyl groups are treated as substituents, with N as the locant.
The N locant is listed before numerical locants, e.g. N,2-dimethyl....
The amine suffix is appended to the appropriate alkyl root or alkana- root.
Name : N,N-dimethylmethylamine | (CH3)3N |
Diamines (or polyamines)
The term diamine simply implies the presence of two amines. Polyamines contain two or more amine groups.The root name is based on the longest chain containing both the amine groups.
The chain is numbered so as to give the one of the amine groups the lowest possible number (i.e. first point of difference).
The appropriate multiplier (i.e. di- for two, tri for three etc.) is inserted before the -amine suffix or before the root.
For secondary or tertiary amines, the N locant is used in the same manner as for amines.
If more than one N is substituted, then use N', N" etc.
The N locant is listed before numerical locants, e.g. N,N',2-trimethyl....
1,2-ethyldiamine |  H2NCH2CH2NH2 | |
N-methyl-1,3-propyldiamine | 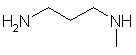 H2NCH2CH2CH2NHCH3 | |
N,N,N'-trimethyl-1,2-ethyldiamine |
|
Aldehydes
| Nomenclature | Formula | 3D structure |
| Functional class name = ? Substituent suffix = -al e.g. ethanal Substituent prefix = oxo- |
|
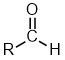
The root name is based on the longest chain including the carbonyl group.
Since the aldehyde is at the end of the chain, it must be C1.
The aldehyde suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -al = -anal or -ene + al = -enal etc.
propanal | CH3CH2CHO |
Ketones
| Nomenclature | Formula | 3D structure |
| Functional class name = alkyl alkyl ketone Substituent suffix = -one e.g. propan-2-one Substituent prefix = oxo- |
|
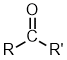
The root name is based on the longest chain including the carbonyl group.
The chain is numbered so as to give the ketone carbonyl the lowest possible number.
The ketone suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -one = -anone or -ene + one = -enone etc.
pentan-2-one or 2-pentanone | CH3CH2CH2C(=O)CH3 |
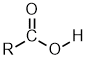
Carboxylic Acids
| Nomenclature | Formula | 3D structure |
| Substituent suffix = -oic acid e.g. ethanoic acid Substituent prefix = carboxy |
|
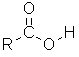
The root name is based on the longest chain including the carboxylic acid group.
Since the carboxylic acid group is at the end of the chain, it must be C1.
The carboxylic acid suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -oic acid = -anoic acid etc.
butanoic acid | CH3CH2CH2C(=O)OH |
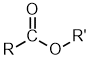
Esters
| Nomenclature | Formula | 3D structure |
| Functional class name = alkyl alkanoate Substituent suffix = -oate |
|
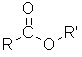
Esters are alkyl derivatives of carboxylic acids.
The easiest way to deal with naming esters is to recognise the carboxylic acid and the alcohol that they can be prepared from.
The general ester, RCO2R' can be derived from the carboxylic acid RCO2H and the alcohol R'OH.
The first component of an ester name, the alkyl is derived from the alcohol, R'OH portion of the structure.
The second component of an ester name, the -oate is derived from the carboxylic acid, RCO2H portion of the structure.
Alcohol component
The root name is based on the longest chain containing the -OH group.
The chain is numbered so as to give the -OH the lowest possible number.
Carboxylic acid component
The root name is based on the longest chain including the carbonyl group.
Since the carboxylic acid group is at the end of the chain, it must be C1.
The ester suffix for the acid component is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -oate = -anoate etc.
The complete ester name is the alkyl alkanoate
methyl propanoate | 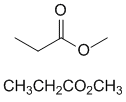 | |
2-propyl propanoate or isopropyl propanoate | 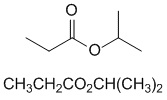 | |
methyl 2-methylpropanoate | 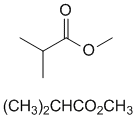 | |
2-propyl 2-methylbutanoate | 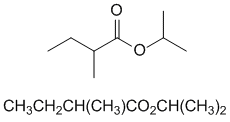 |
Amides
| Nomenclature | Formula | 3D structure |
| Functional class name = alkyl alkanamide Substituent suffix = -amide |
|
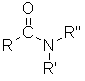
Amides are amine derivatives of carboxylic acids.
