一、外部文件读取
在实际数据挖掘分析中,其业务数据大多存储在外部文件中,比如Excel、TXT等。因此,需要将外部文件读取到Python中进行挖掘分析。Pandas包中提供了非常丰富的函数来读取各种类型的外部数据文件,下面主要介绍Excel和TxT外部文件的读取。
1、Excel文件读取
通过read_excel()函数读取Excel文件数据,可以读取指定的工作簿(sheet),也可以设置读取有无表头的数据表。示例代码如下:
path='一、车次上车人数统计表.xlsx';
data=pd.read_excel(path);
执行结果如图所示(下)。
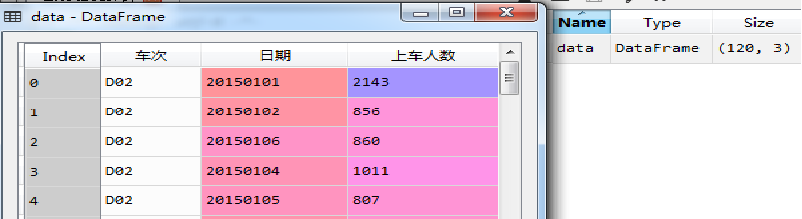
读取Sheet2里的数据,示例代码如下:
data=pd.read_excel(path,'Sheet2') #读取sheet里面的数据
执行结果图所示(下)。
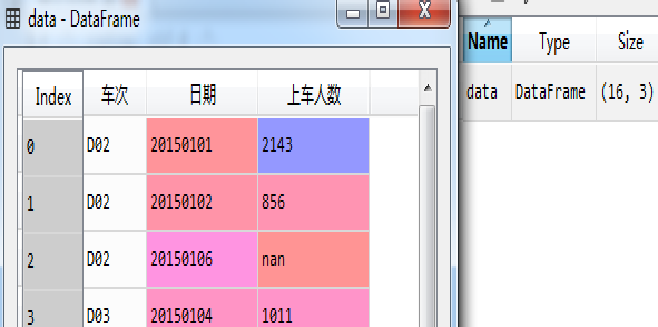
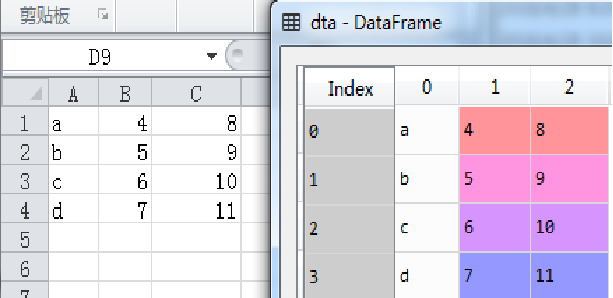
有时候数据表中没有设置字段,即无表头,读取格式示例代码如下:
dta=pd.read_excel('dta.xlsx',header=None) #无表头
执行结果如图所示(下)。
2、TXT文件读取
通过read_table()函数可以读取TXT文本数据。需要注意的是,TXT文本数据列之间会存在特殊字符作为分隔,常见的有Tab键、空格和逗号。同时还需注意有些文本数据文件是没有设置表头的。示例代码如下:
import pandas as pd
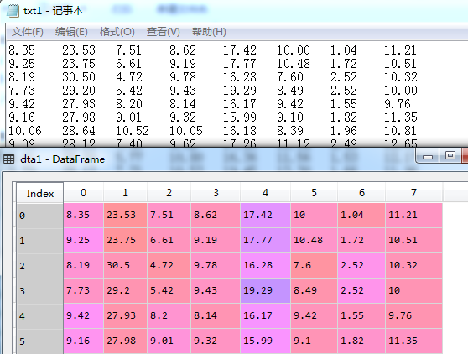
dta1=pd.read_table('txt1.txt',header=None) #分隔默认为Tab键,设置无表头。
执行结果如图所示(下)。
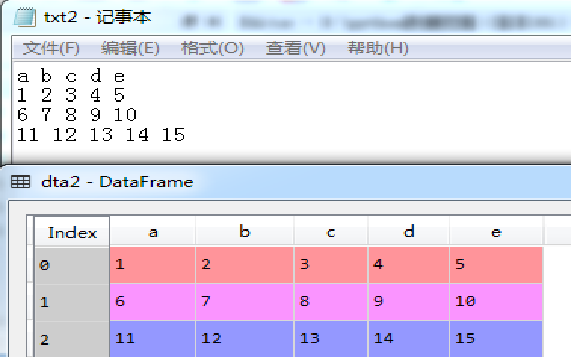
dta2=pd.read_table('txt2.txt',sep='\s+') #分隔为空格,带表头
执行结果如图所示(下)。
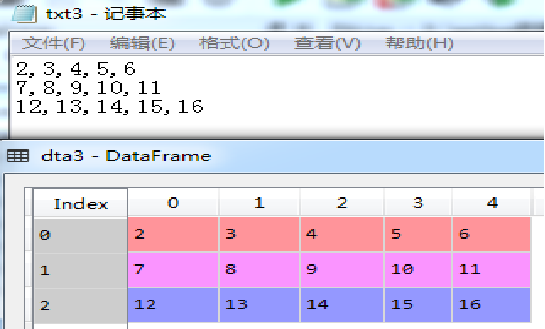
dta3=pd.read_table('txt3.txt',sep=',',header=None) #分隔为逗号,设置无表头
执行结果如图所示(下)。
3 、CSV文件读取
CSV文件也是一类广泛使用的外部数据文件,特别是大规模的数据文件尤为常见。本节介绍一般的CSV数据文件读取方法,对于大规模的数据我们给出分块读取的技巧。可以通过read_csv()函数读取,示例代码如下:
import pandas as pd
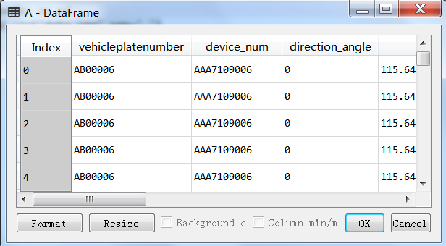
A=pd.read_csv('data.csv',sep=',');#道号分隔
执行结果如图所示(下)。
可以看出,其读取方式与Excel、TXT没有多少区别,但是特别要注意的是,CSV文件可以存储大规模的数据文件,比如单个数据文件可以容量可以达几G、十几G之多,这时候可以采用分块的方式进行读取。示例代码如下:
import pandas as pd
reader=pd.read_csv('data.csv',sep=',',chunksize=50000,usecols=[3,4,10])
