
2.3 Hadoop集群测试
2.3.1 格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理。
格式化文件系统指令如下:
$ hdfsnamenode-format
$ hadoopnamenode -format
2.3.2 启动和关闭Hadoop集群
针对Hadoop集群的启动,需要启动内部包含的HDFS集群和YARN集群两个集群框架。启动方式有两种:一种是单节点逐个启动;另一种是使用脚本一键启动。
1. 单节点逐个启动和关闭
(1)在主节点上执行指令启动/关闭HDFS NameNode进程;
(2)在每个从节点上执行指令启动/关闭HDFS DataNode进程;
(3)在主节点上执行指令启动/关闭YARN ResourceManager进程;
(4)在每个从节点上执行指令启动/关闭YARN nodemanager进程;
(5)在节点hadoop02执行指令启动/关闭SecondaryNameNode进程
2. 脚本一键启动和关闭
(1)在主节点hadoop01上执行指令“start-dfs.sh”或“stop-dfs.sh”启动/关闭所有HDFS服务进程;
(2)在主节点hadoop01上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;
(3)在主节点hadoop01上执行“start-all.sh”或“stop-all.sh”指令,直接启动/关闭整个Hadoop集群服务
3. Hadoop测试效果
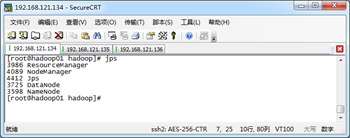
Hadoop集群服务启动后,在各个机器上执行“jps”指令查看各节点的服务进程的启动情况,效果如下所示。
2.3.3 通过UI界面查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了两个端口50070和8088,分别用于监控HDFS集群和YARN集群。通过UI界面可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
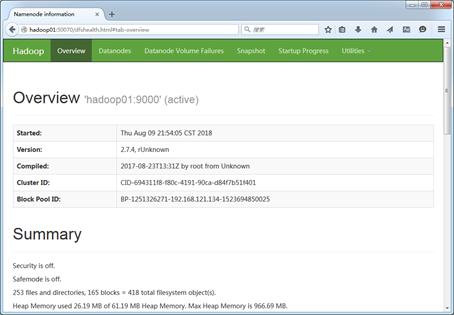
在Windows系统下,访问http://hadoop01:50070,查看HDFS集群状态,且从图中可以看出HDFS集群状态显示正常。
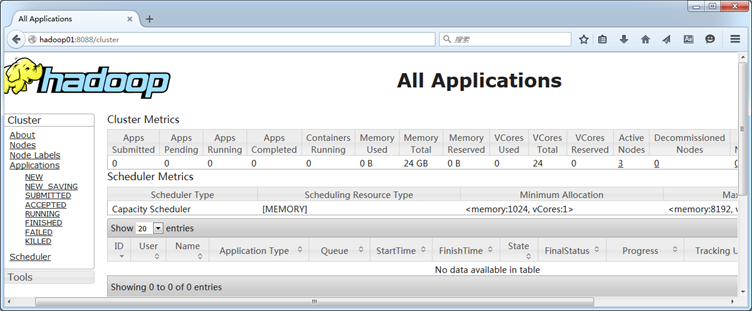
在Windows系统下,访问http://hadoop01:8088,查看Yarn集群状态,且从图中可以看出Yarn集群状态显示正常。
2.3.4 Hadoop经典案例——单词统计
打开HDFS的UI界面,查看HDFS中是否有数据文件,默认是没有数据文件。
准备文本文件,在Linux系统上编辑一个文本文件,然后上传至HDFS上。
运行hadoop-mapreduce-examples-2.7.4.jar包,实现词频统计。
查看UI界面,Yarn集群UI界面出现程序运行成功的信息。HDFS集群UI界面出现了结果文件。