The root name is based on the longest chain including the carbonyl group of the amide group.
Since the amide group is at the end of the chain, the C=O carbon must be C1.
The amide suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -amide = -anamide etc.
If the amide nitrogen is substituted, the these substituents are given N- as the locant.
The N- locant is listed first when the same substituent occurs on N and other locations, e.g. N,2-dimethyl
butanamide | 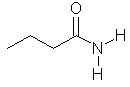 CH3CH2CH2C(=O)NH2 | |
N-methylbutanamide | 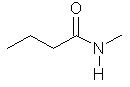 CH3CH2CH2C(=O)N(CH3)H | |
N,N-dimethylethanamide | 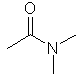 CH3C(=O)N(CH3)2 |
Acyl Halides or Acid Halides
| Nomenclature | Formula | 3D structure |
| Functional class name = acyl or acid halide Substituent suffix = -oyl halide |
|
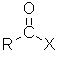
Acyl or acid halides are derivatives of carboxylic acids.
The root name is based on the longest chain including the carbonyl group of the acyl group.
Since the acyl group is at the end of the chain, the C=O carbon must be C1.
The acyl halide suffix is appended after the hydrocarbon suffix minus the "e" : e.g. -ane + -oyl halide = -anoyl halide etc.
The most common halide encountered is the chloride, hence acyl or acid chlorides, e.g. ethanoyl chloride
ethanoyl chloride | 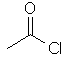 CH3C(=O)Cl | |
butanoyl chloride | 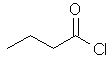 CH3CH2CH2C(=O)Cl | |
2-methylpropanoyl chloride | 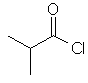 (CH3)2CHC(=O)Cl |
Acid Anhydrides
| Nomenclature | Formula | 3D structure |
| Functional class name = alkanoic anhydride Substituent suffix = -oic anhydride | 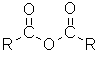 |
As the name implies, acid anyhydrides are derivatives of carboxylic acids.
In principle, they can be symmetric (where the two R groups are identical) or asymmetric (where the two R groups are different).
Symmetric anhydrides are the most common, they are named as alkanoic anhydrides
Asymmetric anhydrides are name in a similar fashion listing the alkyl groups in alphabetical order.
Cyclic anhydrides derived from dicarboxylic acids are name as -dioic anhydrides.
ethanoic anhydride | 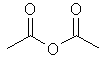 CH3C(=O)OC(=O)CH3 | |
butanoic propanoic anhydride | 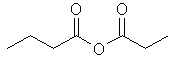 | |
pentandioic anhydride | 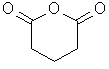 |
Nitriles
| Nomenclature | Formula | 3D structure |
| Functional class = alkyl cyanide Functional group suffix = nitrile or -onitrile Substituent prefix = cyano- Notes :
| 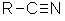 |
Cyano substituent style:
The root name is based on the longest chain with the -C≡N as a substituent.
This root give the alkane part of the name.
The chain is numbered so as to give the -C≡N group the lowest possible locant number
The root name is based on the longest chain including the carbon of the nitrile group.
This root give the alkyl part of the name.
Since the nitrile must be at the end of the chain, it must be C1 and no locant needs to be specified.
Nitriles can also be named by replacing the -oic acid suffix of the corresponding carboxylic acid with -onitrile.
Cyano substituent style:
1-cyanopropane Nitrile style:
butanenitrile | 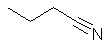 CH3CH2CH2C≡N |
Aromatic Systems (or arenes)
Formula | 3D structure | |
Benzene Benzene is an important structure. It's the most common aromatic hydrocarbon. Since benzene (and its relatives) have their own characteristic reactions, they are a functional group, often referrred to as arenes | 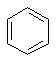 C6H6 |
In principle, all the substituents we have encountered can occur as substituents on benzene rings.
