
本章介绍了Python数据处理与分析中最重要的包:Pandas,包括Pandas包的导入及使用方法,Pandas包中两个非常重要的数据结构序列(Series)和数据框(DataFrame),以及相关的数据访问、切片及计算。值得注意的是读者需要掌握数据框、序列和Numpy数组之间的关系。从数据框中取出一列,它变为序列,取序列中的values属性得到序列的值,它其实是Numpy数组。从数据框中切片出来多个数据列,它仍然是数据框。取数据框中的values属性得到数据框中的元素值,它是一个Numpy数组。如果数据框中的元素是纯数值类型,可以通过函数as_matrix()直接转换为Numpy数组,这样在进行计算和使用时更加方便。同时我们还应该注意数据框与外部文件的读写,特别是Excel、CSV文件,它为数据报表的产生提供了极大的便利。在程序编写过程中,我们还应该注意不同数据类型之间的转换。例如,通过字典可以转换为数据框,其中字典的键转化为数据框中的列名,字典的值转化为数据框中的元素值,而字典的值可以是列表或者数组。这样就实现了列表、字典、数组、序列、数据框等各种数据类型和数据结构之间的相互转化,从而完成各种计算任务。事实上,不同数据结构之间的相互转化也是一种非常重要的编程技能和应用技巧,后续在案例篇中会有具体应用,请读者们注意领会。在本章的最后还介绍了 Pandas 包中外部文件的读取方法和如何利用Pandas包中的函数完成数据计算与整合任务。Pandas包的内容非常丰富,本章只是介绍了基本内容,更多的内容请查找相关文献或者借助网络资源进行学习。
#python数据分析必备工具 pandas - Dataframe
"""
Dataframe 是一个表格型的数据结构 ###带有标签的二维数组 index(行标签)
columns(列标签)
"""
#创建
"""
1. 由数组/list组成的字典:
columns 如果多添加,返回NaN ;少添加,只显示添加的列
index则必须和数据行数保持一致
data1={'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]}
d1=pd.DataFrame(data1,index=[]) ###columns 为字典的key
d1
a b c
0 1 4 7
1 2 5 8
2 3 6 9
2.由Series组成的字典创建:
data1={'a':pd.Series(np.random.rand(2)),'b':pd.Series(np.random.rand(3)),'c':pd.Series(np.random.rand(2))}
d1=pd.DataFrame(data1)
columns为字典的key ,index为Series的标签(若未指定标签,采用默认index)
Series的长度可以不一样,会用NaN自动补齐
3. 通过二维数组之间创建:
ar=np.random.rand(9).reshape(3,3)
df1=pd.DataFrame(ar,index=['a','b','c'],columns=[1,2,3])
index与columns指定长度与原数组保持一致
4.由字典组成的列表
data=[{'one':1,'two':2},{'a':5,'b':8,'c':6}] ####每个字典就是一行数据 , 字典的key为columns
df1=pd.DataFrame(data)
5. 由字典组成的字典:
data={'a':{1:'A'},'b':{2:'B'}}
df1=pd.DataFrame(data) ####外层字典key a,b为columns; 内层字典key 1,2为index
"""
# 索引
"""
1.选择列:
data1={'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]}
d1=pd.DataFrame(data1)
d1['a'] ##返回类型为Series
d1[['a','b']] ##返回类型为DataFrame
####df[列]
2.选择行:
data=d1.loc['0'] ##返回类型为Series
data=d1.loc[['0','1']] ##返回类型为DataFrame
data=d1.loc[[0:2]] ##切片索引 [0,2] 末端包含
data=d1.iloc[] ###按照整数位置选择行,相当于列表索引
3.布尔值索引:
