

Python的设计目标之一是让代码具备高度的可阅读性。它设计时尽量使用其它语言经常使用的标点符号和英文单字,让代码看起来整洁美观。它不像其他的静态语言如C、Pascal那样需要重复书写声明语句,也不像它们的语法那样经常有特殊情况和意外。
Python开发者有意让违反了缩进规则的程序不能通过编译,以此来强制程序员养成良好的编程习惯。并且Python语言利用缩进表示语句块的开始和退出(Off-side规则),而非使用花括号或者某种关键字。增加缩进表示语句块的开始,而减少缩进则表示语句块的退出。缩进成为了语法的一部分。例如if语句:python3
1 2 3 4 5 | #输入输出条件示例 age1 = input("请输入你的年龄: ") age = int(age1) if age < 21: print("你不能买酒。") print("不过你能买口香糖。") print("这句话在if语句块的外面!") |
根据PEP的规定,必须使用4个空格来表示每级缩进(不清楚4个空格的规定如何,在实际编写中可以自定义空格数,但是要满足每级缩进间空格数相等)。使用Tab字符和其它数目的空格虽然都可以编译通过,但不符合编码规范。支持Tab字符和其它数目的空格仅仅是为兼容很旧的的Python程序和某些有问题的编辑程序。
Python 标识符
简单地理解,标识符就是一个名字,就好像我们每个人都有属于自己的名字,它的主要作用就是作为变量、函数、类、模块以及其他对象的名称。
Python 中标识符的命名不是随意的,而是要遵守一定的命令规则。Python 的标识符是由字符(A~Z 和 a~z)、下划线(_)和数字组成,但第一个字符不能是数字。
标识符不能和 Python 中的保留字相同。有关保留字,后续会介绍。
Python中的标识符中,不能包含空格、@、% 以及 $ 等特殊字符。
Python 中的标识符是区分大小写的。
以下划线开头的标识符是有特殊意义的。以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入。
以双下划线开头的 __foo 代表类的私有成员,以双下划线开头和结尾的 __foo__ 代表 Python 里特殊方法专用的标识,如 __init__() 代表类的构造函数。
Python 可以同一行显示多条语句,方法是用分号 ; 分开,如:
>>> print ('hello');print ('runoob');
hello
runoob
Python 保留字
下面的列表显示了在Python中的保留字。这些保留字不能用作常数或变数,或任何其他标识符名称。
所有 Python 的关键字只包含小写字母。
| and | exec | not |
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和缩进
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
# py101.py 示例程序:从键盘输入两个数a、b,若a,b两数相等,
# 则 输出“两数相等!”,否则输出“两数不等!”
a = input("a= ")
b = input("b= ")
if a==b:
print("两数相等!")
else:
print("两数不等!")
print(" python 示例程序运行结束,BYE!")
以下实例缩进为四个空格:
实例
if True:
print ("True")
else:
print ("False")
以下代码将会执行错误:
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
# 没有严格缩进,在执行时会报错
print ("False")
执行以上代码,会出现如下错误提醒:
File "test.py", line 11
print ("False")
^
IndentationError: unindent does not match any outer indentation levelIndentationError: unindent does not match any outer indentation level错误表明,你使用的缩进方式不一致,有的是 tab 键缩进,有的是空格缩进,改为一致即可。
如果是 IndentationError: unexpected indent 错误, 则 python 编译器是在告诉你"Hi,老兄,你的文件里格式不对了,可能是tab和空格没对齐的问题",所有 python 对格式要求非常严格。
因此,在 Python 的代码块中必须使用相同数目的行首缩进空格数。
建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用
多行语句
Python语句中一般以新行作为语句的结束符。
但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:
total = item_one + \ item_two + \ item_three
语句中包含 [], {} 或 () 括号就不需要使用多行连接符。如下实例:
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
Python 引号
Python 可以使用引号( ' )、双引号( " )、三引号( ''' 或 """ ) 来表示字符串,引号的开始与结束必须是相同类型的。
其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。
word = 'word' sentence = "这是一个句子。" paragraph = """这是一个段落。 包含了多个语句"""
Python注释
python中单行注释采用 # 开头。
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
# 第一个注释
print ("Hello, Python!") # 第二个注释
输出结果:
Hello, Python!
注释可以在语句或表达式行末:
name = "Madisetti" # 这是一个注释
python 中多行注释使用三个单引号(''')或三个双引号(""")。
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
'''
这是多行注释,使用单引号。
这是多行注释,使用单引号。
这是多行注释,使用单引号。
'''
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
Python空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
下面的程序执行后就会等待用户输入,按回车键后就会退出:
#py103.py
def sound(): #发出 "嘟" 声音的函数
import winsound
duration = 1000 # millisecond
freq = 440 # Hz
winsound.Beep(freq, duration)
return
t=input("按下 enter 键退出,其他键及enter 键 开始工作 ...\n")
if len(t)==0 :
print("BYE!")
quit() # quit() , exit() 执行到此命令时,程序终止。
else:
print("欢迎使用《应用系统》!")
sound()
name = input('请输入用户名:')
pas = input('密码: ')
print(name, " ,您好!")
以上代码中 ,\n 实现换行,提示用户: 按下 enter(回车) 键退出,其它键开始工作...
同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
#!/usr/bin/python
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
执行以上代码,输入结果为:
$ python test.py
runoob
print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上逗号 ,。
实例
x="a"
y="b"
# 换行输出()
print(x)
print (y)
print( '---------')
# 不换行输出
print( x,y)
以上实例执行结果为:
a b --------- a b
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
如下实例:
if expression :
suite
elif expression :
suite
else :
suite
命令行参数
很多程序可以执行一些操作来查看一些基本信息,Python 可以使用 -h 参数查看各参数帮助信息:
$ python -h usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ... Options and arguments (and corresponding environment variables): -c cmd : program passed in as string (terminates option list) -d : debug output from parser (also PYTHONDEBUG=x) -E : ignore environment variables (such as PYTHONPATH) -h : print this help message and exit [ etc. ]
Python 变量类型
变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。
基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。
因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
变量赋值
Python 中的变量赋值不需要类型声明。
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
等号 = 用来给变量赋值。
等号 = 运算符左边是一个变量名,等号 = 运算符右边是存储在变量中的值。例如:
实例
counter = 100 # 赋值整型变量
miles = 1000.0 # 浮点型
name = "John" # 字符串
print (counter, miles, name) # 输出变量的值
以上实例中,100,1000.0和"John"分别赋值给counter,miles,name变量。
执行以上程序会输出如下结果:
100 1000.0 John
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "john"
以上实例,两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 "john" 分配给变量 c。
标准数据类型
在内存中存储的数据可以有多种类型。
例如,一个人的年龄可以用数字来存储,他的名字可以用字符来存储。
Python 定义了一些标准类型,用于存储各种类型的数据。
Python有五个标准的数据类型:
Numbers(数字)
String(字符串)
List(列表)
Tuple(元组)
Dictionary(字典)
Python 数字
数字数据类型用于存储数值。
他们是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。
当你指定一个值时,Number 对象就会被创建:
var1 = 1
var2 = 10
也可以使用del语句删除一些对象的引用。
del语句的语法是:
del var1[,var2[,var3[....,varN]]]
可以通过使用del语句删除单个或多个对象的引用。例如:
del var
del var_a, var_b
Python支持四种不同的数字类型:
int(有符号整型)
long(长整型[也可以代表八进制和十六进制])
float(浮点型)
complex(复数)
实例
一些数值类型的实例:
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3e+18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2E-12 | 4.53e-7j |
长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
注意:long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
Python字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符。
一般记为 :
s = "a1a2···an" # n>=0
它是编程语言中表示文本的数据类型。
python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1
从右到左索引默认-1开始的,最大范围是字符串开头
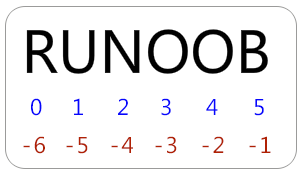
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
比如:
>>> s = 'abcdef'
>>> s[1:5]
'bcde'
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。

加号(+)是字符串连接运算符,星号(*)是重复操作。如下实例:
#实例
str = 'Hello World!'
print (str) # 输出完整字符串
print (str[0]) # 输出字符串中的第一个字符
print (str[2:5]) # 输出字符串中第三个至第六个之间的字符串
print (str[2:]) # 输出从第三个字符开始的字符串
print (str * 2) # 输出字符串两次
print (str + "TEST") # 输出连接的字符串
以上实例输出结果:
Hello World!
