MapReduce概述
上一节
下一节
4.1 MapReduce概述
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
4.1.1 MapReduce核心思想
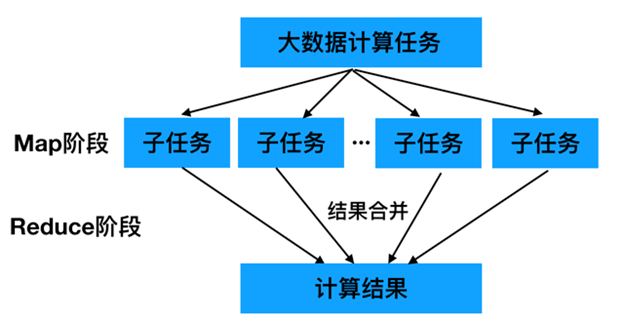
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。
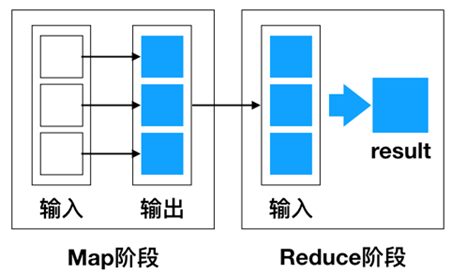
MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
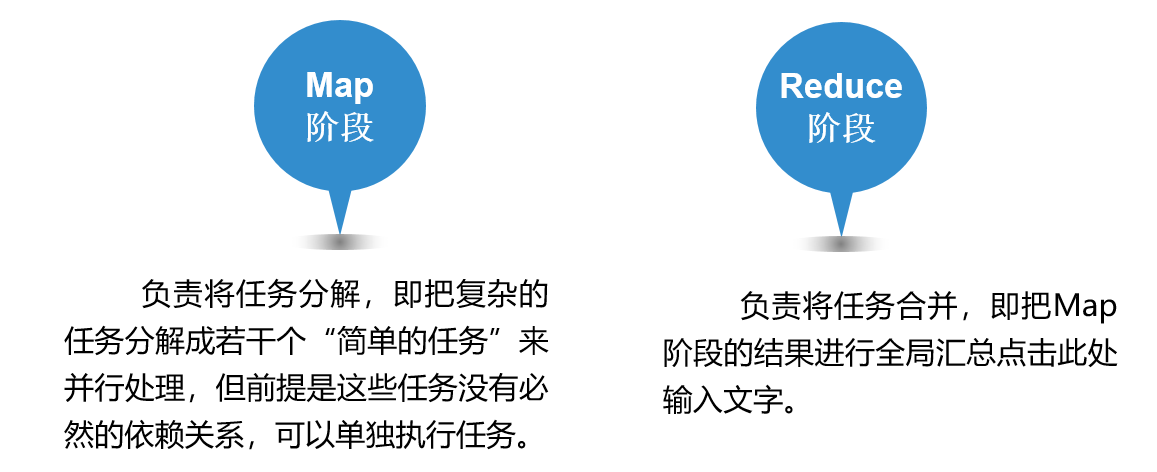
MapReduce就是“任务的分解与结果的汇总”。即使用户不懂分布式计算框架的内部运行机制,但是只要能用Map和Reduce思想描述清楚要处理的问题,就能轻松地在Hadoop集群上实现分布式计算功能。
4.1.2 MapReduce编程模型
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果。