本文推荐一个公式输入神器,只要截图就能识别公式,手写的公式都能识别。经过实测,几乎没有识别不出的公式,并可以输入到word、markdown、latex文件。
一、前言
写论文、博客,技术文档,公式输入非常麻烦,绝大部分朋友记不住latex代码,机器之心推荐了一篇文章《最好用的文字与公式编辑器,这套数学笔记神器送给你》推荐了公式神器 Mathpix Snip。本站对这个神器进行实测。
二、识别公式测试
Mathpix Snip 这款神器只要截个图,公式会自动转化为 LaTex 表达式,我们只需要简单地修改就行了。
本站进行了实测,写了一个使用说明:
安装软件
网址:Mathpix Snip:https://mathpix.com/
安装就按照默认选项点击下一步即可。对公式截图和生成latex代码
这部分很简单,启动软件后,按快捷键:
CTRL+ALT+M
即可开始截图,对公式截图后,软件能自动识别并生成latex代码。
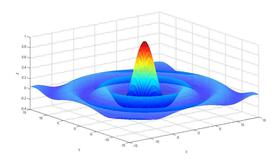
识别效果如图:
a.电子公式的识别,几乎100%的准确率。

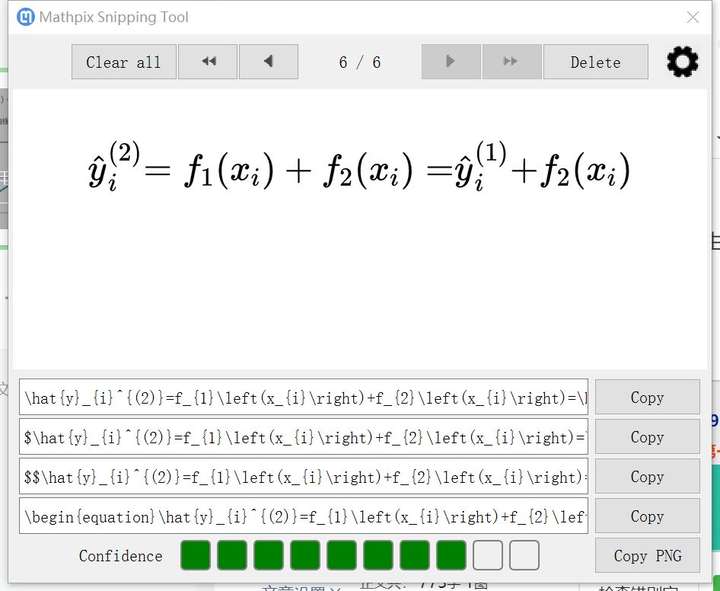
b.手写公式识别,只要字迹清楚,识别率非常高。
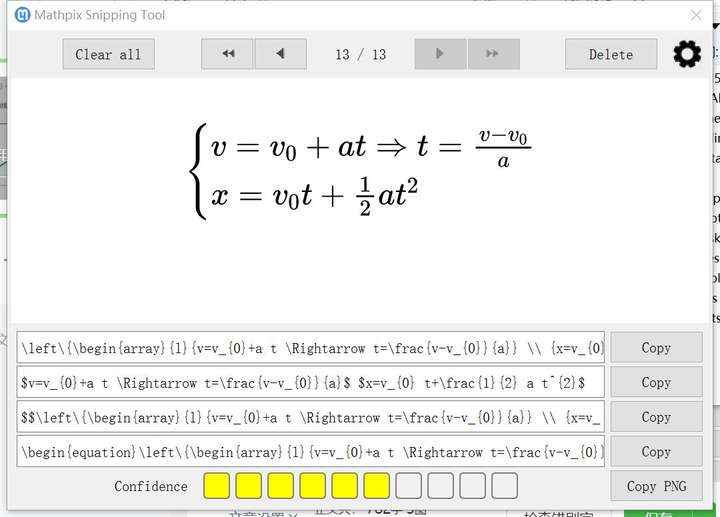
三、插入公式到文档
插入到word
第一步,需要安装mathtype插件(安装过程略,可以自行百度)。
第二步,从Mathpix Snip复制公式(复制第二行代码,即$代码$,点copy即可),光标点到输入公式的地方,直接粘贴,这个时候,word里面显示的还是tex代码($代码$这样的格式)。
第三步,使用mathtype的转换快捷键:
ALT+\
即可将tex代码转换为公式。
插入到markdown
打开typora,从Mathpix Snip复制公式(复制第三行代码,$$代码$$,点copy即可,如果单行公式,也可以复制$代码$),光标点到输入公式的地方,直接粘贴即可。效果如图:

