-
1 知识要点
-
2 知识测试
-
3 主题讨论
2.1 安装准备
“磨刀不误砍柴工”,要想深入学习和掌握Hadoop的相关应用,首先必须得学会搭建一个属于自己的Hadoop集群。
2.1.1虚拟机安装
2.1.2虚拟机克隆
链接克隆:需要和原始虚拟机共享同一虚拟磁盘文件,不能脱离原始虚拟机独立运行。但是采用共享磁盘文件可以极大缩短创建克隆虚拟机的时间,同时还节省物理磁盘空间。
完整克隆:是对原始虚拟机完全独立的一个拷贝,它不和原始虚拟机共享任何资源,可以脱离原始虚拟机独立使用。
2.1.3Linux系统网络配置
1.主机名和IP映射配置
(1)配置主机名,具体指令如下。
$ vi /etc/sysconfig/network
(2)查看IP地址可选范围,并配置IP映射
2. 网络参数配置
(1)配置网卡设备的Mac地址。
(2)配置静态IP地址
(3)配置效果验证
2.1.4SSH服务配置
实际工作中,服务器被放置在机房中,同时受到地域和管理的限制,开发人员通常不会进入机房操作直接上机操作,而是通过远程连接服务器,进行相关操作。
在集群开发中,主节点通常会对集群中各个节点频繁的访问,就需要不断输入目标服务器的用户名和密码,这种操作方式非常麻烦并且还会影响集群服务的连续运行。
为了解决上述问题,我们可以通过配置SSH服务来实现远程登录和SSH的免密登录功能。
1. SSH远程登录功能配置
(1)安装并开启SSH服务。
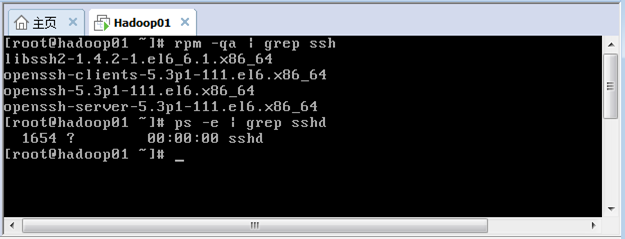
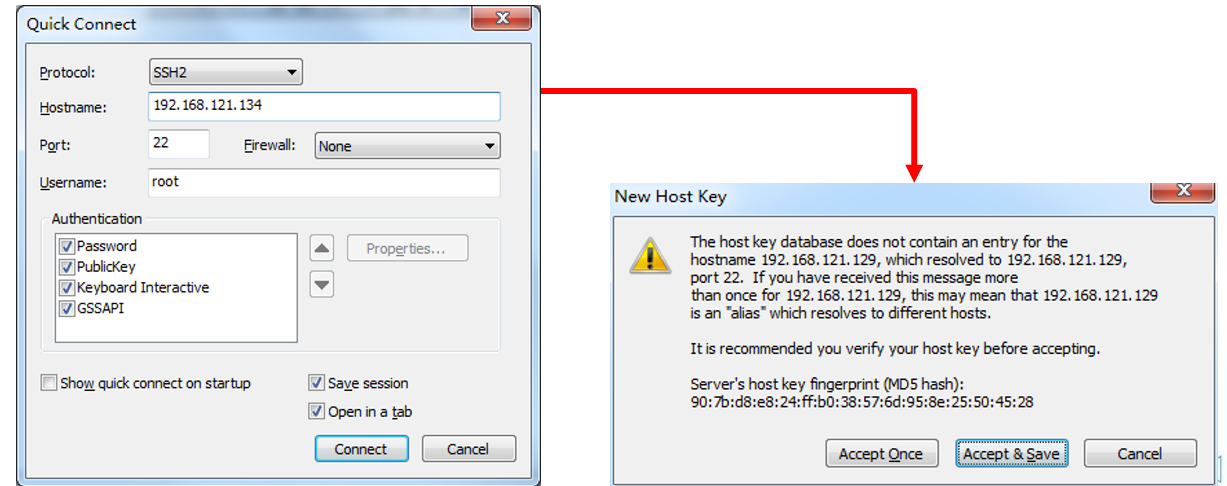
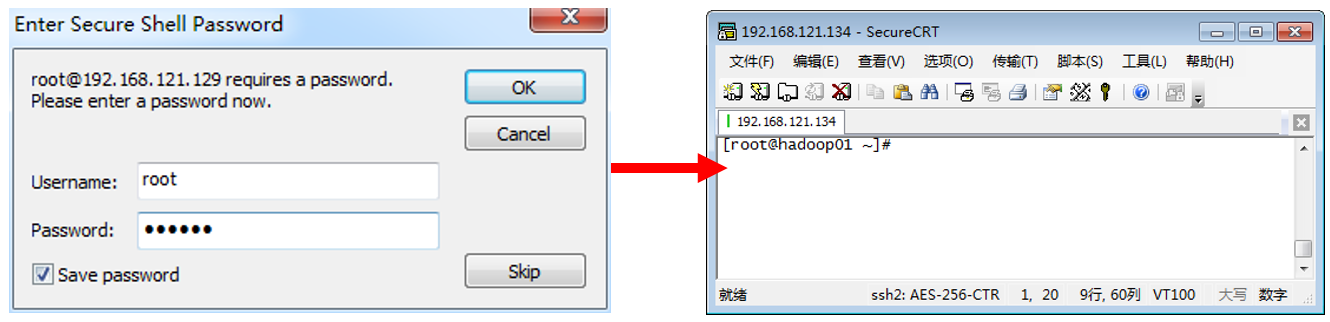
(2)创建CRT工具和服务器hadoop01的快速连接
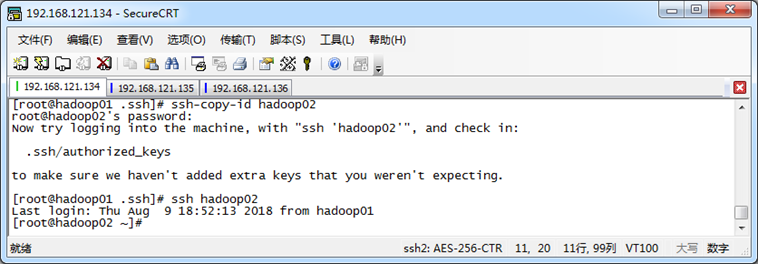
2. SSH免密登录功能配置
(1)生成SSH文件
用命令ssh-keygen -t rsa 生成 SSH文件

参数 -t rsa 表示使用rsa算法进行加密,执行后,会在当前用户家目录/.ssh目录下找到id_rsa(私钥)和id_rsa.pub(公钥)
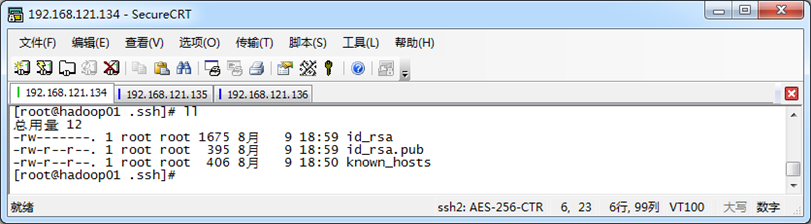
(2)配置免密登录hadoop02虚拟机,并验证免密登录效果