Pandas中另一个重要的数据对象为数据框(DataFram),由多个序列按照相同的index组织在一起形成一个二维表。事实上,数据框的每一列为序列。数据框的属性包括index、列名和值。由于数据框是更为广泛的一种数据组织形式,许多外部数据文件读取到Python中大部分会采用数据框的形式进行存取,比如数据库、excel和TXT文本。同时数据框也提供了极为丰富的方法用于处理数据及完成计算任务。数据框是Python完成数据处理及分析的最重要数据结构之一,因此学会灵活运用数据框是利用Python进行数据处理及挖掘的关键环节。
下面主要介绍数据框的创建、属性、方法和数据的访问及切片等内容。
1 数据框创建
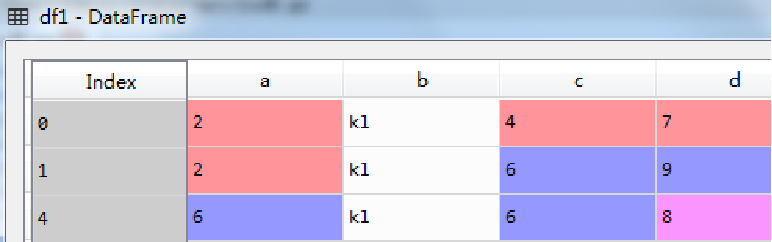
基于字典,利用Pandas库中的DataFrame函数,可以创建数据框。其中字典的键转化为列名,字典的值转化为列值,而索引为默认值,即从0开始从小到大排列。
import pandas as pd
import numpy as np
data={'a':[2,2,np.nan,5,6],'b':[‘kl’,’kl’,’kl’,np.nan,’kl’],’c’:[4,6,5,np.nan,6],’d’:[7,9,np.nan,9,8]}
df=pd.DataFrame(data)
如下图
2 数据框属性
数据框对象具有三个属性,分别为列名、索引和值。比如以上3.3.1定义的数据框df,可以通过以下示例程序获取并打印其属性结果。
print('columns= ')
print(df.columns)
print('-'*50)
print('index= ')
print(df.index)
print('-'*50)
print('values= ')
print(df.values)
输出结果为:
columns=
Index(['a', 'b', 'c', 'd'], dtype='object')
index= RangeIndex(start=0, stop=5, step=1)
--------------------------------------------------
values=
[[2.0 'kl' 4.0 7.0]
[2.0 'kl' 6.0 9.0]
[nan 'kl' 5.0 nan]
[5.0 nan nan 9.0]
[6.0 'kl' 6.0 8.0]]
3 数据框方法
数据框(DataFrame)作为数据处理及挖掘分析的重要基础数据结构,提供了非常丰富的方法用于数据处理及计算。下面介绍其常用的方法,包括去掉空值(nan值)、对空值(nan值)进行填充、基于字段列值进行排序、基于index进行排序、取前N行数据、删除列、数据框之间的连接、数据框转化为Numpy数组、数据导出到Excel、相关统计分析等。下面分别给出其详细的介绍。
