数据库原理与应用技术
-
1.1前 言
-
1.2第1章 数据库系统概论
-
1.2.11.1 数据库系统概述
-
1.2.1.11.1.1 数据、信息与数据处理
-
1.2.1.21.1.2 数据库系统的概念
-
1.2.1.31.1.3 数据管理技术的发展
-
1.2.21.2 数据模型
-
1.2.2.11.2.1 数据的三个范畴
-
1.2.2.21.2.2 数据模型
-
1.2.2.31.2.3 E-R模型
-
1.2.2.41.2.4 面向对象数据模型
-
1.2.31.3 数据库系统的组成
-
1.2.41.4 数据库的系统结构
-
1.2.4.11.4.1 数据库系统的模式结构
-
1.2.4.21.4.2 数据库系统的体系结构
-
1.2.4.31.4.3 DBMS
-
1.2.4.41.4.4 数据库语言
-
1.2.4.51.4.5 数据字典
-
1.2.4.61.4.6 DBMS的工作流程
-
1.2.51.5 数据库技术的研究领域
-
1.2.5.11.5.1 DBMS软件的研制
-
1.2.5.21.5.2 数据库设计
-
1.2.5.31.5.3 数据库理论
-
1.2.61.6 数据库技术的发展趋势
-
1.2.6.11.6.1 数据库技术与其他相关技术的结合
-
1.2.6.21.6.2 面向应用领域的数据库新技术
-
1.2.71.7 小结
-
1.2.8思 考 题
-
1.3第2章 关系数据库
-
1.3.12.1 关系模型概述
-
1.3.1.12.1.1 关系的基本概念
-
1.3.1.22.1.2 关系的完整性规则
-
1.3.22.2 关系代数
-
1.3.2.12.2.1 传统的集合运算
-
1.3.2.22.2.2 特殊的关系运算
-
1.3.2.32.2.3 扩充的关系运算
-
1.3.32.3 关系演算
-
1.3.3.12.3.1 元组关系演算
-
1.3.3.22.3.2 域关系演算
-
1.3.42.4 小结
-
1.3.5思 考 题
-
1.4第3章 关系数据库设计理论
-
1.4.13.1 问题的提出
-
1.4.23.2 数据依赖
-
1.4.2.13.2.1 属性间的联系
-
1.4.2.23.2.2 函数依赖
-
1.4.2.33.2.3 关键字
-
1.4.33.3 规范化理论
-
1.4.3.13.3.1 第一范式
-
1.4.3.23.3.2 第二范式
-
1.4.3.33.3.3 第三范式
-
1.4.3.43.3.4 BCNF
-
1.4.43.4 小结
-
1.4.5思 考 题
-
1.5第4章 数据库设计
-
1.5.14.1 信息系统
-
1.5.24.2 数据库设计概述
-
1.5.2.14.2.1 数据库设计的内容
-
1.5.2.24.2.2 数据库设计的特点
-
1.5.2.34.2.3 数据库设计的方法
-
1.5.2.44.2.4 数据库设计工具
-
1.5.2.54.2.5 数据库设计的基本步骤
-
1.5.34.3 需求分析
-
1.5.3.14.3.1 需求分析的任务
-
1.5.3.24.3.2 需求分析的基本步骤
-
1.5.3.34.3.3 需求分析案例:学院教学管理系统
-
1.5.44.4 概念模型设计
-
1.5.4.14.4.1 概念模型设计的方法
-
1.5.4.24.4.2 数据抽象
-
1.5.4.34.4.3 概念模型设计的步骤
-
1.5.4.44.4.4 概念模型设计案例:学院教学管理数据库
-
1.5.54.5 逻辑结构设计
-
1.5.5.14.5.1 概念模型向关系模型的转换
-
1.5.5.24.5.2 关系模式的优化
-
1.5.5.34.5.3 设计用户子模式
-
1.5.5.44.5.4 逻辑结构设计案例:学院教学管理数据库
-
1.5.64.6 数据库的物理设计