b1=df<20
df[b1] | df[df<20] ##保留所有为True的值,其它均为NaN
df[df['a']>50] ## 单列值判断 a列中数值大于50
df.loc[['one','two']]>50 ##多行判断
4. 多重索引:
df['a'].loc[['three','four']]
"""
#函数
"""
1.数据查看,转置
df.head() ##默认5条
df.tail()
df.T ##转置
2. 添加与修改:
df['a']=1
df.loc['one']=2
df.drop() ##删除
3.排序:
按值排序
df.sort_values(['列名'],ascending=True) 默认升序
df.sort_values(['a','c']) ##多列排序 先对a进行排序,再在a排序后的基础上对c进行排序 **注意**:适用于a中的多个重复值
df.sort_index() ##按照索引排序
函数 描述
count 统计非空值数量
sum 汇总值
mean 平均值
mad 平均绝对偏差
median 算数中位数
min 最小值
max 最大值
mode 众数
abs 绝对值
prod 乘积
std 贝塞尔校正的样本标准偏差
var 无偏方差
sem 平均值的标准误差
skew 样本偏度 (第三阶)
kurt 样本峰度 (第四阶)
quantile 样本分位数 (不同 % 的值)
cumsum 累加
cumprod 累乘
cummax 累积最大值
cummin 累积最小值
cumsum() 与 cumprod() 等方法保留 NaN 值的位置
最大值与最小值对应的索引
Series 与 DataFrame 的 idxmax() 与 idxmin() 函数计算最大值与最小值对应的索引
多行或多列中存在多个最大值或最小值时,idxmax() 与 idxmin() 只返回匹配到的第一个值的 Index
values_counts() ##返回一个包含唯一值的统计个数
"""
示例:
# 代码 4-5
df = pd.read_excel('20大数据1班_统计.xlsx')
# 描述性统计方法
df1=df['综合成绩']
print('20大数据1班_学生(线上)综合成绩 描述性统计数据:\n ')
print('最小值: \n',np.min(df1))
print('最大值: \n',np.max(df1))
print('平均值: \n',np.mean(df1))
print('中位数: \n',np.median(df1))
print('标准差: \n',np.std(df1))
print('方 差: \n',np.var(df1))
df2=pd.Series(df1)
print('极 差: \n',np.ptp(df2)) # np.ptp 仅适用于Series.
print("-"*50)
print('众 数: ',df1.mode())
print('样本偏差: ',df1.skew())
print('样本峰值: ',df1.kurt())
print('四分位数: ',df1.quantile())
print('非空值数目: ',df1.count())
print('平均绝对离差: ',df1.mad())
实训题
第一题 创建一个Python脚本,命名为test1.py,完成以下功能:
读取以下4位同学的成绩并用一个数据框变量pd来保存,其中成绩保存在一个TXT文件中,如下图所示:
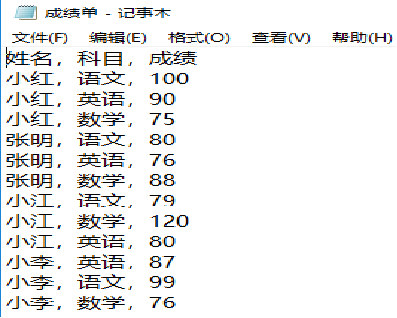
pd进行切片操作,分别获得小红、张明、小江、小李各科成绩,它们是4个数据框变量,分别记为pd1、pd2、pd3、pd4。
第二题 利用数据框中自身的聚合计算方法,计算并获得每个同学各科成绩的平均分,记为M1、M2、M3、M4。
创建一个Python脚本,命名为test2.py,完成以下功能:
读取以下Excel表格数据并用一个数据框变量df来保存,数据内容如下表所示:
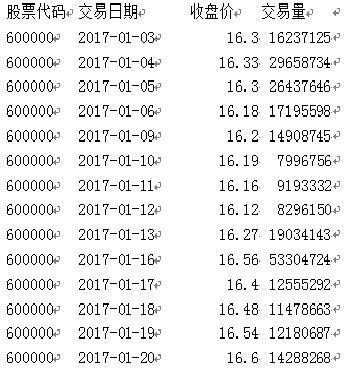
对df第3、4列进行切片,切片后为一个新的数据框记为df1,并对df1利用自身的方法转换为Numpy数组Nt。
基于df第2列,构造一个逻辑数组TF,即满足交易日期小于等于2017-01-16且大于等于2017-01-05为真,否则为假。
以TF为索引,取Nt中的第2列交易量数据并求和,记为S。