H
llo
llo World!
Hello World!Hello World!
Hello World!TEST
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
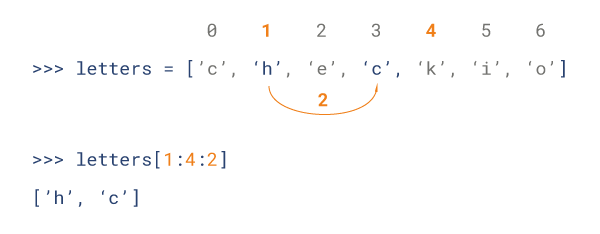
Python列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
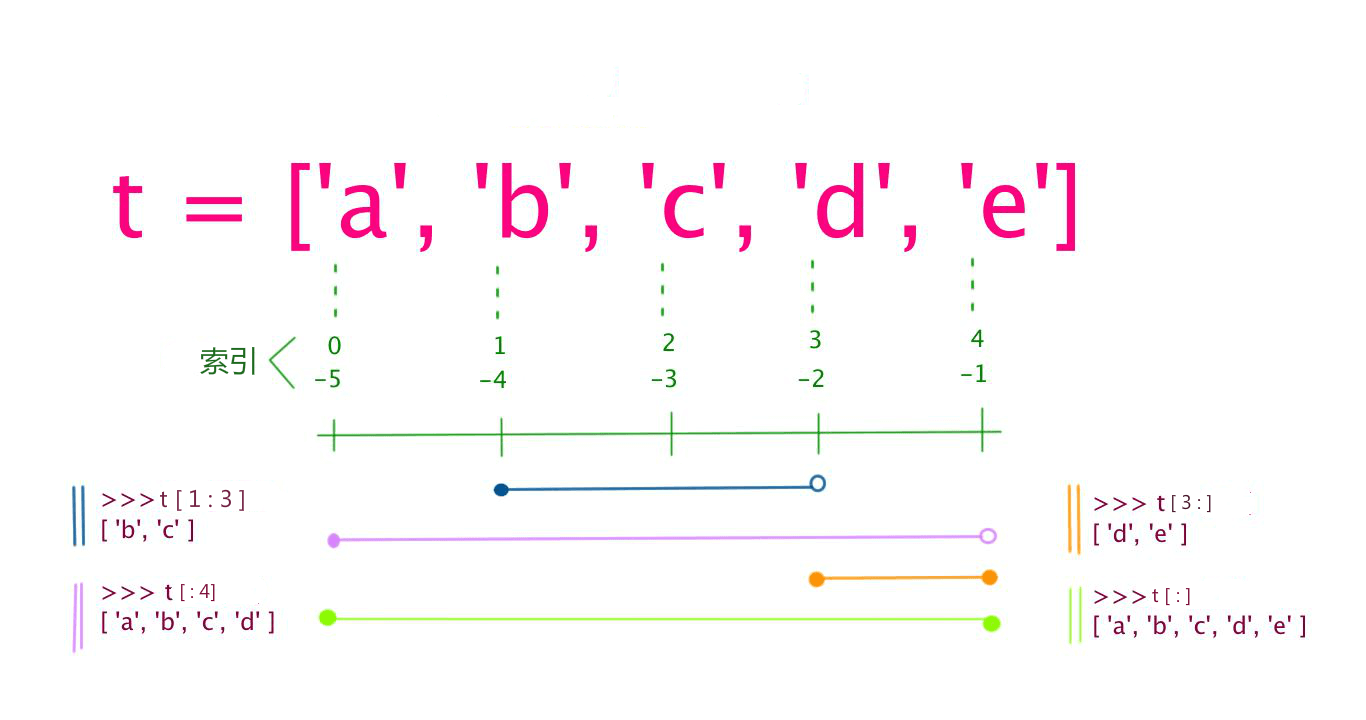
加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
#实例
list = [ 'runoob', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
print (list) # 输出完整列表
print (list[0]) # 输出列表的第一个元素
print (list[1:3] ) # 输出第二个至第三个元素
print (list[2:]) # 输出从第三个开始至列表末尾的所有元素
print (tinylist * 2 ) # 输出列表两次
print (list + tinylist) # 打印组合的列表
以上实例输出结果:
['runoob', 786, 2.23, 'john', 70.2] runoob [786, 2.23] [2.23, 'john', 70.2] [123, 'john', 123, 'john'] ['runoob', 786, 2.23, 'john', 70.2, 123, 'john']
Python 元组
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
实例
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 )
tinytuple = (123, 'john')
print (tuple) # 输出完整元组
print (tuple[0] ) # 输出元组的第一个元素
print (tuple[1:3] ) # 输出第二个至第四个(不包含)的元素
print (tuple[2:]) # 输出从第三个开始至列表末尾的所有元素
print (tinytuple * 2) # 输出元组两次
print (tuple + tinytuple) # 打印组合的元组
以上实例输出结果:
('runoob', 786, 2.23, 'john', 70.2)
runoob
(786, 2.23)
(2.23, 'john', 70.2)
(123, 'john', 123, 'john')
('runoob', 786, 2.23, 'john', 70.2, 123, 'john')以下是元组无效的,因为元组是不允许更新的。而列表是允许更新的:
实例
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 )
list = [ 'runoob', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # 元组中是非法应用 l
ist[2] = 1000 # 列表中是合法应用
Python 字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
实例
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'runoob','code':6734, 'dept': 'sales'}
print ( dict['one'] ) # 输出键为'one' 的值
print ( dict[2] ) # 输出键为 2 的值
print ( tinydict ) # 输出完整的字典
print ( tinydict.keys() ) # 输出所有键
print ( tinydict.values()) # 输出所有值
输出结果为:
This is one
This is two
{'dept': 'sales', 'code': 6734, 'name': 'runoob'}
['dept', 'code', 'name']
['sales', 6734, 'runoob']Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
将x转换为一个整数 | |
将x转换为一个长整数 | |
将x转换到一个浮点数 | |
创建一个复数 | |
将对象 x 转换为字符串 | |
将对象 x 转换为表达式字符串 | |
用来计算在字符串中的有效Python表达式,并返回一个对象 | |
将序列 s 转换为一个元组 | |
将序列 s 转换为一个列表 | |
转换为可变集合 | |
创建一个字典。d 必须是一个序列 (key,value)元组。 | |
转换为不可变集合 | |
将一个整数转换为一个字符 | |
将一个整数转换为Unicode字符 | |
将一个字符转换为它的整数值 | |
将一个整数转换为一个十六进制字符串 | |
将一个整数转换为一个八进制字符串 |
Python 运算符
什么是运算符?
