-
1 视频
-
2 章节测验
通过基于“儒家德性样板库”的隐喻性投射来获取德性
在前节中我们已经看到,丘奇兰德将德性伦理学“自然主义化”的要旨,便是通过神经计算模型来对道德刺激进行逐步抽象,并根据抽象的结果来对抽象进程进行反馈,由此使得系统获得正确的“抽象习惯”——此即“德性”。虽然我们已经知道了这种“逐层抽象”的技术思路是很难被运用到儒家德性训练的实际案例上去的,但至少就“通过特定训练样本形成某种具有规范性的推理习惯”这一大思路而言,我们依然可以在某个更恰当的技术平台上对其予以保留。依据笔者浅见,儒家人物评价模式对于隐喻式修辞的高度依赖,正好为构建上述这种“更恰当的技术平台”提供启发。譬如,我们可以按照这样的路线图来构建这种平台:
第一步:人类程序员通过史料阅读,手动建立一个“儒家德性样板语料库”,而每一个语例都要按照如下格式标注各种参数的值:(甲)人名;(乙)典型事迹集;(丙)对每一典型事件背后当事人的道德决策进程进行心理重构;(丁)对每一典型事件进行整体上的道德价值词标注;(戊)对于该人物的总体德性评价。在整个“步骤一”中,对于环节(丙)中数据的采集可能是最为困难的,因为当事人的心理活动与道德决策过程往往是很难在事后被复原的。比较合理的处理方法是罗列出史料所记载的当事人面对特定任务时所需要满足的所有目标,然后根据他对于这些目标的实际取舍,反推出这些目标在其内部心理评价系统中的排位。而在环节(丁)中,我们将根据“击靶德性论”的精神,对每一事迹的成败给出价值评分,尔后再结合环节(丙)所给出的对于行为者意图的描述,构成某种综合评分(其综合标准是:“击靶”未成功的邪恶意图的综合道德评分会被拉高,而“击靶”未成功的善良意图的综合道德评分则会被降低,依此类推)。至于环节(戊)所涉及的对于人物德性的总体评价,则是对在环节(丁)中所出现的大量道德评注进行统计学抽象后的结果。此外,还需要读者注意的是,本步骤所涉及的“儒家德性样板语料库”反映的虽然是传统官方史书对于历史人物评价的一般性意见,但我们并不试图假定此库中的所有参数设置会具有贯彻全库的逻辑自洽性。与这种宽容相对应,我们亦允许数据库营建方根据新资料对这个数据库进行修正与扩容。因此,这样的数据库便不会在任何意义上构成一个“公理系统”。请参看图—3。
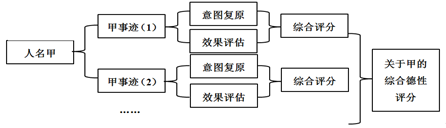
图—3 儒家德性样板库的建立(上)
第二步:系统必须对数据库信息进行自行整合,即在标注为“与当事人甲相关”的数据集与标注为“与当事人乙相关”的数据集的各个下属参数之间进行相似度计算。在理想情况下,一个已经具有强大类比推理性能的计算系统,将有能力自行在“齐桓公宽恕曾用箭射过他的管仲”与“汉高祖宽恕曾为项羽效过力的季布”这两个事例之间找到相关性,尽管这两个事例本来是属于两个不同的数据集的。由此,系统会自行形成与“宽恕”这种行为相关的典型语例集,由此构成对于以人名为核心词的语例集的二阶表征。请参看图—4。
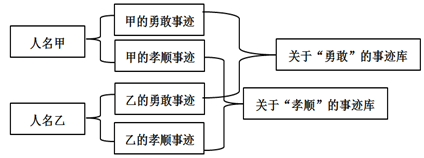
图—4 儒家德性样板库的建立(下)
第三步:向系统“喂入”一个新的虚拟道德情境,要求系统:(甲)通过类比思维方式,在前述“儒家德性样板语料库”的“一阶语例集”与“二阶语例集”中搜寻到特定的子集,并在这些子集与当下案例之间建立特定的隐喻投射关系;(乙)将语例库中的道德问题求解方案投射到当下案例中;(丙)给出问题的求解方案。