插入到latex
从Mathpix Snip复制公式(复制第二行代码,即$代码$,点copy即可),光标点到输入公式的地方,直接粘贴
总结
有了Mathpix Snip这款神器,输入公式太方便了,大大提高了效率,可以方便转换图片的公式到word、markdown和latex文件,再也不用担心我的公式写不出来了。
=================================================
本人在写论文的时候,很多图片是用matplotlib和seaborn画的,但是,我还有一个神器,Scikit-plot,通过这个神器,画出了更加高大上的机器学习图,本文对Scikit-plot做下简单介绍。
安装说明
安装Scikit-plot非常简单,直接用命令:
pip install scikit-plot
即可完成安装。
仓库地址: https://github.com/reiinakano/scikit-plot
里面有使用说明和样例(py和ipynb格式)。
使用说明
简单举几个例子
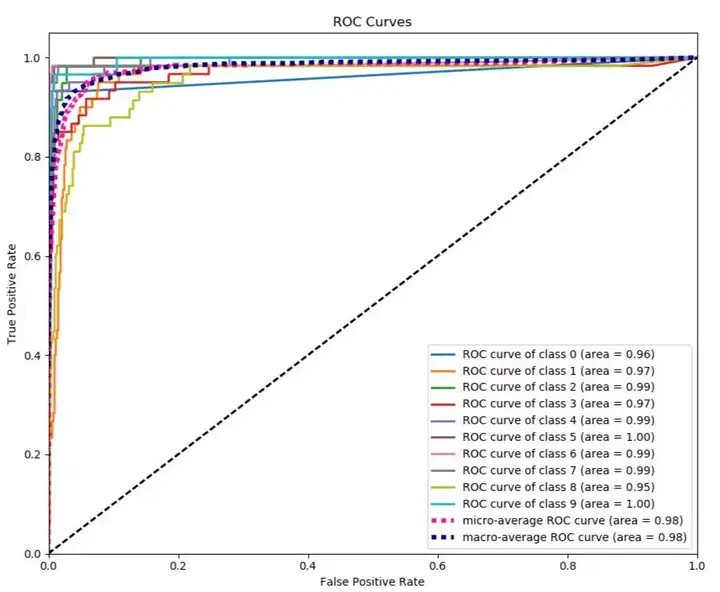
比如画出分类评级指标的ROC曲线的完整代码:
from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB X, y = load_digits(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) nb = GaussianNB() nb.fit(X_train, y_train) predicted_probas = nb.predict_proba(X_test) # The magic happens here import matplotlib.pyplot as plt import scikitplot as skplt skplt.metrics.plot_roc(y_test, predicted_probas) plt.show()