One way to name these is to use the benzene as the root and add the approriate substituent prefix.
ethylbenzene | 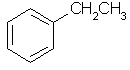 C6H5CH2CH3 |
bromobenzene | 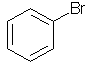 C6H5Br |
ethoxybenzene | 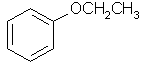 C6H5OCH2CH3 |
nitrobenzene | 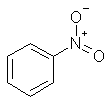 C6H5NO2 |
Common Substituted Benzenes
There are many common simple substituted benzenes with common names that are also used as part of the IUPAC system, here are the most important ones that you should know.
| Common name | Substituted benzene | Formula | 3D structure |
| Toluene | Methylbenzene | 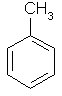 C6H5CH3 | |
| Styrene | Ethenylbenzene | 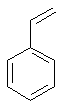 C6H5CH=CH2 | |
| Phenol | 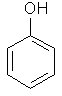 C6H5OH | ||
| Anisole | Methoxybenzene | 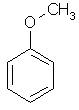 C6H5OCH3 | |
| Aniline | Aminobenzene | 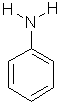 C6H5NH2 | |
| Benzoic acid | 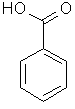 C6H5CO2H | ||
| Benzaldehyde | 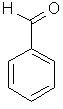 C6H5CHO | ||
| Benzonitrile | Cyanobenzene | 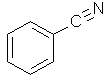 C6H5CN |
Benzene as a substituent
In some cases, the benzene ring needs to be treated as a substituent.
In these cases, the term phenyl, is used to designate the presence of C6H5- as a substituent.
Take care not to confuse terminology (it will be discussed on the next page)
benzyl substituent = C6H5CH2
phenol a compound = C6H5OH
phenyl substituent = C6H5
The method should be used when the benzene ring is a substituent of the root (the root contains the principle functional group).
phenylethene | 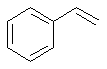 C6H5CH=CH2 |
3-phenylpropene | 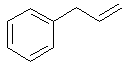 C6H5CH2CH=CH2 |
2-phenylethanol | 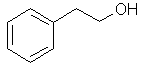 C6H5CH2CH2OH |
Phenyl or benzyl?
Phenyl and benzyl are not the same and can not be used interchangeably.
Take care not to confuse terminology :
benzyl substituent = C6H5CH2
phenyl substituent = C6H5
Here are some examples:
phenyl bromide | C6H5Br |
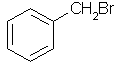 C6H5CH2Br | |
C6H5OCH2CH3 | |
benzyl methyl ether | 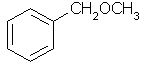 C6H5CH2OCH3 |
Disubstituted benzenes
When there are two (or more) substituents, the relative position of the subsituents must be defined.
There are two methods used based on either numerical locants or specific words for the three possible forms:

The words can also be shortened to their first letter, i.e. o-, m- and p-
The terms ortho-, meta- or para- (or their singel letter equivalents) are used as prefixes.
These terms are ONLY used for benzene systems.
When using numerical locants, the principal functional group is defined to be at C1.
The numerical locant method is also applicable to other aromatic systems.
Numerical locants method:
1,2-dichlorobenzene | 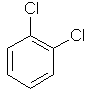 |
1-bromo-3-chlorobenzene | 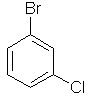 |
2-chlorophenol | 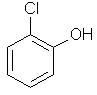 |
Ortho / meta / para method:
ortho-dichlorobenzene | |
meta-bromochlorobenzene | |
ortho-chlorophenol | |
Polysubstituted benzenes
When there are two (or more) substituents, the relative position of the subsituents must be defined.
Numerical locants are used to specify the locations if there are three (or more substituents).
The principal functional group is defined to be at C1.
In cases where the root can be defined using common aromatic names this is typically used.
The remaining substituents are listed alphabetically.
2-bromo-4-chlorotoluene | 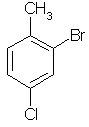 |
3,5-dimethylphenol | 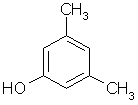 |
2-ethyl-3-methylaniline | 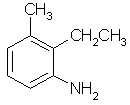 |
Stereochemistry
Stereoisomers are molecules that have the same connectivity (i.e. the same pieces in the same order) but differ only in the arrangement of those pieces in space.
