
1、下载安装包
2、上传压缩包至hadoop目录
mkdir /hadoop
cd /hadoop
使用xftp上传安装包
3、解压
tar -xzf hadoop-3.3.1.tar.gz
4、配置core-site.xml,在configuration中添加以下内容
(1)创建存放数据的目录文件夹mkdir /hadoop/hadoopdata
(2)vi /hadoop/hadoop-3.3.1/etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/hadoop/hadoopdata</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
5、配置hdfs-site.xml,在configuration中添加以下内容
vi /hadoop/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hadoopdata/dfs/data</value>
</property>
6、配置hadoop-env.sh
使用$JAVA_HOME获取jdk安装路径,复制安装路径到hadoop-env.sh中的JAVA_HOME
vi /hadoop/hadoop-3.3.1/etc/hadoop/hadoop-env.sh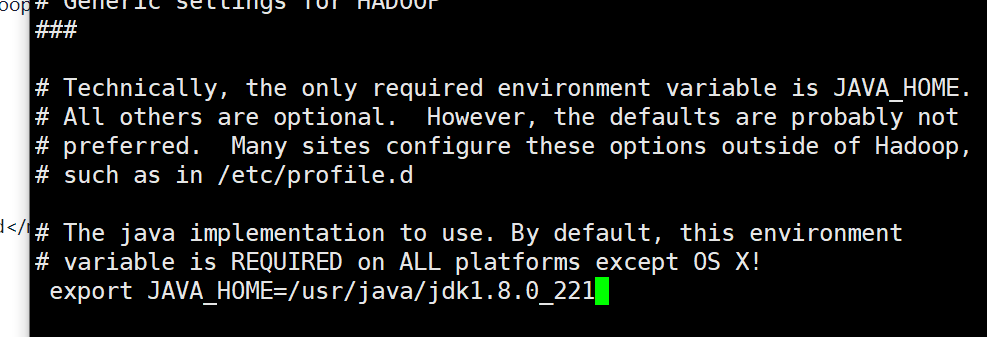
7、配置yarn-site.xml,在configuration中添加以下内容
vi /hadoop/hadoop-3.3.1/etc/hadoop/yarn-site.xml
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
8、配置环境变量
vi /etc/profile
添加以下内容:
export HADOOP_HOME=/hadoop/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
执行环境变量立即生效 source /etc/profile
9、设置免密登录
ssh-copy-id master
10、启动hadoop伪分布式
hdfs namenode -format
start-dfs.sh