效果如图(相当高大上!)
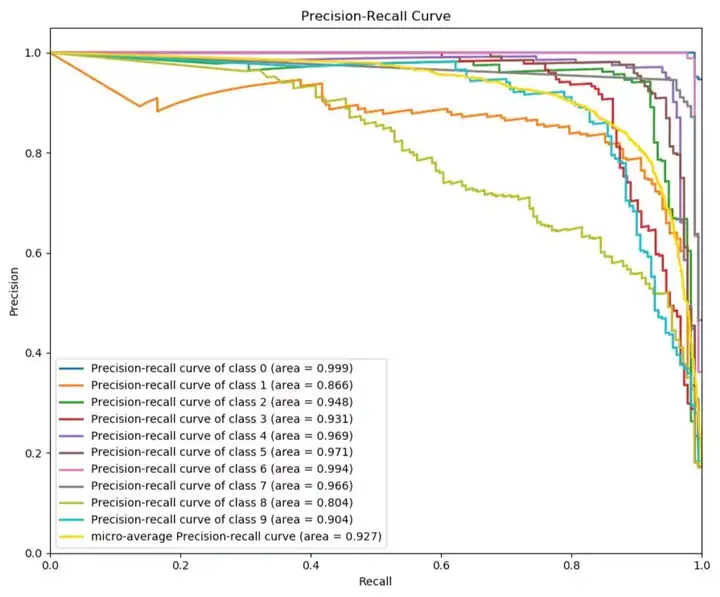
P-R曲线就是精确率precision vs 召回率recall 曲线,以recall作为横坐标轴,precision作为纵坐标轴。首先解释一下精确率和召回率。
import matplotlib.pyplot as plt from sklearn.naive_bayes import GaussianNB from sklearn.datasets import load_digits as load_data import scikitplot as skplt # Load dataset X, y = load_data(return_X_y=True) # Create classifier instance then fit nb = GaussianNB() nb.fit(X,y) # Get predicted probabilities y_probas = nb.predict_proba(X) skplt.metrics.plot_precision_recall_curve(y, y_probas, cmap='nipy_spectral') plt.show()
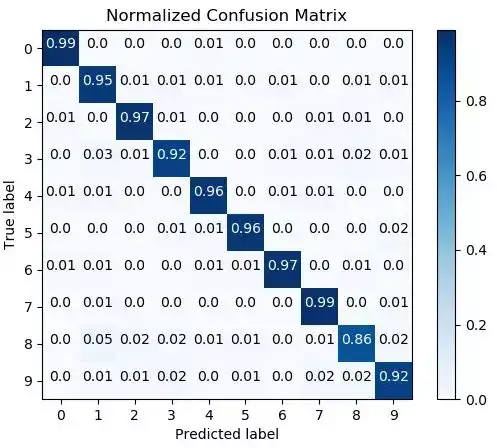
混淆矩阵是分类的重要评价标准,下面代码是用随机森林对鸢尾花数据集进行分类,分类结果画一个归一化的混淆矩阵。
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_digits as load_data from sklearn.model_selection import cross_val_predict import matplotlib.pyplot as plt import scikitplot as skplt X, y = load_data(return_X_y=True) # Create an instance