For example, but-2-ene, CH3CH=CHCH3, has two possible stereoisomers due to the relative spatial positions of the -H and -CH3 groups on each end of the C=C unit.
| methyl groups on the same side | | ||
| methyl groups on opposite side | | |
Since these types of isomers are different molecules with different properties, they need to have individual and unique names.
The E- / Z- (alkenes) and R- / S- (chirality centers) nomenclature methods for naming stereoisomers are based on the use of the Cahn-Ingold-Prelog priority rules used for naming stereocenters.
These rules are used to establish the priority of the groups attached to the stereocenter and are based on atomic number, and the first point of difference. The rules are outlined below, specific examples are provided within the following pages for the different scenarios, see the links below.
Cahn-Ingold-Prelog priority rules
In order to rank the groups at a stereocenter (e.g. an alkene or a chirality center):
(1) identify the stereocenter
(2) identify each of the atoms attached to that stereocenter
(3) Assign the priority of the atom / group based on the atomic number of that atom. Higher atomic number = higher priority.
If the same type of atom is connected, then we need to look at the next atoms in the groups / chain moving away from the stereocenter until we find the first point of difference. A good method for doing this is to write down the attached atoms and then if needed, a list of the atoms they are attached to in priority order (i.e. atomic number)
Once the difference has been identified, the relative priorites can be determined.If a multiple bond is encountered, treat it as if the atoms are attached by the same number of single bonds e.g. C=C is treated as 2 x C-C and C=O is 2 x C-O
| Study tip for applying the Cahn-Ingold-Prelog priority rules (1) Label the stereocenters with * (2) List out the attached atoms in priority order |
Two areas of stereochemistry are described in the following pages:
(1) stereoisomerism at alkenes (e.g. cis- / trans- or E- / Z-)
(2) stereoisomerism at chirality centers (e.g. R- / S-)
Stereoisomers of Alkenes
As we have already described, alkenes with two different substituents at each end of the C=C can exist as a pair of stereoisomers.
The alkene can only exist as stereoisomers if R1 is not equal to R2 AND R3 is not equal to R4.
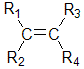
As we have already seen, there are two ways to name these types of isomers: (for a review details follow the links)
The E- and Z- style is more reliable (i.e. potentially less ambiguous) and particularly suited to highly substituted alkenes, especially when the substituents are not alkyl groups.
The E- and Z-alkene nomenclature system is based on the Cahn-Ingold-Prelog priority rules. They can also be used for naming chirality center stereoisomers (see later).
In order to apply the Cahn-Ingold-Prelog priority rules to alkenes:
Imagine each alkene as two pieces, each piece containing one of the sp2 C atoms
Assign the priority (high = 1, low = 2) to each atom attached to each sp2 C based on atomic number
Subrules:
Isotopes: H vs D ? Since isotopes have identical atomic numbers, the mass number is used to discriminate them so D > H
Same atom attached ? By moving out away from the C=C one atom at a time, locate the first point of difference and apply the priority rule there.
