
什么是大数据
高速发展的信息时代,新一轮科技革命和变革正在加速推进,技术创新日益成为重塑经济发展模式和促进经济增长的重要驱动力量,而“大数据”无疑是核心推动力。
那么,什么是“大数据”呢?如果从字面意思来看,大数据指的是巨量数据。那么可能有人会问,多大量级的数据才叫大数据?不同的机构或学者有不同的理解,难以有一个非常定量的定义,只能说,大数据的计量单位已经越过TB级别发展到PB、EB、ZB、YB甚至BB来衡量。
最早提出“大数据”这一概念的是全球知名咨询公司麦肯锡,他是这样定义大数据的:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度四大特征。
研究机构Gartner是这样定义大数据的:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流转优化能力来适应海量、高增长率和多样化的信息资产。
大数据主要具有以下四个方面的典型特征,即大量(Volume)、多样(Varity)、高速(Velocity)和价值(Value),即所谓的“4V”。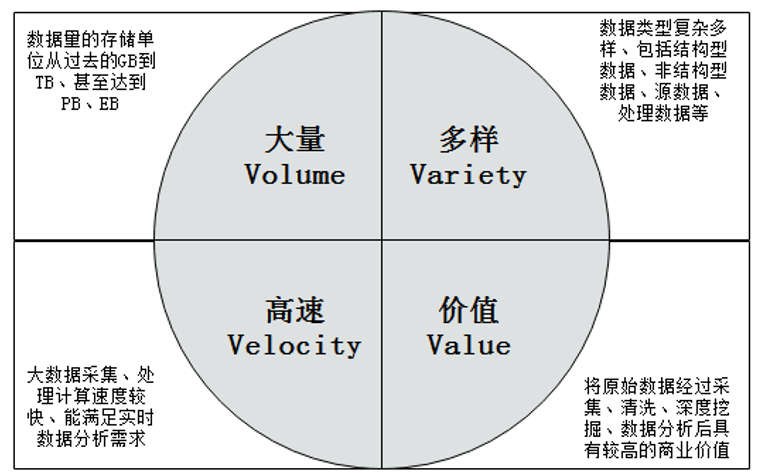
研究大数据的意义
现在的社会是一个高速发展的社会,科技发达,信息流通,人们之间的交流也越来越密切,生活也越来越便捷,然而大数据就是这个高科技时代的产物。阿里巴巴的创办人马云曾经说过,未来的时代将不是IT时代,而是DT的时代,DT就是Data Technology数据科技,这显示出大数据对于阿里巴巴集团来说是举足轻重的。
有人把数据比喻为蕴藏能量的煤矿。煤炭按照性质有焦煤、无烟煤、肥煤、贫煤等分类,而露天煤矿、深山煤矿的挖掘成本又不一样。与此类似,大数据并不在于“大”,而在于“有用”。数据的价值含量、挖掘成本比数量更为重要。对于很多行业而言,如何利用这些大规模数据,发掘其潜在价值,才是赢得核心竞争力的关键。
研究大数据,最重要的意义是预测。因为数据从根本上讲,是对过去和现在的归纳和总结,其本身不具备趋势和方向性的特征,但是我们可以应用大数据去了解事物发展的客观规律、了解人类行为,并且能够帮助我们改变过去的思维方式,建立新的数据思维模型,从而对未来进行预测和推测。知名互联网公司谷歌对其用户每天频繁搜索的词汇进行数据挖掘,从而进行相关的广告推广和商业研究。