of the RandomForestClassifier classifier = RandomForestClassifier() # Perform predictions predictions = cross_val_predict(classifier, X, y) plot = skplt.metrics.plot_confusion_matrix(y, predictions, normalize=True) plt.show()
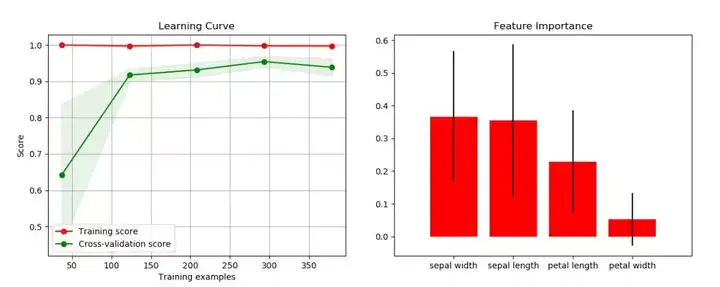
其他图如学习曲线、特征重要性、聚类的肘点等等,都可以用几行代码搞定。
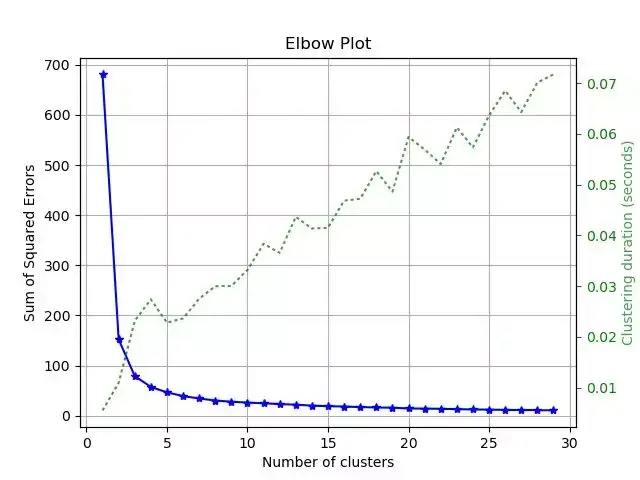
总结
本文对Scikit-plot做下简单介绍,这是一个机器学习的画图神器,几行代码就能画出高大上的机器学习图,作者当年的博士论文也是靠这个画图的。
仓库地址:https://github.com/reiinakano/scikit-plot
里面有使用说明和样例。
====================================================
本文我们聊聊如何才能画出炫酷高大上的神经网络图,下面是常用的几种工具。
作者&编辑 | 言有三
1 NN-SVG
这个工具可以非常方便的画出各种类型的图,是下面这位小哥哥开发的,来自于麻省理工学院弗兰克尔生物工程实验室, 该实验室开发可视化和机器学习工具用于分析生物数据。

github地址:https://github.com/zfrenchee
画图工具体验地址:http://alexlenail.me/NN-SVG/
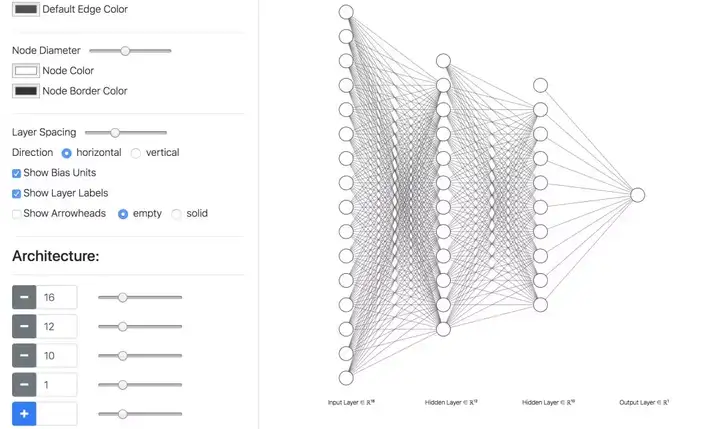
可以绘制的图包括以节点形式展示的FCNN style,这个特别适合传统的全连接神经网络的绘制。
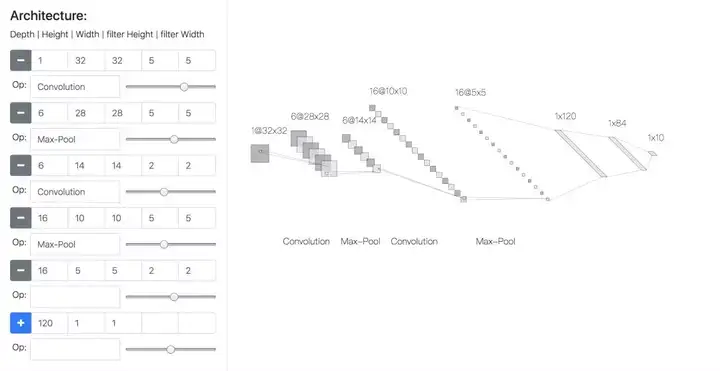