3.1数据框方法--去掉空值
( 1) dropna()
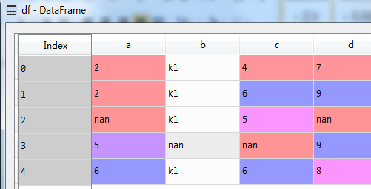
通过dorpna()方法,可以去掉数据集中的空值(nan值),需要注意的是原来数据集不发生改变,新数据集需要重新定义。以3.3.1定义的数据框df为例,示例代码如下:
df1=df.dropna()
执行结果如图所示(下)。
(2) fillna()
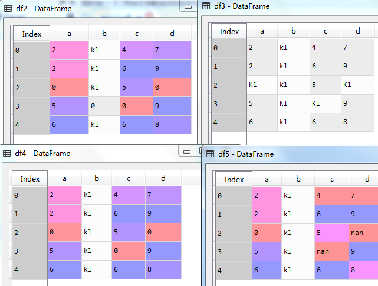
通过fillna()方法,可以对数据框中的空值(nan值)进行填充。默认情况下所有空值填充同一个元素值(数值或者字符串),也可以指定不同的列填充不同的值。以3.1定义的数据框df为例,示例代码如下:
df2=df.fillna(0) #所有空值元素填充0
df3=df.fillna('Kl') #所有空值元素填充kl
df4=df.fillna({'a':0,'b':'kl','c':0,'d':0}) #全部列填充
df5=df.fillna({'a':0,'b':'kl'}) #部分列填充
执行结果如图所示(下)。
3.2 数据框方法--指定的列进行排序 sort_values()
可以利用sort_values()方法,指定列按值进行排序,示例代码如下:
import pandas as pd
data={'a':[5,3,4,1,6],'b':['d','c','a','e','q'],'c':[4,6,5,5,6]}
Df=pd.DataFrame(data)
Df1=Df.sort_values('a',ascending=False)
#默认按升序,这里设置为降序
执行结果如图所示(下)。
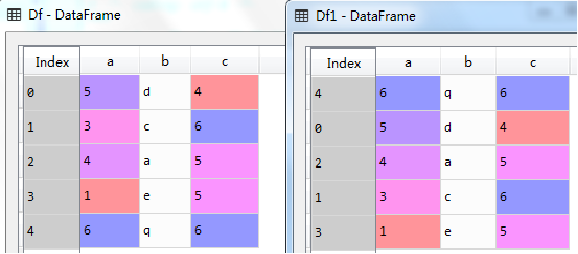
3.3 数据框方法—按索引进行排序 sort_index()
有时候需要对索引进行排序,这时候可以使用sort_index()方法,以前面定义的Df1为例,示例代码如下:
Df2=Df1.sort_index(ascending=False) #默认按升序,这里设置为降序
执行结果如图所示(下)。
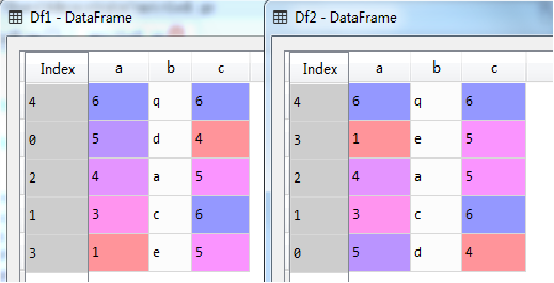
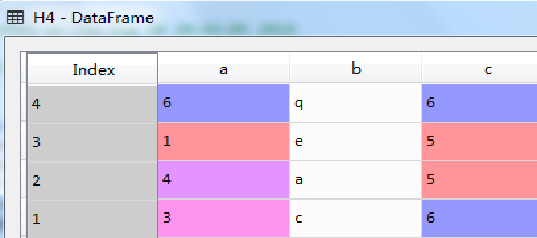
3.3 数据框方法—取前N行 head()
通过head(N)方法,可以取数据集中的前N行,比如取前面定义的数据框Df2中的前4行,示例代码如下:
H4=Df2.head(4);
执行结果如图所示(下)。
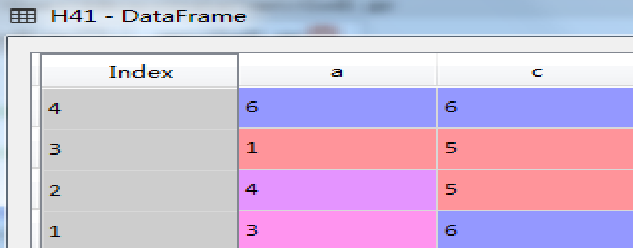
