
练习习题及解答(参考)
一.单选题
1#阅读下面代码
import numpy as np
arr = np.arange(12) # 创建一维ndarray
print('创建的一维ndarray arr为:', arr)
arr1 = arr.reshape(3, 4) # 设置ndarray的维度
print('改变形状后的ndarray arr1为:\n', arr1)
print('形状改变后ndarray arr1的维度为:', arr1.ndim)
下面叙述不正确的是:( )
正确答案: A
2.已知:arr = np.arange(12) # 创建一维ndarray
下面有关重新设置shape属性的方法,错误的是:( )
正确答案: C
3. Pandas的常用类不包括( )。
正确答案: D
4. Series 能够接收的数据类型不包括( )。
正确答案: D
5.关于Series 索引方式错误的是( )。
正确答案: D
6.删除DataFrame数据的方法不包括( )。
正确答案: D
7.关于索引对象,下列说法错误的是( )。
通过numpy的ndarray创建:必须是一维数组,且数组大小和索引大小要一致;
C、通过字典创建:默认索引为字典的关键字,指定索引时,会以索引为键获取值,没有值时,默认为NaN;通过标量创建 :重复填充标量到每个索引上;
正确答案: D
8.关于loc方法、iloc方法的说法不正确的是( )。
A、loc方法是基于名称的索引方法,它接收索引名称(标签),若索引名称不存在则会报错。loc方法也能够接收整数,但这个整数必须是已存在的索引名称。
loc方法的基本语法格式为:DataFrame.loc[行索引名称或条件,列索引名称]
C、loc方法可以像基础索引方式一样访问数据子集。行索引在前,列索引在后,整行或整列用“:”代替,当只查看行数据时“:”可以省略。
print('DataFrame中col1列数据为:\n', df.loc[: , 'col1'])
print('DataFrame中col1列、col2数据为:\n', df.loc[: , ['col1', 'col2']])
D、loc方法接收多种输入形式,输入形式包括单个索引名称、索引名称组成的list、名称切片、bool类型的数据(Series、list或array)、包含一个参数的函数这5种。
print('DataFrame中col1列大于0的数据为:\n', df.loc[df['col1'] > 0, :])
print('DataFrame中col1列大于0的数据为:\n', df.loc[lambda df: df['col1'] > 0, :])
使用iloc方法访问DataFrame的数据子集,基本用法与loc方法类似,行在前,列在后,它们的主要区别有两个。
loc方法传入的是索引名称,而iloc方法限定为是索引位置。
loc方法传入的行索引名称如果为一个区间,那么前后均为闭区间,而iloc方法为前闭后开区间。
类似loc方法,iloc方法也允许多种输入形式,输入形式包括单个int、int组成的list、int切片、bool类型的数据(list或array)、包含一个参数的函数这5种。
print('DataFrame中col1列大于0的数据为:\n', df.iloc[df['col1'].values>0, :])
print('DataFrame中col1列大于0的数据为:\n', df.iloc[lambda df: df['col1'].values>0, :])
正确答案: B
9. pandas提供merge函数用于主键合并,其基本语法格式如下:
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)
merge函数常用的参数及其说明如下:
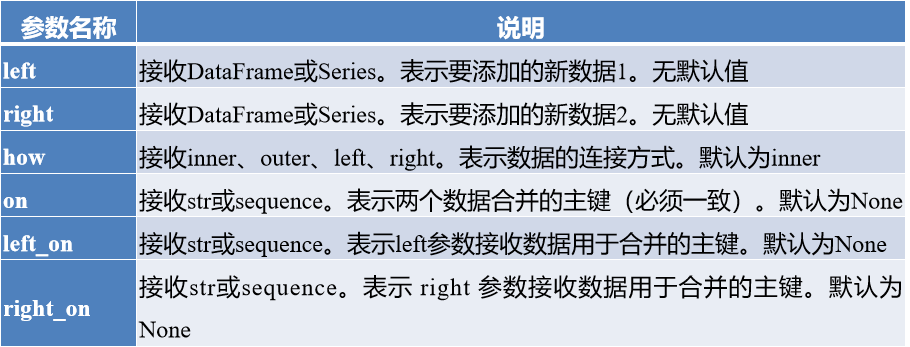

下列说法错误的是( )。
正确答案: D
10.关于pandas库的文本操作,下列说法错误的是( )。
附相关参考资料:
通过str属性访问Series的文本方法,其基本语法格式如下:
pandas.Series.str.文本处理方法
访问upper方法,将Series各元素转换为大写,例:
series3 = pd.Series(['a', 'abb', 'Ab12'])
print('大写后的Series为:\n', series3.str.upper())
部分文本处理方法与Python内建的str数据类型的方法不同,它们是特有的,如下表所示:
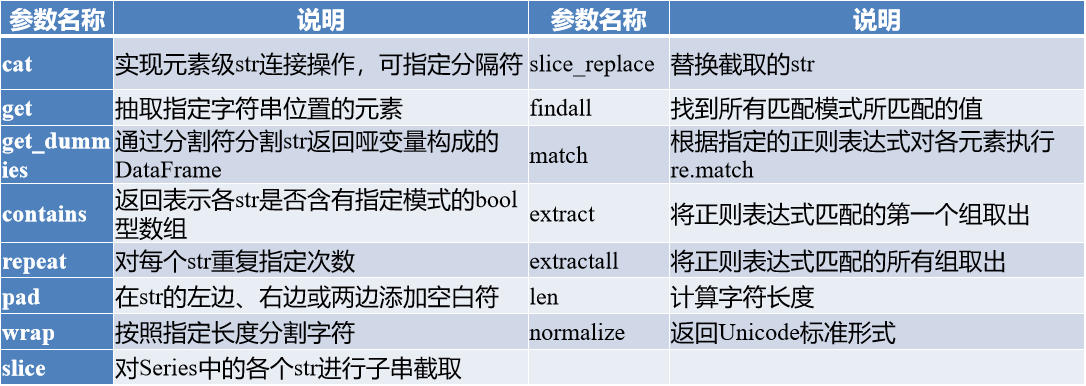
正确答案: D
11. NumPy提供了两种基本对象:( )。其余的对象都是以这两种对象为基础(如矩阵)。
正确答案: B
二.多选题
1.下面叙述正确的有( )。
print('rand函数生成的服从均匀分布的随机数ndarray为:\n', A)
程序的功能是:用rand函数生成10行5列的服从均匀分布的随机数ndarray A,并输出A。
arr1= np.matrix([[1,2,3],[12,12,5]])
arr2= np.matrix([[8,7],[6,5]])
C、A= np.matrix([[3,-1],[-1,3]])
eigenvalue,featurevector=np.linalg.eig(A)
print('特征值为:',eigenvalue,'\n特征向量为:',featurevector)
arr = np.arange(20).reshape(4, 5)
print('创建的ndarray arr为:\n', arr)
print('ndarray arr各元素的和为:', np.sum(arr))
print('ndarray arr各行的极差为:', np.ptp(arr, axis=1))
print('ndarray arr各列的均值为:', np.mean(arr, axis=0))
print('ndarray arr的中位数为:', np.median(arr))
print('ndarray arr各行的上四分位数为:', np.percentile(arr, 75, axis=1))
print('ndarray arr各列的下四分位数为:', np.percentile(arr, 25, axis=0))
print('ndarray arr的标准差为:', np.std(arr))
print('ndarray arr的方差为:', np.var(arr))
print('ndarray arr的最小值为:', np.min(arr))
print('ndarray arr的最大值为:', np.max(arr))
正确答案: ACD
2.关于时间相关类,下列说法正确的是( )。
参考材料:日期或时间等时间类型数据在金融、经济等领域用途十分广泛。pandas提供多种时间类,最基本的是Timestamp、Timedelta和Period,它们是单个时间标量,由它们可以组成时间Series和时间索引。
基本时间类的说明,如下表所示:
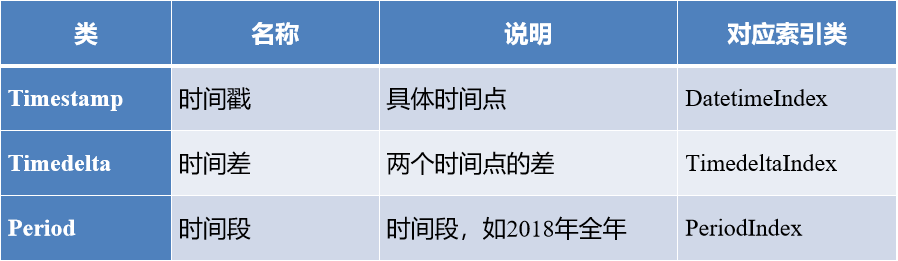
正确答案: ABC
3.阅读 下面Python程序:
# numpy示例py01
import numpy as np
a=np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
for i in a:
print(i,end=',')
print()
#输出结果:
b=list(range(10))
print(b)
#输出结果:
选择回答下面问题(哪两个是正确的):
正确答案: AD
4.## numpy示例py03
import numpy as np
import random
prize=[round(random.uniform(10.0,20.0),2) for i in range(10)]
prize_np=np.array(prize)
#查看数据类型
print('数据类型',prize_np.dtype)
# 输出结果
a=np.arange(10)
print('数据类型',a.dtype)