以平铺网络结构展示的LeNet style,用二维的方式,适合查看每一层featuremap的大小和通道数目。
以三维block形式展现的AlexNet style,可以更加真实地展示卷积过程中高维数据的尺度的变化,目前只支持卷积层和全连接层。
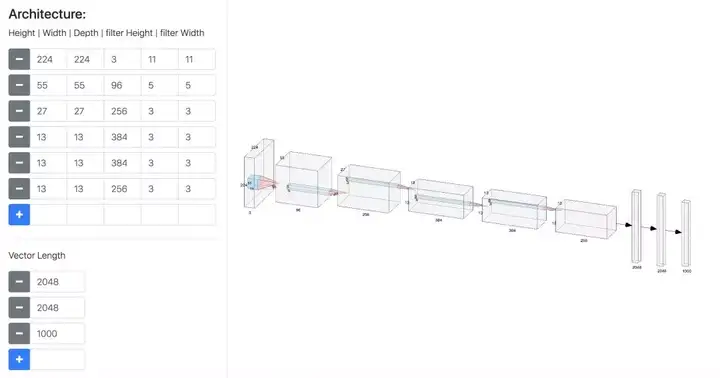
这个工具可以导出非常高清的SVG图,值得体验。
2 PlotNeuralNet
这个工具是萨尔大学计算机科学专业的一个学生开发的,一看就像计算机学院的嘛。

首先我们看看效果,其github链接如下,将近4000 star:
https://github.com/HarisIqbal88/PlotNeuralNet
看看人家这个fcn-8的可视化图,颜值奇高。
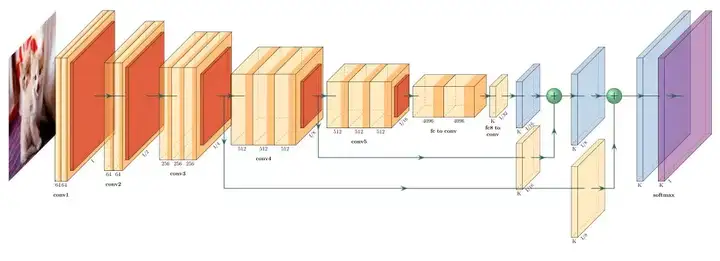
使用的门槛相对来说就高一些了,用LaTex语言编辑,所以可以发挥的空间就大了,你看下面这个softmax层,这就是会写代码的优势了。
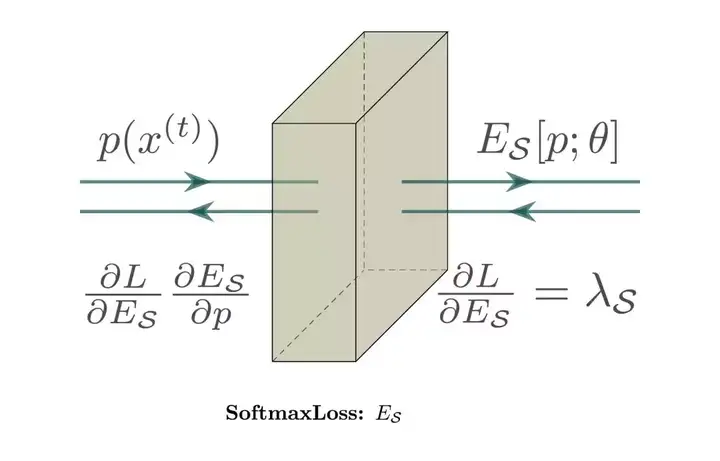
其中的一部分代码是这样的,会写吗。
\pic[shift={(0,0,0)}] at (0,0,0) {Box={name=crp1,caption=SoftmaxLoss: $E_\mathcal{S}$ ,%
fill={rgb:blue,1.5;red,3.5;green,3.5;white,5},opacity=0.5,height=20,width=7,depth=20}};相似的工具还有:https://github.com/jettan/tikz_cnn
3 ConvNetDraw
ConvNetDraw是一个使用配置命令的CNN神经网络画图工具,开发者是香港的一位程序员,Cédric cbovar。

采用如下的语法直接配置网络,可以简单调整x,y,z等3个维度,github链接如下:
https://cbovar.github.io/ConvNetDraw/