3.4 数据框方法—删除列 dorp()
利用dorp()方法,可以删掉数据集中的指定列。比如删除前面定义的H4中的b列,示例代码如下:
H41=H4.drop('b',axis=1) #需指定轴为1
执行结果如图所示(下)。
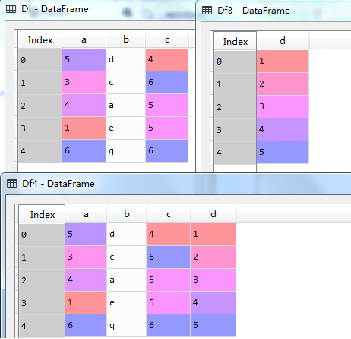
3.4 数据框方法—水平连接 join()
利用join()方法,可以实现两个数据框之间的水平连接,示例代码如下:
Df3=pd.DataFrame({'d':[1,2,3,4,5]})
Df4=Df.join(Df3)
执行结果如图所示(下)。
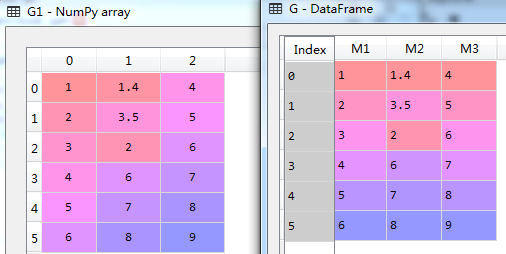
3.5 数据框方法—转换为数组 as_matrix()
可以利用as_matrix()方法,将数据框转换为Numpy数组的形式,方便程序使用,特别是数据框中的数据全为数值数据的时候更为有效。示例代码如下:
import pandas as pd
list1=['a','b','c','d','e','f']
list2=[1,2,3,4,5,6]
list3=[1.4,3.5,2,6,7,8]
list4=[4,5,6,7,8,9]
list5=['t',5,6,7,'k',9.6]
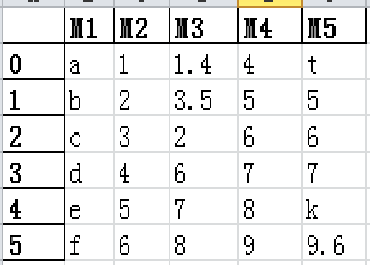
D={'M1':list1,'M2':list2,'M3':list3,'M4':list4,'M5':list5} #定义字典D,值为字符、数值混合数据
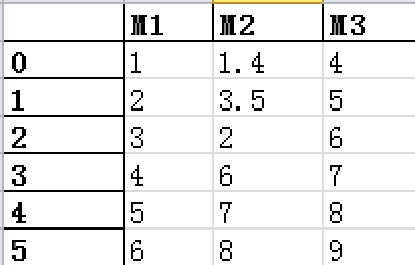
G={'M1':list2,'M2':list3,'M3':list4} #定义字典G,值为纯数值数据
D=pd.DataFrame(D) #将字典D转化为数据框
D1=D.as_matrix() #将数据框D转化为Numpy数组D1
G=pd.DataFrame(G) #将字典G转化为数据框
G1=G.as_matrix() #将数据框G转化为Numpy数组G1
执行结果如图所示(下)。
而D不是纯的数值数据,转换后的Numpy数组在Spyder变量资源管理器中无法查看,但可以打印出来在控制台窗口中查看,通过print(D1)打印得到如下结果:
[['a' 1 1.4 4 't']
['b' 2 3.5 5 5]
['c' 3 2.0 6 6]
['d' 4 6.0 7 7]
['e' 5 7.0 8 'k']
['f' 6 8.0 9 9.6]]
因此,如果数据框中的数据为纯数值的时候,通过转换为Numpy数值数组,使用起来显得更加方便。
3.6 数据框方法—导出excel to_excel()