k=0
for A in reader:
k=k+1
print('第'+str(k)+'次读取数据规模为: ',len(A))
执行结果如下:
第1次读取数据规模为: 50000
第2次读取数据规模为: 50000
第3次读取数据规模为: 33699
本案例介绍了对数据文件每次读取50000行记录,读取字段为指定的第3、4、10列,不足50000行的,按实际数据量读取。其中reader为一个数据阅读器,可以通过循环的方式依次把每次读取的数据取出来并进行处理。实际上,对于大规模的CSV数据文件,读取该文件的部分数据进行探索也是很有必要的,比如读取其前1000行,示例代码如下:
import pandas as pd
A=pd.read_csv('data.csv',sep=',',nrows=1000)。
3.5.1 常用函数--滚动计算函数
常用的滚动计算函数有滚动求和rolling_sum()、求平均值rolling_mean()、求最大值rolling_max()、求最小值rolling_min()等。滚动计算函数在金融数据处理中应用非常广泛,比如移动平均价、移动平均量等计算。下面我们对这几个函数进行详细介绍。
滚动求平均值函数的调用形式为:rolling_mean(P,N),其中P为待求的数据列,N为滚动计算的长度。这里P可以是Numpy数组或者序列数据结构,但是不能是列表或者元组,示例代码如下:
import pandas as pd
import numpy as np
L=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] #列表
T=(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15) #元组
A=np.array(L) #将列表L转换为数组,赋给变量A
S=pd.Series(L) #将列表L转换为序列,赋给变量S
#avg_L=pd.rolling_mean(L,10) #报错
#avg_T=pd.rolling_mean(T,10) #报错
avg_S=pd.rolling_mean(S,10)
avg_A=pd.rolling_mean(A,10)
执行结果如图所示(下)。

其中输入的数据结构为Numpy数组,其返回结果也为Numpy数组;如果输入的数据结构为序列形式,其返回结果也为序列。从返回的结果可以看出,不足滚动计算周期的数据,返回结果均采用nan(空值)来表示,在应用的过程中需要注意把这些数据清洗掉。
同理还有滚动求和函数rolling_sum(P,N)、滚动求最小值函数rolling_min(P,N)和滚动求最大值函数rolling_max(P,N)。示例代码如下:
sum_S=pd.rolling_sum(S,10)
sum_A=pd.rolling_sum(A,10)
Min_S=pd.rolling_min(S,10)
Min_A=pd.rolling_min(A,10)
Max_S=pd.rolling_max(S,10)
Max_A=pd.rolling_max(A,10)
3.5.2 常用函数--数据框合并函数
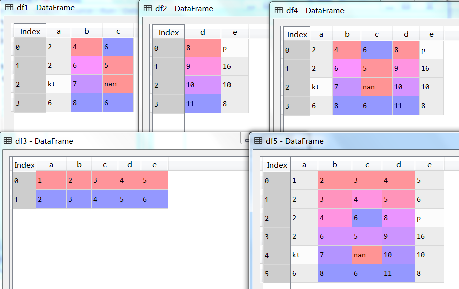