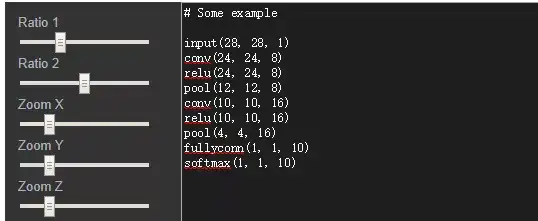
使用方法如上图所示,只需输入模型结构中各层的参数配置。
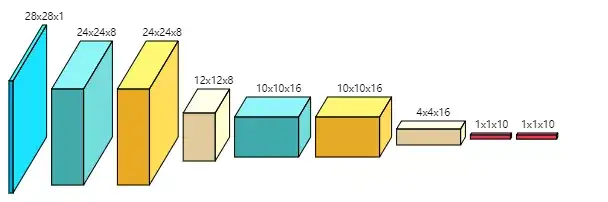
挺好用的不过它目标分辨率太低了,放大之后不清晰,达不到印刷的需求。
4 Draw_Convnet
这一个工具名叫draw_convnet,由Borealis公司的员工Gavin Weiguang Ding提供。

简单直接,是纯用python代码画图的,
https://github.com/gwding/draw_convnet
看看画的图如下,核心工具是matplotlib,图不酷炫,但是好在规规矩矩,可以严格控制,论文用挺合适的。
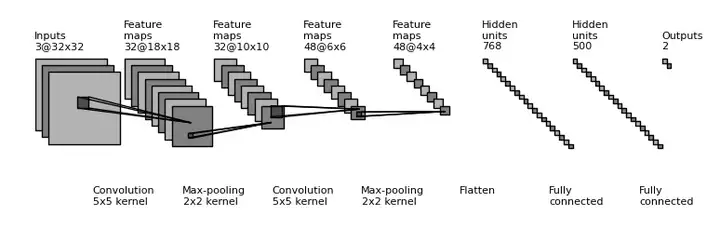
类似的工具还有:https://github.com/yu4u/convnet-drawer
5 Netscope
下面要说的是这个,我最常用的,caffe的网络结构可视化工具,大名鼎鼎的netscope,由斯坦福AILab的Saumitro Dasgupta开发,找不到照片就不放了,地址如下:
https://github.com/ethereon/netscope
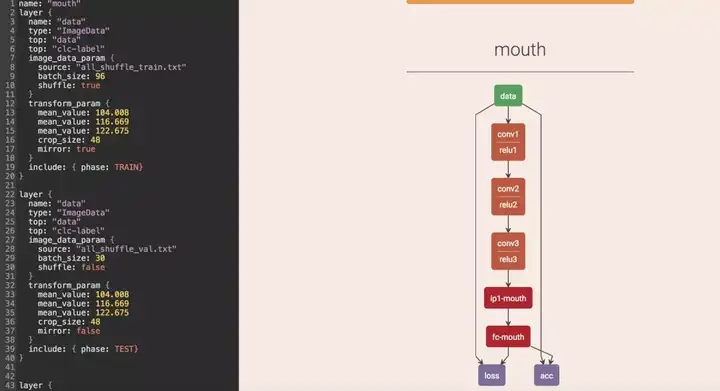
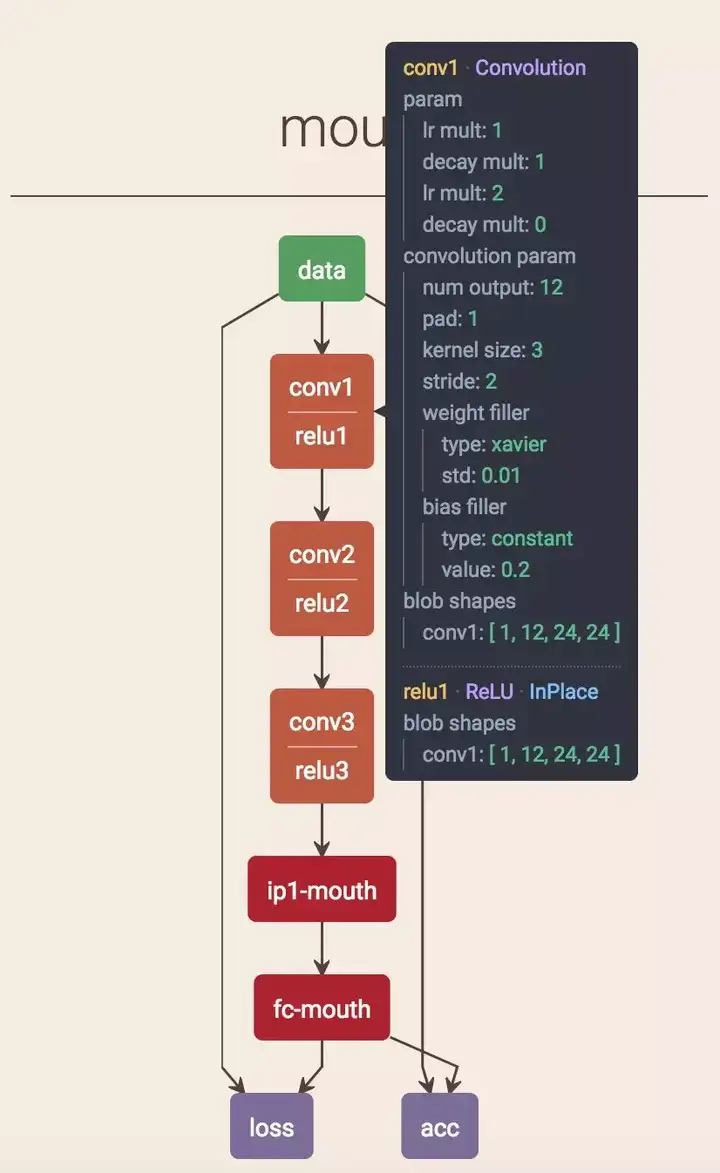
左边放配置文件,右边出图,非常方便进行网络参数的调整和可视化。这种方式好就好在各个网络层之间的连接非常的方便。
其他
再分享一个有意思的,不是画什么正经图,但是把权重都画出来了。
http://scs.ryerson.ca/~aharley/vis/conv/
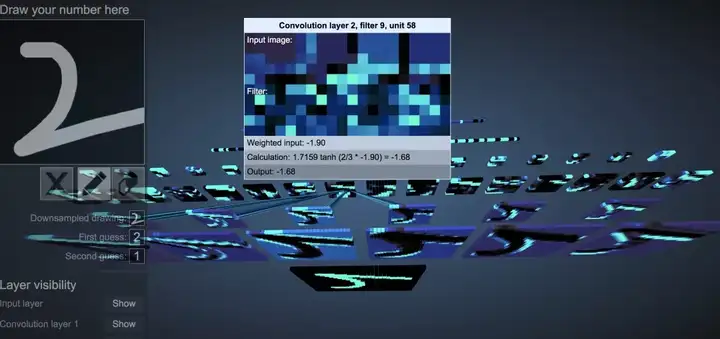

看了这么多,有人已经在偷偷笑了,上PPT呀,想要什么有什么,想怎么画就怎么画。
不过妹子呢?怎么不来开发一个粉色系的可视化工具呢?类似于这样的
总结
那么,你都用什么画呢?欢迎留言分享一下!