举个简单的例子 4 +5 = 9 。 例子中,4 和 5 被称为操作数,"+" 称为运算符。
Python语言支持以下类型的运算符:
接下来让我们一个个来学习Python的运算符。
Python算术运算符
以下假设变量: a=10,b=20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
以下实例演示了Python所有算术运算符的操作:
实例
a = 21;b = 10;c = 0
c = a + b
print( ' a,b ',a,b)
print( "1. c = a + b 的值为:", c)
c = a - b
print ("2. c = a - b 的值为:", c )
c = a * b
print ("3. c = a * b 的值为:", c)
c = a / b
print("4. c = a / b 的值为:", c )
c = a % b
print( "5. c = a % b 的值为:", c)
a = 3 ;b = 2 ;c = a**b # 修改变量 a 、b 、c
print( ' a,b ',a,b)
print ("6. c = a**b 的值为:", c )
c = a//b
print ("7. c = a//b 的值为:", c)
运行实例 »
以上实例输出结果:
a,b 21 10 1. c = a + b 的值为: 31 2. c = a - b 的值为: 11 3. c = a * b 的值为: 210 4. c = a / b 的值为: 2.1 5. c = a % b 的值为: 1 a,b 3 2 6. c = a**b 的值为: 9 7. c = a//b 的值为: 1
Python比较运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 true. |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃。 | (a <> b) 返回 true。这个运算符类似 != 。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。 | (a < b) 返回 true。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 true。 |
以下实例演示了Python所有比较运算符的操作:
实例
a = 21;b = 10;c = 0
if a == b :
print ("1. a 等于 b")
else:
print ("1. a 不等于 b")
if a != b :
print("2. a 不等于 b")
else:
print ("2 . a 等于 b")
以上实例输出结果:
1. a 不等于 b 2 . a 不等于 b
Python赋值运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
以下实例演示了Python所有赋值运算符的操作:
实例
a = 21;b = 10;c = 0
c = a + b
print ("1 - c 的值为:", c )
c += a
print( "2 - c 的值为:", c)
c *= a
print( "3 - c 的值为:", c )
c /= a
print ("4 - c 的值为:", c)
c = 2
c %= a
print( "5 - c 的值为:", c)
c **= a
print ("6 - c 的值为:", c )
c //= a
print ("7 - c 的值为:", c)
以上实例输出结果:
1 - c 的值为: 31 2 - c 的值为: 52 3 - c 的值为: 1092 4 - c 的值为: 52 5 - c 的值为: 2 6 - c 的值为: 2097152 7 - c 的值为: 99864
Python位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:
a = 0011 1100 b = 0000 1101 ----------------- a&b = 0000 1100 a|b = 0011 1101 a^b = 0011 0001 ~a = 1100 0011
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
以下实例演示了Python所有位运算符的操作:
实例
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print( "1 - c 的值为:", c )
c = a | b; # 61 = 0011 1101
print("2 - c 的值为:", c )
c = a ^ b; # 49 = 0011 0001
print ("3 - c 的值为:", c)
c = ~a; # -61 = 1100 0011
print( "4 - c 的值为:", c )
c = a << 2; # 240 = 1111 0000
print ("5 - c 的值为:", c )
c = a >> 2; # 15 = 0000 1111
print( "6 - c 的值为:", c)
以上实例输出结果:
1 - c 的值为: 12 2 - c 的值为: 61 3 - c 的值为: 49 4 - c 的值为: -61 5 - c 的值为: 240 6 - c 的值为: 15
Python逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
以上实例输出结果:
实例
a = 10;b = 20
if a and b :
print ( "1 - 变量 a 和 b 都为 true" )
else:
print ( "1 - 变量 a 和 b 有一个不为 true" )
if a or b :
print ( "2 - 变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print ( "2 - 变量 a 和 b 都不为 true" )
# 修改变量 a 的值
a = 0
if a and b :
print ( "3 - 变量 a 和 b 都为 true")
else:
print( "3 - 变量 a 和 b 有一个不为 true" )
if a or b :
print( "4 - 变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print( "4 - 变量 a 和 b 都不为 true" )
if not( a and b ):
print( "5 - 变量 a 和 b 都为 false,或其中一个变量为 false")
else:
print( "5 - 变量 a 和 b 都为 true")
以上实例输出结果:
1 - 变量 a 和 b 都为 true 2 - 变量 a 和 b 都为 true,或其中一个变量为 true 3 - 变量 a 和 b 有一个不为 true 4 - 变量 a 和 b 都为 true,或其中一个变量为 true 5 - 变量 a 和 b 都为 false,或其中一个变量为 false
Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
以下实例演示了Python所有成员运算符的操作:
实例
a = 10;b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print ("1 - 变量 a 在给定的列表中 list 中")
else:
print ("1 - 变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print ("2 - 变量 b 不在给定的列表中 list 中")
else:
print ("2 - 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print ("3 - 变量 a 在给定的列表中 list 中")
else:
print ("3 - 变量 a 不在给定的列表中 list 中")
以上实例输出结果:
1 - 变量 a 不在给定的列表中 list 中 2 - 变量 b 不在给定的列表中 list 中 3 - 变量 a 在给定的列表中 list 中
Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
以下实例演示了Python所有身份运算符的操作:
实例
a = 20;b = 20
if ( a is b ):
print ("1 - a 和 b 有相同的标识")
else:
print ("1 - a 和 b 没有相同的标识")
if ( a is not b ):
print ("2 - a 和 b 没有相同的标识")
else:
print ("2 - a 和 b 有相同的标识")
# 修改变量 b 的值
b = 30
if ( a is b ):
print("3 - a 和 b 有相同的标识")
else:
print ("3 - a 和 b 没有相同的标识")
if ( a is not b ):
print ("4 - a 和 b 没有相同的标识")
else:
print ("4 - a 和 b 有相同的标识")
以上实例输出结果:
1 - a 和 b 有相同的标识 2 - a 和 b 有相同的标识 3 - a 和 b 没有相同的标识 4 - a 和 b 没有相同的标识
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
>>> a = [1, 2, 3] >>> b = a >>> b is a True >>> b == a True >>> b = a[:] >>> b is a False >>> b == a True
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
以下实例演示了Python所有运算符优先级的操作:
#实例
a = 20;b = 10;c = 15;d = 5;e = 0
e = (a + b) * c / d #( 30 * 15 ) / 5
print( "(a + b) * c / d 运算结果为:", e)
e = ((a + b) * c) / d # (30 * 15 ) / 5
print ("((a + b) * c) / d 运算结果为:", e)
e = (a + b) * (c / d); # (30) * (15/5)
print( "(a + b) * (c / d) 运算结果为:", e)
e = a + (b * c) / d; # 20 + (150/5)
print ("a + (b * c) / d 运算结果为:", e)
以上实例输出结果:
(a + b) * c / d 运算结果为: 90 ((a + b) * c) / d 运算结果为: 90 (a + b) * (c / d) 运算结果为: 90 a + (b * c) / d 运算结果为: 50
控制语句
(1) if语句,当条件成立时运行语句块。经常与else, elif(相当于else if) 配合使用。
Python 条件语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
可以通过下图来简单了解条件语句的执行过程:
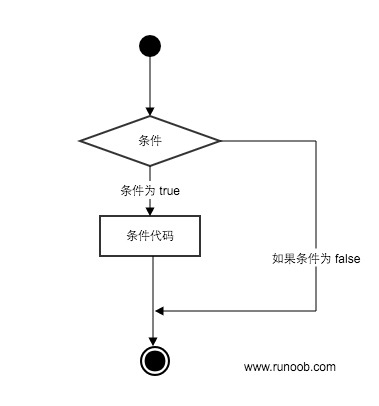
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件: 执行语句…… else: 执行语句……
其中"判断条件"成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。
else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