两个数据框之间的水平、垂直合并是数据处理与整合中经常发生的,这里介绍concat函数,可以通过设置轴(axis)为1和0实现。为了保持数据的规整性,一般情况下水平合并要求两个数据框的行数相同,而垂直合并要求两个数据框的字段名称相同,同时垂直合并后的数据框其index伴随原来的数据框,可以重新设置index而保障其连贯性。示例代码如下:
import pandas as pd
import numpy as np
dict1={'a':[2,2,'kt',6],'b':[4,6,7,8],'c':[6,5,np.nan,6]}
dict2={'d':[8,9,10,11],'e':['p',16,10,8]}
dict3={'a':[1,2],'b':[2,3],'c':[3,4],'d':[4,5],'e':[5,6]}
df1=pd.DataFrame(dict1)
df2=pd.DataFrame(dict2)
df3=pd.DataFrame(dict3)
del dict1,dict2,dict3
df4=pd.concat([df1,df2],axis=1)#水平合并
df5=pd.concat([df3,df4],axis=0)#垂直合并
df5.index=range(6) #重新修改index
执行结果如图所示(下)。
3.5.3 常用函数--数据框关联函数
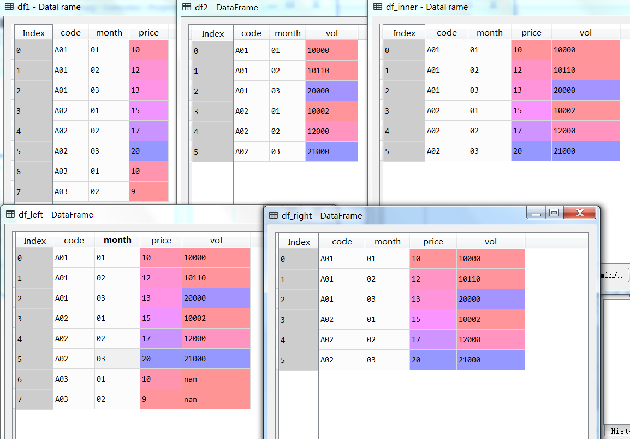
前面介绍了两个数据框之间的水平、垂直合并操作方法。除此之外,在数据处理中也经常会遇到数据框之间的关联操作,它们类似于数据库中的SQL关联操作语句,比如指定关联字段之后进行的内连接(inner join)、左连接(left join)和右连接(right join)等数据操作。其中内连接,可以理解为对指定两个数据框中的关联字段取交集进行连接操作,而左(右)连接则是以左(右)边的数据框关联字段为基准的连接操作,示例代码如下:
import pandas as pd
#定义两个字典
dict1={'code':['A01','A01','A01','A02','A02','A02','A03','A03'],
'month':['01','02','03','01','02','03','01','02'],
'price':[10,12,13,15,17,20,10,9]}
dict2={'code':['A01','A01','A01','A02','A02','A02'],
'month':['01','02','03','01','02','03'],
'vol':[10000,10110,20000,10002,12000,21000]}
#对两个字典转换为数据框
df1=pd.DataFrame(dict1)
df2=pd.DataFrame(dict2)
del dict1,dict2
df_inner=pd.merge(df1,df2,how='inner',on=['code','month'])#内连接
df_left=pd.merge(df1,df2,how='left',on=['code','month']) #左连接
df_right=pd.merge(df1,df2,how='right',on=['code','month']) #右连接
执行结果如图所示(下)。