
-
1 知识要点
-
2 知识测试
-
3 主题讨论
1.1 初识大数据
随着近几年计算机技术和互联网的发展,“大数据”这个词被提及的越来越频繁。与此同时,大数据的快速发展也在无时无刻影响着我们的生活。例如,医疗方面,大数据能够帮助医生预测疾病;电商方面,大数据能够向顾客个性化推荐商品;交通方面,大数据会帮助人们选择最佳出行方案。
Hadoop作为一个能够对大量数据进行分布式处理的软件框架,用户可以利用Hadoop生态体系开发和处理海量数据。由于Hadoop有可靠及高效的处理性能,使得它逐渐成为分析大数据的领先平台。
1.1.1 什么是大数据
最早提出“大数据”这一概念的是全球知名咨询公司麦肯锡,他是这样定义大数据的:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度四大特征。
研究机构Gartner是这样定义大数据的:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流转优化能力来适应海量、高增长率和多样化的信息资产。
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
1.1.2 大数据的特征
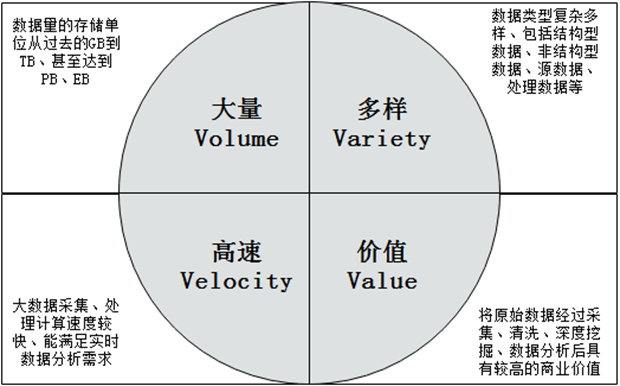
大数据主要具有以下四个方面的典型特征,即大量(Volume)、多样(Varity)、高速(Velocity)和价值(Value),即所谓的“4V”。
1.1.3 研究大数据的意义
有人把数据比喻为蕴藏能量的煤矿。煤炭按照性质有焦煤、无烟煤、肥煤、贫煤等分类,而露天煤矿、深山煤矿的挖掘成本又不一样。与此类似,大数据并不在于“大”,而在于“有用”。数据的价值含量、挖掘成本比数量更为重要。对于很多行业而言,如何利用这些大规模数据,发掘其潜在价值,才是赢得核心竞争力的关键。
研究大数据,最重要的意义是预测。因为数据从根本上讲,是对过去和现在的归纳和总结,其本身不具备趋势和方向性的特征,但是我们可以应用大数据去了解事物发展的客观规律、了解人类行为,并且能够帮助我们改变过去的思维方式,建立新的数据思维模型,从而对未来进行预测和推测。知名互联网公司谷歌对其用户每天频繁搜索的词汇进行数据挖掘,从而进行相关的广告推广和商业研究。