Gif 演示:

具体例子如下:
实例
例1:if 基本用法
flag = False
name = 'luren'
if name == 'python': # 判断变量是否为 python
flag = True # 条件成立时设置标志为真
print 'welcome boss' # 并输出欢迎信息
else:
print name # 条件不成立时输出变量名称
输出结果为:
luren # 输出结果
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1: 执行语句1…… elif 判断条件2: 执行语句2…… elif 判断条件3: 执行语句3…… else: 执行语句4……
实例如下:
例2:elif用法
num = 5
if num == 3: # 判断num的值
print 'boss'
elif num == 2:
print 'user'
elif num == 1:
print 'worker'
elif num < 0: # 值小于零时输出
print 'error'
else:
print 'roadman' # 条件均不成立时输出
输出结果为:
roadman # 输出结果
由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
实例
例3:if语句多个条件
num = 9
if num >= 0 and num <= 10: # 判断值是否在0~10之间
print 'hello' # 输出结果: hello
num = 10
if num < 0 or num > 10: # 判断值是否在小于0或大于10
print 'hello'
else:
print 'undefine' # 输出结果: undefine
num = 8 # 判断值是否在0~5或者10~15之间
if (num >= 0 and num <= 5) or (num >= 10 and num <= 15):
print 'hello'
else:
print 'undefine' # 输出结果: undefine
当if有多个条件时可使用括号来区分判断的先后顺序,括号中的判断优先执行,此外 and 和 or 的优先级低于>(大于)、<(小于)等判断符号,即大于和小于在没有括号的情况下会比与或要优先判断。
Python 循环语句
向大家介绍Python的循环语句,程序在一般情况下是按顺序执行的。
编程语言提供了各种控制结构,允许更复杂的执行路径。
循环语句允许我们执行一个语句或语句组多次,下面是在大多数编程语言中的循环语句的一般形式:
Python 提供了 for 循环和 while 循环(在 Python 中没有 do..while 循环):
| 循环类型 | 描述 |
|---|---|
| while 循环 | 在给定的判断条件为 true 时执行循环体,否则退出循环体。 |
| for 循环 | 重复执行语句 |
| 嵌套循环 | 你可以在while循环体中嵌套for循环 |
循环控制语句
循环控制语句可以更改语句执行的顺序。Python支持以下循环控制语句:
| 控制语句 | 描述 |
|---|---|
| break 语句 | 在语句块执行过程中终止循环,并且跳出整个循环 |
| continue 语句 | 在语句块执行过程中终止当前循环,跳出该次循环,执行下一次循环。 |
| pass 语句 | pass是空语句,是为了保持程序结构的完整性。 |
Python for 循环语句
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
语法:
for循环的语法格式如下:
for iterating_var in sequence:
statements(s)
流程图:
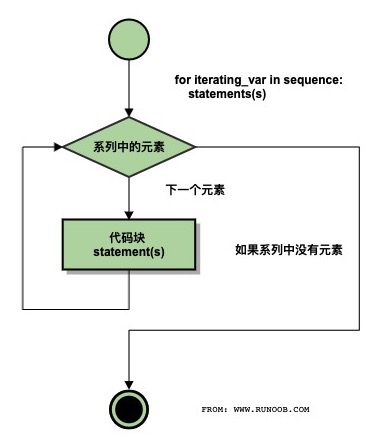
实例:
for letter in 'Python': # 第一个实例
print('当前字母 :', letter)
fruits = ['banana', 'apple', 'mango']
for fruit in fruits: # 第二个实例
print( '当前水果 :', fruit )
print("Good bye!")
以上实例输出结果:
当前字母 : P 当前字母 : y 当前字母 : t 当前字母 : h 当前字母 : o 当前字母 : n 当前水果 : banana 当前水果 : apple 当前水果 : mango Good bye!
通过序列索引迭代
另外一种执行循环的遍历方式是通过索引,如下实例:
实例
fruits = ['banana', 'apple', 'mango']
for index in range(len(fruits)):
print ('当前水果 :', fruits[index])
print ("Good bye!")
以上实例输出结果:
当前水果 : banana 当前水果 : apple 当前水果 : mango Good bye!
以上实例我们使用了内置函数 len() 和 range(),函数 len() 返回列表的长度,即元素的个数。 range返回一个序列的数。
循环使用 else 语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
实例
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print( '%d 等于 %d * %d' % (num,i,j) )
break # 跳出当前循环
else: # 循环的 else 部分 注意:这里有else不是与if 配对的!!
print( num, '是一个质数')
以上实例输出结果:
10 等于 2 * 5 11 是一个质数 12 等于 2 * 6 13 是一个质数 14 等于 2 * 7 15 等于 3 * 5 16 等于 2 * 8 17 是一个质数 18 等于 2 * 9 19 是一个质数
for语句,遍历列表、字符串、字典、集合等迭代器,依次处理迭代器中的每个元素。
while语句,当条件为真时,循环运行语句块。
Python While 循环语句
Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
while 判断条件(condition): 执行语句(statements)……
执行语句可以是单个语句或语句块。判断条件可以是任何表达式,任何非零、或非空(null)的值均为true。
当判断条件假 false 时,循环结束。
执行流程图如下:
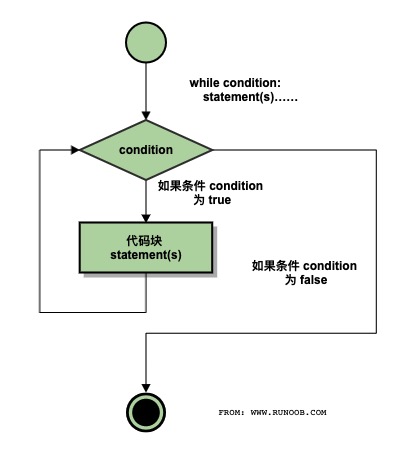
Gif 演示 Python while 语句执行过程

复杂一点:

实例
#!/usr/bin/python count = 0while (count < 9): print 'The count is:', count count = count + 1 print "Good bye!"
以上代码执行输出结果:
The count is: 0 The count is: 1 The count is: 2 The count is: 3 The count is: 4 The count is: 5 The count is: 6 The count is: 7 The count is: 8 Good bye!
while 语句时还有另外两个重要的命令 continue,break 来跳过循环,continue 用于跳过该次循环,break 则是用于退出循环,此外"判断条件"还可以是个常值,表示循环必定成立,具体用法如下:
# continue 和 break 用法
i = 1
while i < 10:
i += 1
if i%2 > 0: # 非双数时跳过输出
continue
print i # 输出双数2、4、6、8、10
i = 1
while 1: # 循环条件为1必定成立
print i # 输出1~10
i += 1
if i > 10: # 当i大于10时跳出循环
break
无限循环
如果条件判断语句永远为 true,循环将会无限的执行下去,如下实例:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
var = 1
while var == 1 : # 该条件永远为true,循环将无限执行下去
num = raw_input("Enter a number :")
print "You entered: ", num print "Good bye!"
以上实例输出结果:
Enter a number :20
You entered: 20
Enter a number :29
You entered: 29
Enter a number :3
You entered: 3
Enter a number between :Traceback (most recent call last):
File "test.py", line 5, in <module>
num = raw_input("Enter a number :")
KeyboardInterrupt注意:以上的无限循环你可以使用 CTRL+C 来中断循环。
循环使用 else 语句
在 python 中,while … else 在循环条件为 false 时执行 else 语句块:
实例
#!/usr/bin/python count = 0while count < 5: print count, " is less than 5" count = count + 1else: print count, " is not less than 5"
以上实例输出结果为:
0 is less than 5 1 is less than 5 2 is less than 5 3 is less than 5 4 is less than 5 5 is not less than 5
简单语句组
类似 if 语句的语法,如果你的 while 循环体中只有一条语句,你可以将该语句与while写在同一行中, 如下所示:
实例
#!/usr/bin/python
flag = 1
while (flag):
print 'Given flag is really true!'
print "Good bye!"
注意:以上的无限循环你可以使用 CTRL+C 来中断循环。
try语句,与except,finally配合使用处理在程序运行中出现的异常情况。
Python 异常处理
python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误。你可以使用该功能来调试python程序。
重点知识:异常处理,断言(Assertions)。
python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
什么是异常?
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try....except...else的语法:
try: <语句> #运行别的代码 except <名字>: <语句> #如果在try部份引发了'name'异常 except <名字>,<数据>: <语句> #如果引发了'name'异常,获得附加的数据 else: <语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
实例
下面是简单的例子,它打开一个文件,在该文件中的内容写入内容,且并未发生异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()以上程序输出结果:
$ python test.py 内容写入文件成功 $ cat testfile # 查看写入的内容 这是一个测试文件,用于测试异常!!