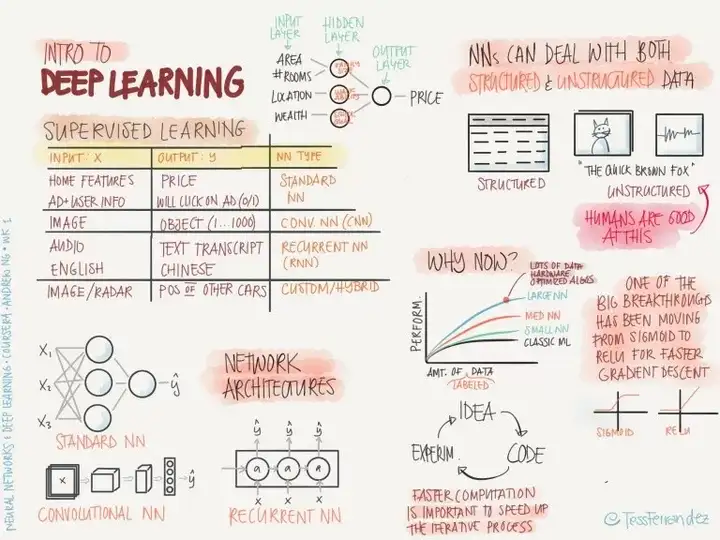
一、引言 Introduction
一个正常的研究人员每年得花上百小时读论文。所以学会高效读论文是一个至关重要的技能,但这项技能却很少提及。
刚刚入学的研究生,往往必须面对大量的教训和错误,浪费了很多时间,才能自发掌握读论文的方法。但不少人在掌握了方法之前就已经丧失读论文的动力。
而本文介绍的三遍法则可以:
避免在鸟瞰论文全貌前,被论文的细节淹没
估算review论文所需的时间
结合自己的空余时间和需要,调整论文评估的深度
那么,什么是三遍法呢?
顾名思义,其精髓就在于分三遍读论文,而不是从开头一直看到结尾。
每一遍阅读论文都有都有特定的目标,且建立在上一遍阅读的基础上:
第一遍,了解论文的主要思想(general idea)
第二遍,掌握论文的内容,不过也会忽略细节
第三遍,深入了解这篇论文
下面就开始具体地介绍一下三遍法~
二、第一遍(5步+5C)
第一遍通过“5步”+“5C”快速略读整篇论文,并获得论文的“鸟瞰图”。这也可以让自己决定是否继续精读这篇论文。
第一遍通常占用5到10分钟的时间,包含下面的5个步骤
仔细阅读 标题Title,摘要Abstract,以及引言Introduction
阅读所有章节和子章节的标题,忽略章节的内容
瞥一眼公式(如果有的话),确定论文的理论基础
读结论
瞥一眼引用文献,注意下有没有你读过的论文
(顺便一提,你可能发现了,这里并没有和其他人一样建议在第一步的时候就注意所有插图。)
在完成上面5步后,如果你能回答如下的5个"C",那么你的第一遍就算读到位了
1. Category(分类):这个论文的种类是什么?
论文是提出了什么新方法吗
还是说分析了现有的系统
或者描述了一个研究的原型?
2. Context(上下文):
本论文的相关论文是哪些?
论文基于何种理论分析了问题?
3. Correctness(正确性):
你觉得论文的假设靠谱不靠谱?
4. Contributions(贡献/创新)
这论文主要的贡献是什么?
5. Clarity(清晰度)
这论文写得怎么样,文笔好不好?