Excel作为常用的数据处理软件,在日常工作中经常用到,通过to_excel()方法,可以将数据框导出到Excel文件中,比如将前面定义的D和G两个数据框导出到Excel文件中。示例代码如下:
D.to_excel('D.xlsx')
G.to_excel('G.xlsx')
执行结果如图所示(下)
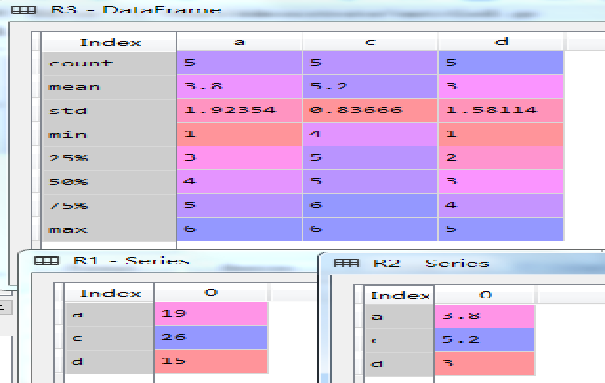
3.7 数据框方法—描述统计
统计方法 可以对数据框中各列求和、求平均值或者进行描述性统计,以前面定义的Df4为例,示例代码如下:
Dt=Df4.drop('b',axis=1) #Df4中删除b列
R1=Dt.sum() #各列求和
R2=Dt.mean() #各列求平均值
R3=Dt.describe() #各列做描述性统计
结果如图所示(下)。
4. 数据框切片
(1) 利用数据框中的iloc属性进行切片
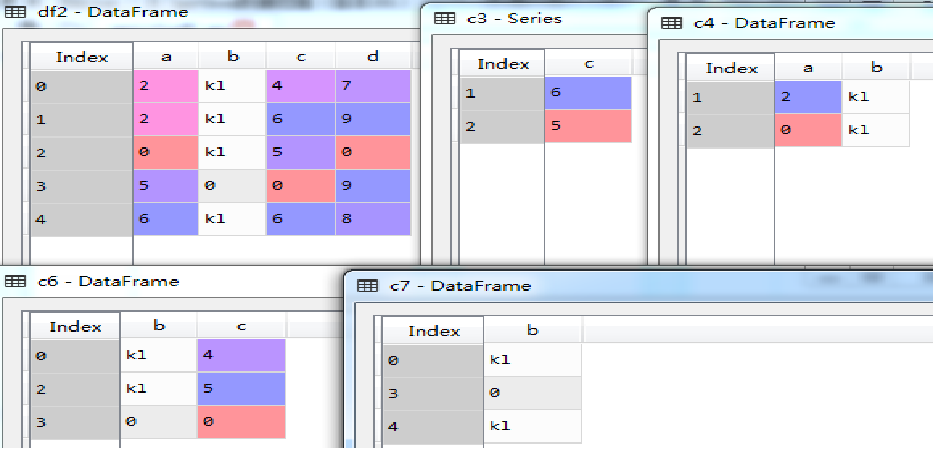
与数组切片类似,利用数据框中的iloc属性可以实现下标值或者逻辑值定位索引,并进行切片操作。假设DF为待访问或切片的数据框,则访问或者切片的数据=DF.iloc[①,②]。其中①为对DF的行下标控制,②为对DF的列下标控制,行和列下标控制通过数值列表来实现,但是需要注意的是列表中的元素不能超出DF中的最大行数和最大列数。为了更灵活地操作数据,取所有的行或者列,可以用“:”来代替实现。同时,行控制还可以通过逻辑列表来实现。以3.3中定义的df2为例,示例代码如下:
# iloc for positional indexing
c3=df2.iloc[1:3,2]
c4=df2.iloc[1:3,0:2]
c5=df2.iloc[1:3,:]
c6=df2.iloc[[0,2,3],[1,2]]
TF=[True,False,False,True,True]
c7=df2.iloc[TF,[1]]
执行结果如图所示(下)。
(2) 利用数据框中的loc属性进行切片
数据框中的loc属性则主要是基于列标签进行索引,即对列值进行筛选实现行定位,再通过指定列,从而实现数据切片操作。如果取所有列,可以用冒号来表示。切片操作获得的数据还可以筛选前N行。示例代码如下:
# loc for label based indexing
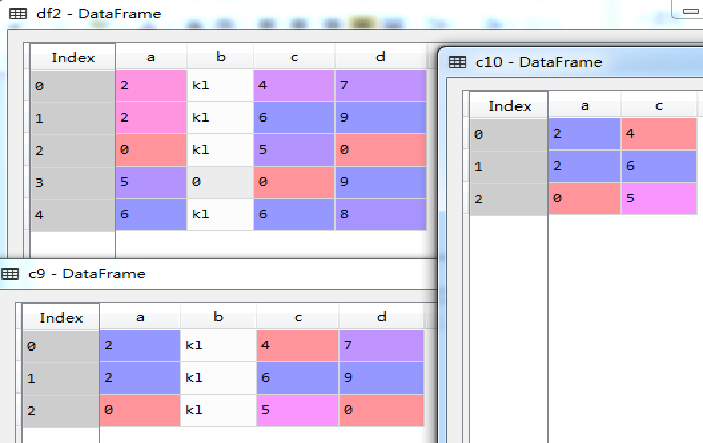
c8=df2.loc[df2['b'] == 'kl',:];
c9=df2.loc[df2['b'] == 'kl',:].head(3);
c10=df2.loc[df2['b'] == 'kl',['a','c']].head(3);
c11=df2.loc[df2['b'] == 'kl',['a','c']];
执行结果如图所示(下)。