实例
下面是简单的例子,它打开一个文件,在该文件中的内容写入内容,但文件没有写入权限,发生了异常:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()在执行代码前为了测试方便,我们可以先去掉 testfile 文件的写权限,命令如下:
chmod -w testfile
再执行以上代码:
$ python test.py Error: 没有找到文件或读取文件失败
使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try: 正常的操作 ...................... except: 发生异常,执行这块代码 ...................... else: 如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
使用except而带多种异常类型
你也可以使用相同的except语句来处理多个异常信息,如下所示:
try: 正常的操作 ...................... except(Exception1[, Exception2[,...ExceptionN]]]): 发生以上多个异常中的一个,执行这块代码 ...................... else: 如果没有异常执行这块代码
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try: <语句> finally: <语句> #退出try时总会执行 raise
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "Error: 没有找到文件或读取文件失败"如果打开的文件没有可写权限,输出如下所示:
$ python test.py Error: 没有找到文件或读取文件失败
同样的例子也可以写成如下方式:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
try:
fh = open("testfile", "w")
try:
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "关闭文件"
fh.close()
except IOError:
print "Error: 没有找到文件或读取文件失败"当在try块中抛出一个异常,立即执行finally块代码。
finally块中的所有语句执行后,异常被再次触发,并执行except块代码。
参数的内容不同于异常。
异常的参数
一个异常可以带上参数,可作为输出的异常信息参数。
你可以通过except语句来捕获异常的参数,如下所示:
try: 正常的操作 ...................... except ExceptionType, Argument: 你可以在这输出 Argument 的值...
变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
实例
以下为单个异常的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def temp_convert(var):
try:
return int(var)
except ValueError, Argument:
print "参数没有包含数字\n", Argument
# 调用函数
temp_convert("xyz");以上程序执行结果如下:
$ python test.py 参数没有包含数字 invalid literal for int() with base 10: 'xyz'
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:
try: 正常逻辑 except Exception,err: 触发自定义异常 else: 其余代码
实例
#!/usr/bin/python # -*- coding: UTF-8 -*- # 定义函数 def mye( level ): if level < 1: raise Exception,"Invalid level!" # 触发异常后,后面的代码就不会再执行 try: mye(0) # 触发异常 except Exception,err: print 1,err else: print 2
执行以上代码,输出结果为:
$ python test.py 1 Invalid level!
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
class Networkerror(RuntimeError): def __init__(self, arg): self.args = arg
在你定义以上类后,你可以触发该异常,如下所示:
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.argsclass语句,用于定义类型。
Python 面向对象
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。本章节我们将详细介绍Python的面向对象编程。
如果你以前没有接触过面向对象的编程语言,那你可能需要先了解一些面向对象语言的一些基本特征,在头脑里头形成一个基本的面向对象的概念,这样有助于你更容易的学习Python的面向对象编程。
接下来我们先来简单的了解下面向对象的一些基本特征。
面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
class ClassName: '类的帮助信息' #类文档字符串 class_suite #类体
类的帮助信息可以通过ClassName.__doc__查看。
class_suite 由类成员,方法,数据属性组成。
实例
以下是一个简单的 Python 类的例子:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class Employee: '所有员工的基类' empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.emp
Count += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。
第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__) t = Test()t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878> __main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.__class__ 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
实例
class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878> __main__.Test
创建实例对象
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式。
以下使用类的名称 Employee 来实例化,并通过 __init__ 方法接收参数。
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)访问属性
您可以使用点号 . 来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee() emp2.displayEmployee() print "Total Employee %d" % Employee.empCount
完整实例:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class Employee: '所有员工的基类' empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary "创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)emp1.displayEmployee()emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
执行以上代码输出结果如下:
Name : Zara ,Salary: 2000 Name : Manni ,Salary: 5000 Total Employee 2
你可以添加,删除,修改类的属性,如下所示:
emp1.age = 7 # 添加一个 'age' 属性 emp1.age = 8 # 修改 'age' 属性 del emp1.age # 删除 'age' 属性
你也可以使用以下函数的方式来访问属性:
getattr(obj, name[, default]) : 访问对象的属性。
hasattr(obj,name) : 检查是否存在一个属性。
setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
delattr(obj, name) : 删除属性。
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。getattr(emp1, 'age') # 返回 'age' 属性的值setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8delattr(emp1, 'age') # 删除属性 'age'
Python内置类属性
__dict__ : 类的属性(包含一个字典,由类的数据属性组成)
__doc__ :类的文档字符串
__name__: 类名
__module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
__bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
Python内置类属性调用实例如下:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class Employee: '所有员工的基类' empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
print "Employee.__doc__:", Employee.__doc__
print "Employee.__name__:", Employee.__name__
print "Employee.__module__:", Employee.__module__
print "Employee.__bases__:", Employee.__bases__
print "Employee.__dict__:", Employee.__dict__
执行以上代码输出结果如下:
Employee.__doc__: 所有员工的基类
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: ()
Employee.__dict__: {'__module__': '__main__', 'displayCount': <function displayCount at 0x10a939c80>, 'empCount': 0, 'displayEmployee': <function displayEmployee at 0x10a93caa0>, '__doc__': '\xe6\x89\x80\xe6\x9c\x89\xe5\x91\x98\xe5\xb7\xa5\xe7\x9a\x84\xe5\x9f\xba\xe7\xb1\xbb', '__init__': <function __init__ at 0x10a939578>}python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是"立即"的, 由解释器在适当的时机,将垃圾对象占用的内存空间回收。
a = 40 # 创建对象 <40> b = a # 增加引用, <40> 的计数 c = [b] # 增加引用. <40> 的计数 del a # 减少引用 <40> 的计数 b = 100 # 减少引用 <40> 的计数 c[0] = -1 # 减少引用 <40> 的计数
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(即未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
实例
析构函数 __del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*- class Point: def __init__( self, x=0, y=0): self.x = x self.y = y def __del__(self): class_name = self.__class__.__name__ print class_name, "销毁" pt1 = Point()pt2 = pt1pt3 = pt1print id(pt1), id(pt2), id(pt3) # 打印对象的iddel pt1del pt2del pt3
以上实例运行结果如下:
3083401324 3083401324 3083401324 Point 销毁
注意:通常你需要在单独的文件中定义一个类,
类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
class 派生类名(基类名) ...
在python中继承中的一些特点:
1、如果在子类中需要父类的构造方法就需要显式的调用父类的构造方法,或者不重写父类的构造方法。详细说明可查看: python 子类继承父类构造函数说明。
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]): ...
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class Parent: # 定义父类 parentAttr = 100
def __init__(self):
print "调用父类构造函数"
def parentMethod(self):
print '调用父类方法'
def setAttr(self, attr): Parent.parentAttr = attr
def getAttr(self):
print "父类属性 :", Parent.parentAttr
class Child(Parent): # 定义子类
def __init__(self):
print "调用子类构造方法"
def childMethod(self):
print '调用子类方法' c = Child() # 实例化子类
c.childMethod() # 调用子类的方法
c.parentMethod() # 调用父类方法
c.setAttr(200) # 再次调用父类的方法 - 设置属性值
c.getAttr() # 再次调用父类的方法 - 获取属性值
以上代码执行结果如下:
调用子类构造方法 调用子类方法 调用父类方法 父类属性 : 200
你可以继承多个类
class A: # 定义类 A ..... class B: # 定义类 B ..... class C(A, B): # 继承类 A 和 B .....