有了上面五个问题的答案,你可能就会枪毙一些不靠谱的论文(也不需要把它们打出来细看了,节约纸张,保护森林,拯救地球)。
不过我们枪毙的论文不一定是不靠谱,也有可能是我们对这个方向本身了解不深。不过嘛就算后面会被打脸,但大部分时候,对于非自己研究的领域第一遍筛选也足够了。
顺便说一句,自己写出的论文,大多审稿人(和读者)也可能只读第一遍。因此,要注意选择连贯的章节和小节标题,并写出简明全面的摘要。
如果审稿人看了一遍后还是不能理解文章的主旨,那么你的文章大概率凉了。
如果读者五分钟内不能理解文章的要点,那么他很可能失去接触你高深思想的机会。
出于这些原因,做一张精美的“图形摘要”是一个很好的主意。
三、第二遍(注释+总结观点与证据)
第二遍读论文就需要更多的关注,真的需要看正文了,不过诸如证明之类的细节也要暂时略过。
读第二遍的时候,在文章上做注释,在旁边空白处写一下自己的评论。换句话说,“记下你不理解的术语,还有那些你想问作者的问题”。如果你是个审稿人,那么写review的时候这些随手的笔记会帮上你。除了正文内容,还要注意:
仔细阅读论文中的各类图表。特别注意文中的图片的细节,比如坐标轴对不对。这些细节错误往往能区分粗制滥造与真正杰出的工作。
标记一些有关但你没读过的参考文献,之后补一补(这对了解论文的背景很有用处)
第二遍会耗费一个有经验读者至多一个小时的时间。第二遍过后,你应该能掌握文章的主要内容,并给他人总结文章的主要观点,以及观点的支撑证据。
读完第二遍,对于你感兴趣的论文也足够了。不过如果你就要研究它的话还得再看第三遍。
有时第二遍论文看完了之后依然搞不懂文章内容,这可能是因为论文主题对自己比较新,有一些不熟的术语和缩写。也有可能作者用了些你不懂的证明或者实验上的骚操作。也有可能这个论文本身写作水平很差,有一堆拍脑袋的断言和乱七八糟的引用。这个时候,你可以:
把这篇论文扔到一边,并祈祷没有它你的科研也会顺利
之后再读这篇论文,比如在学习这篇论文的背景知识
头铁来看接下来的第三遍
四、第三遍(脑内复现)
为了完全掌握一篇论文,特别是作为一个审稿人,你还得看第三遍。第三遍的关键在于你需要 脑内复现(virtually re-implement) 这篇论文,也就是说,和作者做相同的假设,并且重新创作出这篇论文的工作。这样,不仅论文的创新点,就连隐藏的假设和缺陷都可以简单地认识到。
这一遍需要对细节给予很大的关注。你应该发现并且质疑每一段语句中的每一个假设。除此之外,也要考虑如果是自己,该如何去展示这个idea。这种真实论文与脑内论文的对比可以深刻思考论文中的证明与展示方法,并且久而久之总会有些不错的内容扩展到自己的独门秘籍里(即通过比较自己“脑补”的论文,发现别人“写论文”的诀窍并学习)。
别忘了,第三遍阅读的时候,还应该记下未来工作的想法。
这一遍可能需要花费一个初学者好多小时的时间,甚至对有经验的读者也需要1~2小时(以上)。在读完这一轮之后,读者应该可以在回忆中重构整个论文的结构,也可以去辨别论文的优势和不足的点。特别是可以指出论文中不严谨的假设,漏掉的引用和实验/分析上的潜在问题。
Ex 运用:写文献综述吧
论文阅读的技巧可以在做文献综述中体现到。文献综述需要你读数十篇论文,而且很可能是对一个未知领域的数十篇论文。如果已经知道怎么读论文了,那么下个问题就是该读哪些论文?
第一步:首先,去类似Google Scholar这样的平台,输入合适的关键词,去找该领域3~5篇最近高被引的论文。对每篇论文读第一遍,获得一个大体的感觉,之后读一读他们“有关工作related work”的章节。这章节就是最近工作一个袖珍的summary,并且如果你足够幸运,章节里甚至会有些不错的综述文献。
如果没找到综述,那么进行第二步;否则结合综述文献跳转第三步。
第二步:自行留意多次引用的论文名或者重复的作者名,这些通常都是这个领域中最关键的论文和大佬,看看这些大佬最近还发了啥。(这也能告诉你这个领域的顶会,因为大佬通常只发顶会)
第三步:去看看这些顶会的官网,看看最近的前沿进展。在快速略览时就可以找到最近高质量的相关工作。这些论文,以及你之前放一边的那些论文,就可以撑起来第一个版本的survey。把这些论文按照之前说的看两遍,如果这些论文引用了你没见过的关键论文,那就下下来读,必要时这样迭代着读。