第四步:系统的“高层次评估模块”会对上述步骤所给出的求解方案进行评估,若其得分合格,则完成本轮训练,给出下一个道德案例进行深化训练;若得分不合格,则驱动系统重启“步骤三”,直到给出的解答符合评估要求。
第五步:经过上述步骤而完成了大量道德案例训练的系统,其实已经具备了以恰当的方式将新的道德情境要素与道德样本库中的相关因素加以联系的能力,也就是建立恰当的道德隐喻投射关系的能力。我们可以认为:具备这种能力的系统已经具备了最初步的“德性”。
第六步:经过更长且更复杂的运行历史的此类系统,为了节省内部运作资源,将从自身处理特定问题的内部经验出发来面对新的道德情境,而不再大规模地求助于儒家道德样本语料库中的信息。这样的系统也可以被视为是某种具有较为完整的德性(full-fledged virtue)的人工道德推理系统。
以上技术路线的实现,显然取决于对于合适的计算平台的选择。具体而言,这样的计算平台显然要具备对于自然语言的强大编码能力,以及对于类比思维的强大表征能力。同时,它还不能是任何一种意义上的基于公理集的封闭式推理系统,否则它就无法对应儒式道德推理的开放性与对于语境因素的敏感性。若说得再技术化一点,这样的计算平台应当能够像传统的亚里士多德式逻辑那样,支持某种基于“词项”的推理——因为对于类比—隐喻推理的表征任务而言,经由“本体与喻体对于某个间接词项的分享”来建立恰当的推理路径,其实是一条最经济的技术路线。而正如我们所看到的,神经计算模型是无法满足这些技术需求的,因为此类模型只能完成对于繁杂数据的识别任务,而无法在语义水平上直接进行逻辑推理。而基于公理系统的传统符号人工智能的进路,同样无法胜任我们在此所给出的任务,因为这样的技术进路在面对含糊、开放、易受语境因素影响的类比推理任务时,表现往往很拙劣——而更重要的是,此类技术进路对于弗雷格式现代逻辑的依赖,使得其无法像词项逻辑推理系统那样规避所谓“框架问题”。
目下在全球范围内,最可能将笔者所构想的“儒式德性训练模型”予以算法化的计算平台,乃是由美国天普大学(Temple University)的计算机科学家王培先生发明的“纳思系统”所提供的。纳思系统的英文全称为“Non-AxiomaticReasoning System”(非公理推理系统),“NARS”为其缩写,“纳思”为该缩写的汉语音译。大体而言,纳思系统乃是一个具有通用用途的计算机推理系统,而且在如下意义上与传统的推理系统有所分别:纳思系统能够对其过去的经验加以学习,并能够在资源约束的条件下对给定的问题进行实时解答。从技术角度看,纳思系统是由诸多层次的技术构建构成的,每个层次均有其自身的推理规则,而这些规则又都基于作为一种新词项逻辑的“纳思式逻辑”。整个系统之所以被说成是“非公理的”,则是得缘于如下理由:尽管系统的构造者会在一开始为系统的每个层次预先设置一些推理规则,但他既不会将整个系统的知识库锁死,也不赋予知识库中的任何一个命题以公理的形式。毋宁说,纳思自身的知识库是可以随着系统的经验的增加而被不断修正和丰富的。也正是在这个意义上,纳思的知识表征进路在实质上便是不同于丘奇兰德所推崇的神经计算模型以及传统人工智能研究所推崇的符号规则进路的,因为后二者均要求系统一开始就获得关于环境的充分知识。由是观之,纳思进路颇有孔子所说的“君子不器”的品格,并天然与儒式推理方式相亲近。当然,若我们真要着手经由纳思技术平台来构建本节所描述的儒式德性训练模型的话,由此所牵涉到的大量技术性讨论,恐怕是不能为这篇小文所包容的。有兴趣的读者可参看笔者经由纳思系统重构许慎“六书”构字理论的其它理论尝试,因为这些尝试所涉及到的诸多技术细节,对于德性训练模型的营建来说也是通用的。