Determine the relative position of the two higher priority groups
If they are on the same side then it is a (Z)-alkene (German; zusammen = together)
If they are on opposite sides then it is an (E)-alkene (German; entgegen = opposite)
If there is more than one C=C that can be E/Z, then the locant and the stereochemistry of each alkene needs to be included e.g. (2E,4Z)-
Example: but-2-ene
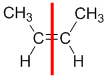 | 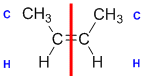 | 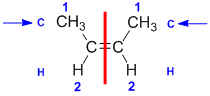 | <img src="http://www.chem.ucalgary.ca/courses/351/WebContent/orgnom/stereo/alkenes-31d.gif" alt="relative positions" width="210" height="96" "=""> | |
| Step 1: Split the alkene | Step 2: List the attached atoms looking for the first point of difference. Here we have C and H atoms attached. | Step 3: | Step 4: Look at the relative positions of the higher priority groups: same side = Z, hence (Z)-but-2-ene | |
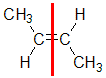 | 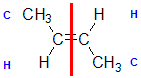 | 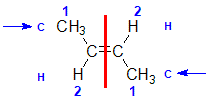 | 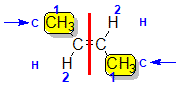 | |
| Step 1: Split the alkene | Step 2: List the attached atoms looking for the first point of difference. Here we have C and H atoms attached. | Step 3: Assign the relative priorities. Since the atomic numbers C > H then the -CH3 group is higher priority. | Step 4: Look at the relative positions of the higher priority groups: opposite side = E, hence (E)-but-2-ene | |
Example: 3-methylpent-2-ene
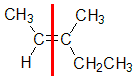 | 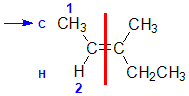 | 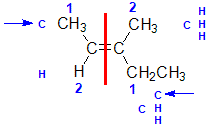 | 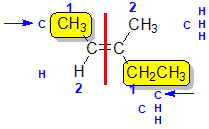 | |
| Step 1: Split the alkene | Step 2: Assign the relative priorities. The two atoms attached to the left end C are C and H, so since the atomic numbers C > H then the -CH3 group is higher priority. | Step 3: |
R- and S- nomenclature of chirality centers
The Cahn-Ingold-Prelog priority rules are used for naming chirality centers and geometric isomers (e.g. E- or Z-alkenes)
These rules are used to establish the priority of the groups attached to the chirality center and are based on atomic number, and the first point of difference.
In the simplest and most common case, a chirality center is characterised by an atom that has four different groups bonded to it in such a manner (e.g. tetrahedral) that it has a non-superimposable mirror image. Terms such as an asymmetric, stereogenic or chiral center have been used in the past.
| The most common chirality center in organic chemistry is a carbon atom with four different groups attached |
In order to assign the configuration as R or S:
Identify each of the chirality centers (most commonly an sp3 C with 4 different groups attached)
Then at each chirality center....
Assign the priority (high = 1 to low = 4) to each group attached to the chirality center based on atomic number.
Reposition the molecule so that the lowest priority group is away from you as if you were looking along the C-(4) σ bond. If you are using a model, grasp the lowest priority group in your fist.
Determine the relative direction of the priority order of the three higher priority groups (1 to 2 to 3)
If this is clockwise then it is the R-stereoisomer (Latin; rectus = right handed)
If this is counter-clockwise then it is the S-stereoisomer (Latin; sinister = left handed)
If there is more than one stereocenter, then the location needs to be included with the locant, e.g. (2R)-
Subrules:
Isotopes: H vs D ? Since isotopes have identical atomic numbers, the mass number is used to discriminate them so D > H
If the same atom is attached, then look for the first point of difference by moving out one atom at a time, locate the first point of difference and apply rules there.
If a multiple bond is encountered, treat it as if the atoms are attached by the same number of single bonds e.g. C=C is treated a 2 C-C and C=O is 2 C-O
HINT:
at each center, list out the 3 new atoms attached as you move away from the chirality center (see the 2nd example shown below)
list these groups in their priority order (i.e. high to low atomic number)
use this "list" to locate the first point of difference
Example: chlorofluoroiodomethane
The chirality center should be easy to spot, and the four attached groups are in priority order, highest to to lowest: I (purple), Cl (green), F(brown) and H (white) Rotate the image on the left so the you are looking along the C-H bond and the H is away from you, then determine the direction of high to low priority. |
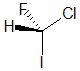 | 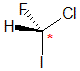 | 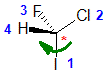 | 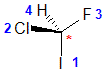 | 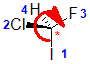 |
| starting point | identify the chirality center(s | assign the relative priorities then rotate the low priority group away (to the back) | determine the sense of groups 1 - 3 clockwise = R |
Example: cyclohex-2-enol
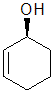 | 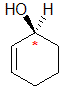 | 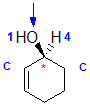 | 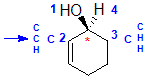 | 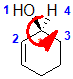 |
| starting point | identify the chirality center(s) and show the implied H atom | assign the relative priorities.... Because we have two C groups we need to list the groups the C are attached to in atomic number order | the first point of difference is the C > H so the C group on the left is the higher priority | with the low priority group already at the back, determine the sense of groups 1 - 3 counterclockwise = S |