你可以使用issubclass()或者isinstance()方法来检测。
issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
实例:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class Parent: # 定义父类
def myMethod(self):
print '调用父类方法'
class Child(Parent): # 定义子类
def myMethod(self):
print '调用子类方法'
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
执行以上代码输出结果如下:
调用子类方法
基础重载方法
下表列出了一些通用的功能,你可以在自己的类重写:
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | __init__ ( self [,args...] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | __del__( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | __repr__( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | __str__( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | __cmp__ ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |
运算符重载
Python同样支持运算符重载,实例如下:
实例
#!/usr/bin/python
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)v2 = Vector(5,-2)
print v1 + v2
以上代码执行结果如下所示:
Vector(7,8)
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
实例
#!/usr/bin/python# -*- coding: UTF-8 -*-
class JustCounter: __secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print self.__secretCount counter = JustCounter()counter.count()counter.count()
print counter.publicCount
print counter.__secretCount # 报错,实例不能访问私有变量
Python 通过改变名称来包含类名:
1 2 2 Traceback (most recent call last): File "test.py", line 17, in <module> print counter.__secretCount # 报错,实例不能访问私有变量 AttributeError: JustCounter instance has no attribute '__secretCount'
Python不允许实例化的类访问私有数据,但你可以使用 object._className__attrName( 对象名._类名__私有属性名 )访问属性,参考以下实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- class Runoob: __site = "www.runoob.com" runoob = Runoob() print runoob._Runoob__site
执行以上代码,执行结果如下:
www.runoob.com
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
def语句,用于定义函数和类型的方法。
关键字 def 引入了一个函数 定义。在其后必须跟有函数名和包括形式参数的圆括号。函数体语句从下一行开始,必须是缩进的。
函数体的第一行语句可以是可选的字符串文本,这个字符串是函数的文档字符串,或者称为 docstring。(更多关于 docstrings 的信息请参考 文档字符串) 有些工具通过 docstrings 自动生成在线的或可打印的文档,或者让用户通过代码交互浏览;在你的代码中包含 docstrings 是一个好的实践,让它成为习惯吧。
函数 调用 会为函数局部变量生成一个新的符号表。确切的说,所有函数中的变量赋值都是将值存储在局部符号表。变量引用首先在局部符号表中查找,然后是包含函数的局部符号表,然后是全局符号表,最后是内置名字表。因此,全局变量不能在函数中直接赋值(除非用 global 语句命名),尽管他们可以被引用。
函数引用的实际参数在函数调用时引入局部符号表,因此,实参总是 传值调用 (这里的 值 总是一个对象 引用 ,而不是该对象的值)。[1] 一个函数被另一个函数调用时,一个新的局部符号表在调用过程中被创建。
一个函数定义会在当前符号表内引入函数名。函数名指代的值(即函数体)有一个被 Python 解释器认定为 用户自定义函数 的类型。 这个值可以赋予其他的名字(即变量名),然后它也可以被当做函数使用。
return 语句从函数中返回一个值,不带表达式的 return 返回 None。
过程结束后也会返回 None。
pass语句,表示此行为空,不运行任何操作。
Python pass 语句
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
Python 语言 pass 语句语法格式如下:
pass
测试实例:
实例
#!/usr/bin/python# -*- coding: UTF-8 -*- # 输出 Python 的每个字母
for letter in 'Python':
if letter == 'h':
pass
print('这是 pass 块')
print( '当前字母 :', letter)
print( "Good bye!")
以上实例执行结果:
当前字母 : P 当前字母 : y 当前字母 : t 这是 pass 块 当前字母 : h 当前字母 : o 当前字母 : n Good bye!
assert语句,用于程序调试阶段时测试运行条件是否满足。
with语句,Python2.6以后定义的语法,在一个场景中运行语句块。比如,运行语句块前加密,然后在语句块运行退出后解密。
yield语句,在迭代器函数内使用,用于返回一个元素。自从Python 2.5版本以后。这个语句变成一个运算符。
raise语句,制造一个错误。
import语句,导入一个模块或包。
from … import语句,从包导入模块或从模块导入某个对象。
import … as语句,将导入的对象赋值给一个变量。
in语句,判断一个对象是否在一个字符串/列表/元组里。
表达式
Python的表达式写法与C/C++类似。只是在某些写法有所差别。
主要的算术运算符与C/C++类似。+, -, *, /, //, **, ~, %分别表示加法或者取正、减法或者取负、乘法、除法、整除、乘方、取补、取余。>>,
Python使用and, or, not表示逻辑运算。
is, is not用于比较两个变量是否是同一个对象。in, not in用于判断一个对象是否属于另外一个对象。
Python支持“列表推导式”(list comprehension),比如计算0-9的平方和:
1 2 | >>> sum(x * x for x in range(10)) 285 |
Python使用lambda表示匿名函数。匿名函数体只能是表达式。比如:
1 2 3 | >>> add=lambda x, y : x + y >>> add(3,2) 5 |
Python使用y if cond else x表示条件表达式。意思是当cond为真时,表达式的值为y,否则表达式的值为x。相当于C++和Java里的cond?y:x。
Python区分列表(list)和元组(tuple)两种类型。list的写法是[1,2,3],而tuple的写法是(1,2,3)。可以改变list中的元素,而不能改变tuple。在某些情况下,tuple的括号可以省略。tuple对于赋值语句有特殊的处理。因此,可以同时赋值给多个变量,比如:
1 | >>> x, y=1,2 # 同时给x,y赋值,最终结果:x=1, y=2 |
特别地,可以使用以下这种形式来交换两个变量的值:
1 | >>> x, y=y, x #最终结果:y=1, x=2 |
Python使用'(单引号)和"(双引号)来表示字符串。与Perl、Unix Shell语言或者Ruby、Groovy等语言不一样,两种符号作用相同。一般地,如果字符串中出现了双引号,就使用单引号来表示字符串;反之则使用双引号。如果都没有出现,就依个人喜好选择。出现在字符串中的\(反斜杠)被解释为特殊字符,比如\n表示换行符。表达式前加r指示Python不解释字符串中出现的\。这种写法通常用于编写正则表达式或者Windows文件路径。
Python支持列表切割(list slices),可以取得完整列表的一部分。支持切割操作的类型有str, bytes, list, tuple等。它的语法是...[left:right]或者...[left:right:stride]。假定nums变量的值是[1, 3, 5, 7, 8, 13, 20],那么下面几个语句为真:
nums[2:5] == [5, 7, 8] 从下标为2的元素切割到下标为5的元素,但不包含下标为5的元素。
nums[1:] == [3, 5, 7, 8, 13, 20] 切割到最后一个元素。
nums[:-3] == [1, 3, 5, 7] 从最开始的元素一直切割到倒数第3个元素。
nums[:] == [1, 3, 5, 7, 8, 13, 20] 返回所有元素。改变新的列表不会影响到nums。
nums[1:5:2] == [3, 7] 从下标为1的元素切割到下标为5的元素,且步长为2。
函数
如果你需要一个数值序列,内置函数 range() 会很方便,它生成一个等差级数链表:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
range(10) 生成了一个包含 10 个值的链表,它用链表的索引值填充了这个长度为 10 的列表,所生成的链表中不包括范围中的结束值。也可以让 range() 操作从另一个数值开始,或者可以指定一个不同的步进值(甚至是负数,有时这也被称为 “步长”):
range(5, 10)
5 through 9
range(0, 10, 3)
0, 3, 6, 9
range(-10, -100, -30)
-10, -40, -70
需要迭代链表索引的话,如下所示结合使 用 range() 和 len()
>>> a = ['Mary', 'had', 'a', 'little', 'lamb']
>>> for i in range(len(a)):
... print(i, a[i])
...