# 输出结果
# 获取长度
print('数组长度',a.size)
#输出 数组长度 10
#取数组的纬度,返回的是元组,多维数组就可以看到效果
b=np.array([[5,4,23],[1,6,23]])
print('数组:\n',b)
print('数组的纬度(或者说形状)',b.shape)
# (2, 3) 两行三列
# 返回维度值
print('a 的维度值',a.ndim)
print('b 的维度值',b.ndim)
下面选项(输出及说明)哪些是正确的
A、print('数据类型',prize_np.dtype)
正确答案: ABCD
5.## numpy 示例 py016
import numpy as np
import random
#创建ndarray
a=np.arange(10,20) #步长为1
print(a)
print()
# array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19)
b=np.arange(10,100,20) #步长为20
print(b)
print()
# array([10, 30, 50, 70, 90])
# 强大的小数步长(普通的range是不支持的)
c=np.arange(80,100,2.5)
print(c)
下面哪些选项(输出结果及注释说明)是正确的。
[10 11 12 13 14 15 16 17 18 19]
[80. 82.5 85. 87.5 90. 92.5 95. 97.5]
B、print(a)
# 输出的结果是:[10 11 12 13 14 15 16 17 18 19]
C、print(b)
# 输出的结果是: [80 82.5 85.0 87.5 90. 92.5 95. 97.5]
正确答案: ABD
三.判断题
1. 语句: print('布尔型数据True转换为浮点数的结果为:', np.float32(True)) 中, np.float32(True)的值是: 1.0
正确答案: √
2.语句: print('布尔型数据False转换为整型的结果为:', np.int16(False)) 中,
np.int16(False)的值是: 0
正确答案: √
3. 语句: arr1 = np.array([1, 2, 3, 4,5,6])
创建的arr1是一维ndarray。
正确答案: √
4.语句:
arr2 = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]])
创建的arr2是三维ndarray。
正确答案: ×
5.category类型在pandas中是和string,int等类型并列的一种数据类型,中文翻译可以理解为分类。
即某些数据的分类可以是有限的。例如:人类只有男性和女性,硕士分为研究生和博士等等。
例:我们开始构建pandas创建category类型的两种方法。
"""
创建series时,直接指定为category类
"""
import pandas as pd
import numpy as np
s = pd.Series(["a", "b", "c", "a"], dtype="category")
print(s)
运行程序,输出结果是:
0 a
1 b
2 c
3 a
dtype: category
Categories (3, object): ['a', 'b', 'c']
正确答案: √
6. 直接将dataFrame中的某一列指定为category
df = pd.DataFrame({"A": ["a", "b", "c", "a"]})
df["B"] = df["A"].astype('category')
print(df["B"])
运行程序,输出的结果是:
0 a
1 b
2 c
3 a
Name: B, dtype: category
Categories (3, object): ['a', 'b', 'c']
正确答案: √
7.NumPy是高性能科学计算和数据分析的基础包。它是pandas等其他各种工具的基础。
正确答案: √