0 Mary
1 had
2 a
3 little
4 lamb
不过,这种场合可以方便的使用 enumerate(),请参见 循环技巧。
如果你只是打印一个序列的话会发生奇怪的事情:
>>> print(range(10))
range(0, 10)
在不同方面 range() 函数返回的对象表现为它是一个列表,但事实上它并不是。当你迭代它时,它是一个能够像期望的序列返回连续项的对象;但为了节省空间,它并不真正构造列表。
我们称此类对象是 可迭代的,即适合作为那些期望从某些东西中获得连续项直到结束的函数或结构的一个目标(参数)。我们已经见过的 for 语句就是这样一个迭代器。list() 函数是另外一个( 迭代器 ),它从可迭代(对象)中创建列表:
>>> list(range(5))
[0, 1, 2, 3, 4]
稍后我们会看到更多返回可迭代(对象)和以可迭代(对象)作为参数的函数。
Python的函数支持递归、默认参数值、可变参数,但不支持函数重载。为了增强代码的可读性,可以在函数后书写“文档字符串”(Documentation Strings,或者简称docstrings),用于解释函数的作用、参数的类型与意义、返回值类型与取值范围等。可以使用内置函数help()打印出函数的使用帮助。比如:
>>> def randint(a, b):
... "Return random integer in range [a, b], including both end points."...
>>> help(randint)
Help on function randint in module __main__:
randint(a, b)
Return random integer inrange[a, b], including both end points.
对象的方法
对象的方法是指绑定到对象的函数。调用对象方法的语法是instance.method(arguments)。它等价于调用Class.method(instance, arguments)。当定义对象方法时,必须显式地定义第一个参数,一般该参数名都使用self,用于访问对象的内部数据。这里的self相当于C++, Java里面的this变量,但是我们还可以使用任何其它合法的参数名,比如this 和 mine 等,self与C++,Java里面的this不完全一样,它可以被看作是一个习惯性的用法,我们传入任何其它的合法名称都行,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class Fish: def eat(self,food): if food is not None: self.hungry=False
class User: def __init__(myself,name): myself.name=name
#构造Fish的实例: f=Fish() #以下两种调用形式是等价的: Fish.eat(f,"earthworm") f.eat("earthworm") u=User('username') print(u.name) |
Python认识一些以“__”开始并以“__”结束的特殊方法名,它们用于实现运算符重载和实现多种特殊功能。
类型
Python采用动态类型系统。在编译的时候,Python不会检查对象是否拥有被调用的方法或者属性,而是直至运行时,才做出检查。所以操作对象时可能会抛出异常。不过,虽然Python采用动态类型系统,它同时也是强类型的。Python禁止没有明确定义的操作,比如数字加字符串。
与其它面向对象语言一样,Python允许程序员定义类型。构造一个对象只需要像函数一样调用类型即可,比如,对于前面定义的Fish类型,使用Fish()。类型本身也是特殊类型type的对象(type类型本身也是type对象),这种特殊的设计允许对类型进行反射编程。
Python内置丰富的数据类型。与Java、C++相比,这些数据类型有效地减少代码的长度。下面这个列表简要地描述了Python内置数据类型(适用于Python 3.x):
类型 | 描述 | 例子 | 备注 |
str(string/字符串) | 一个由字符组成的不可更改的有序串行。 | 'Wikipedia' "Wikipedia" """Spanning multiple lines""" | 在Python 3.x里,字符串由Unicode字符组成 |
bytes(字节) | 一个由字节组成的不可更改的有序串行。 | b'Some ASCII' b"Some ASCII" | 在Python 2.x里,bytes为str的一种 |
list(列表) | 可以包含多种类型的可改变的有序串行 | [4.0, 'string', True] | |
tuple(元组) | 可以包含多种类型的不可改变的有序串行 | (4.0, 'string', True) | |
set, frozenset | 与数学中集合的概念类似。无序的、每个元素唯一。 | {4.0, 'string', True} frozenset([4.0, 'string', True]) | |
dict(字典) | 一个可改变的由键值对组成的无序串行。 | {'key1': 1.0, 3: False} | |
int(整数) | 精度不限的整数 | 42 | |
float(浮点数) | 浮点数。精度与系统相关。 | 3.1415927 | |
complex | 复数 | 3+2.7j | |
bool | 逻辑值。只有两个值:真、假 | True False | |
builtin_function_or_method | 自带的函数,不可更改也不可增加 | input | |
type(类型) | 显示某个值的类型,用type(x)获得 | type(1) -> type(‘1’) -> | |
range | 按顺序排列的数 | range(10) ......list(range(10))->[0,1,2,3,4,5,6,7,8,9] range(1,10) ......list(range(1,10))->[1,2,3,4,5,6,7,8,9] range(1,10,2) ......list(range(1,10,2))->[1,3,5,7,9] | 在Python 2.x中,range为builtin_function_or_method,获得的数为list |
除了各种数据类型,Python语言还用类型来表示函数、模块、类型本身、对象的方法、编译后的Python代码、运行时信息等等。因此,Python具备很强的动态性。
数学运算
Python使用与C、Java类似的运算符,支持整数与浮点数的数学运算。同时还支持复数运算与无穷位数(实际受限于计算机的能力)的整数运算。除了求绝对值函数abs()外,大多数数学函数处于math和cmath模块内。前者用于实数运算,而后者用于复数运算。使用时需要先导入它们,比如:
>>> import math
>>> print(math.sin(math.pi/2))
1.0
fractions模块用于支持分数运算;decimal模块用于支持高精度的浮点数运算。
Python定义求余运行a % b的值处于开区间[0, b)内,如果b是负数,开区间变为(b, 0]。这是一个很常见的定义方式。不过其实它依赖于整除的定义。为了让方程式:b * (a // b) + a % b = a恒真,整除运行需要向负无穷小方向取值。比如7 // 3的结果是2,而(-7) // 3的结果却是-3。这个算法与其它很多编程语言不一样,需要注意,它们的整除运算会向0的方向取值。
Python允许像数学的常用写法那样连着写两个比较运行符。比如a < b < c与a < b and b < c等价。C++的结果与Python不一样,首先它会先计算a < b,根据两者的大小获得0或者1两个值之一,然后再与c进行比较。
python中的模块、包、库
模块:就是.py文件,里面定义了一些函数和变量,需要的时候就可以导入这些模块
包:在模块之上的概念,为了方便管理而将文件进行打包。
一个文件夹下必须要有_init_.py这个文件才会被识别为包。
包目录下第一个文件便是 init.py,然后是一些模块文件和子目录
假如子目录中也有 init.py,那么它就是这个包的子包了
常见的包结构:
package_a
── __init__.py
── module_a1.py
── module_a2.py
库:具有相关功能模块的集合。
这也是Python的一大特色之一,即具有强大的标准库、第三方库以及自定义模块。
标准库:就是下载安装的python里那些自带的模块,要注意的是,里面有一些模块是看不到的比如像sys模块,这与linux下的cd命令看不到是一样的情况
第三方库:就是由其他的第三方机构,发布的具有特定功能的模块
自定义模块:用户自己可以自行编写模块,然后使用
另外:模块、包、库这三个概念实际上都是模块,只不过是个体和集合的区别
Python中的import
当一个目录下有_init_.py文件时,该目录就是一个python的包
直接import安装的包
import Module
import Module as xx
从包import对象(下级模块,类,函数,变量等)
from Module import Name
from Module import xx as hostname
from Module import *
import包和import单个文件是一样的,我们可以这样类比:
import单个文件时,文件里的类,函数,变量都可以作为import的对象
import包时,包里的子包,文件,以及_init_.py里的类,函数,变量都可以作为import的对象
假设有如下目录结构
pkg
── init.py
── file.py
其中init.py内容如下
argument = 0
class A:pass
在和pkg同级目录下执行如下语句都是OK的
import pkg
import pkg.file
from pkg import file
from pkg import A
from pkg import argument
但如下语句是错误的
import pkg.A
import pkg.argument
报错ImportError: No module named xxx,因为当我们执行import A.B,A和B都必须是模块(文件或包)
引用主程序所在库中的模块
Python引用当前库中的模块关键是能够在sys.path里面找到通向模块文件的路径。
下面将具体介绍几种常用情况:
(1)主程序与模块程序在同一目录下:
如下面程序结构:
– src
– mod1.py
`– test1.py
若在程序test1.py中导入模块mod1, 则直接使用import mod1或from mod1 import *;
(2)主程序所在目录是模块所在目录的父(或祖辈)目录
如下面程序结构:
-- src
-- mod1.py
-- mod2
– mod2.py
– test1.py
若在程序test1.py中导入模块mod2, 需要在mod2文件夹中建立空文件_init_.py文件(也可以在该文件中自定义输出模块接口); 然后使用 from mod2.mod2 import * 或import mod2.mod2.
(3)主程序导入上层目录中模块或其他目录(平级)下的模块
如下面程序结构:
-- src
|-- mod1.py
|-- mod2
|– mod2.py
|– sub
| -- test2.py
– test1.py
若在程序test2.py中导入模块mod1和mod2。首先需要在mod2下建立init.py文件(同(2)),src下不必建立该文件。然后调用方式如下:
下面程序执行方式均在程序文件所在目录下执行,如test2.py是在cd sub;之后执行Python test2.py
而test1.py是在cd src;之后执行python test1.py; 不保证在src目录下执行python sub/test2.py成功。
import sys
sys.path.append(“..”)
import mod1
import mod2.mod2
(4)从(3)可以看出,导入模块关键是能够根据sys.path环境变量的值,找到具体模块的路径。这里仅介绍上面三种简单情况。
相对导入和绝对导入
绝对导入的格式为import A.B或from A import B
相对导入格式为from . import B或from ..A import B
.代表当前模块,..代表上层模块,…代表上上层模块,依次类推。当我们有多个包时,就可能有需求从一个包import另一个包的内容,这就会产生绝对导入,而这也往往是最容易发生错误的时候
导入模块时的一些规则
在没有明确指定包结构的情况下,python是根据name来决定一个模块在包中的结构的,如果是main则它本身是顶层模块,没有包结构,如果是A.B.C结构,那么顶层模块是A。
基本上遵循这样的原则
如果是绝对导入,一个模块只能导入自身的子模块或和它的顶层模块同级别的模块及其子模块
如果是相对导入,一个模块必须有包结构且只能导入它的顶层模块内部的模块
模块
如果想要编写一些更大的程序,为准备解释器输入使用一个文本编辑器会更好,并以那个文件替代作为输入执行。这通常也称程序脚本。随着程序变得越来越长,可能想要将它分割成几个更易于维护的文件。也可能想在不同的程序中使用顺手的函数,而不是把代码在它们之间中拷来拷去。
为了满足这些需要,Python 提供了一个方法可以从文件中获取定义,在脚本或者解释器的一个交互式实例中使用。这样的文件被称为 模块;模块中的定义可以 导入 到另一个模块或 主模块 中(在脚本执行时可以调用的变量集位于最高级,并且处于计算器模式)。
模块是包括 Python 定义和声明的文件。文件名就是模块名加上 .py 后缀。模块的模块名(做为一个字符串)可以由全局变量 __name__ 得到。例如,可以用自己惯用的文件编辑器在当前目录下创建一个叫 fibo.py 的文件,录入如下内容:
# Fibonacci numbers module def fib(n): # write Fibonacci series up to n a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() def fib2(n): # return Fibonacci series up to n result = [] a, b = 0, 1 while b < n: result.append(b) a, b = b, a+b return result
现在进入 Python 解释器并使用以下命令导入这个模块:
>>> import fibo
这样做不会直接把 fibo 中的函数导入当前的语义表;它只是引入了模块名 fibo。可以通过模块名按如下方式访问这个函数:
>>> fibo.fib(1000) 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 >>> fibo.fib2(100) [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89] >>> fibo.__name__ 'fibo'
如果打算频繁使用一个函数,你可以将它赋予一个本地变量:
>>> fib = fibo.fib >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
深入模块
除了包含函数定义外,模块也可以包含可执行语句。这些语句一般用来初始化模块。他们仅在 第一次 被导入的地方执行一次。
每个模块都有自己私有的符号表,被模块内所有的函数定义作为全局符号表使用。因此,模块的作者可以在模块内部使用全局变量,而无需担心它与某个用户的全局变量意外冲突。从另一个方面讲,如果你确切的知道自己在做什么,你可以使用引用模块函数的表示法访问模块的全局变量,modname.itemname。
模块可以导入其他的模块。一个(好的)习惯是将所有的 import 语句放在模块的开始(或者是脚本),这并非强制。被导入的模块名会放入当前模块的全局符号表中。
import 语句的一个变体直接从被导入的模块中导入命名到本模块的语义表中。例如:
>>> from fibo import fib, fib2 >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这样不会从局域语义表中导入模块名(如上所示, fibo 没有定义)。
甚至有种方式可以导入模块中的所有定义:
>>> from fibo import * >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这样可以导入所有除了以下划线( _ )开头的命名。
需要注意的是在实践中往往不鼓励从一个模块或包中使用 * 导入所有,因为这样会让代码变得很难读。不过,在交互式会话中这样用很方便省力。
Note
出于性能考虑,每个模块在每个解释器会话中只导入一遍。因此,如果你修改了你的模块,需要重启解释器;或者,如果你就是想交互式的测试这么一个模块,可以用 imp.reload() 重新加载,例如 import imp; imp.reload(modulename)。
Python 数组
请注意,Python 没有内置对数组的支持,但可以使用 Python 列表代替。
数组
数组用于在单个变量中存储多个值:
实例
创建一个包含汽车品牌的数组:
cars = ["Porsche", "Volvo", "BMW"]
什么是数组?
数组是一种特殊变量,能够一次包含多个值。
如果您有一个项目列表(例如,汽车品牌列表),将牌子存储在单个变量中可能如下所示:
car1 = "Porsche" car2 = "Volvo" car3 = "BMW"
但是,如果您想遍历这些品牌并找到特定的汽车品牌怎么办?如果不是 3 辆车,而是 300 辆怎么办?
解决方案是数组!
数组可以在单个名称下保存多个值,您可以通过引用索引号来访问这些值。
访问数组元素
通过索引号来引用数组元素。
实例
获取首个数组项目的值:
x = cars[0]
实例
修改首个数组项目的值:
cars[0] = "Audi"
数组长度
使用 len() 方法来返回数组的长度(数组中的元素数量)。
实例
返回 cars 数组中的元素数量:
x = len(cars)
注释:数组长度总是比最高的数组索引大一个。
循环数组元素
您可以使用 for in 循环遍历数组的所有元素。
实例
打印 cars 数组中的每个项目:
for x in cars: print(x)
添加数组元素
您可以使用 append() 方法把元素添加到数组中。
实例
向 cars 数组再添加一个元素:
cars.append("Audi")删除数组元素
您可以使用 pop() 方法从数组中删除元素。
实例
删除 cars 数组的第二个元素:
cars.pop(1)
您也可以使用 remove() 方法从数组中删除元素。
实例
删除值为 "Volvo" 的元素:
cars.remove("Volvo")注释:列表的 remove() 方法仅删除首次出现的指定值。
数组方法
Python 提供一组可以在列表或数组上使用的内建方法。
| 方法 | 描述 |
|---|---|
| append() | 在列表的末尾添加一个元素 |
| clear() | 删除列表中的所有元素 |
| copy() | 返回列表的副本 |
| count() | 返回具有指定值的元素数量。 |
| extend() | 将列表元素(或任何可迭代的元素)添加到当前列表的末尾 |
| index() | 返回具有指定值的第一个元素的索引 |
| insert() | 在指定位置添加元素 |
| pop() | 删除指定位置的元素 |
| remove() | 删除具有指定值的项目 |
| reverse() | 颠倒列表的顺序 |
| sort() | 对列表进行排序 |
注释:Python 没有内置对数组的的支持,但可以使用 Python 列表代替。