-
1.5.6.14.6.1 物理设计的内容
-
1.5.6.24.6.2 索引设计
-
1.5.6.34.6.3 聚簇设计
-
1.5.6.44.6.4 物理设计案例:学院教学管理数据库
-
1.5.74.7 数据库的实施与维护
-
1.5.7.14.7.1 数据库实施
-
1.5.7.24.7.2 数据库运行维护
-
1.5.84.8 小结
-
1.5.9思 考 题
-
1.6第5章 关系数据库标准语言SQL
-
1.6.15.1 SQL概述
-
1.6.1.15.1.1 SQL的特点
-
1.6.1.25.1.2 SQL的数据类型
-
1.6.25.2 数据定义
-
1.6.2.15.2.1 定义、删除与修改基本表
-
1.6.2.25.2.2 建立与删除索引
-
1.6.35.3 查询
-
1.6.3.15.3.1 SELECT语句的一般格式
-
1.6.3.25.3.2 单表查询
-
1.6.3.35.3.3 连接查询
-
1.6.3.45.3.4 嵌套查询
-
1.6.3.55.3.5 集合查询
-
1.6.45.4 数据更新
-
1.6.4.15.4.1 插入数据
-
1.6.4.25.4.2 修改数据
-
1.6.4.35.4.3 删除数据
-
1.6.55.5 视图
-
1.6.65.6 数据控制
-
1.6.6.15.6.1 授权
-
1.6.6.25.6.2 收回权限
-
1.6.75.7 小结
-
1.6.8思 考 题
-
1.7第6章 数据库保护
-
1.7.16.1 数据库的恢复
-
1.7.1.16.1.1 事务的概念
-
1.7.1.26.1.2 事务的性质
-
1.7.1.36.1.3 故障类型和恢复方法
-
1.7.1.46.1.4 恢复的基本原则和实现方法
-
1.7.1.56.1.5 运行记录优先原则
-
1.7.1.66.1.6 SQL中的恢复操作
-
1.7.26.2 数据库的并发控制
-
1.7.2.16.2.1 数据库并发操作带来的问题
-
1.7.2.26.2.2 排他型封锁
-
1.7.2.36.2.3 活锁与死锁
-
1.7.2.46.2.4 共享型封锁
-
1.7.2.56.2.5 两段封锁法
-
1.7.36.3 数据库的完整性
-
1.7.3.16.3.1 完整性子系统
-
1.7.3.26.3.2 完整性规则
-
1.7.3.36.3.3 SQL中的完整性约束
-
1.7.46.4 数据库的安全性
-
1.7.4.16.4.1 安全性级别
-
1.7.4.26.4.2 权限
-
1.7.4.36.4.3 权限的转授与回收
-
1.7.4.46.4.4 SQL中的安全性控制
-
1.7.4.56.4.5 数据加密法
-
1.7.4.66.4.6 自然环境的安全性
-
1.7.56.5 小结
-
1.7.6思 考 题
-
1.8第7章 SQL Server数据库管理系统简介
-
1.8.17.1 SQL Server配置管理器
-
1.8.1.17.1.1 服务管理
-
1.8.1.27.1.2 网络配置及协议
-
1.8.1.37.1.3 客户端配置
-
1.8.27.2 SQL Server Management Studio
-
1.8.2.17.2.1 启动SSMS
-
1.8.2.27.2.2 SQL Server集成服务
-
1.8.2.37.2.3 SQL Server Profiler
-
1.8.2.47.2.4 sqlcmd
-
1.8.2.57.2.5 PowerShell
-
1.8.2.67.2.6 联机丛书
-
1.8.37.3 小结
-
1.8.3.1思 考 题
-
1.9第8章 数据库与数据表
-
1.9.18.1 创建数据库
-
1.9.1.18.1.1 用T-SQL命令创建数据库
-
1.9.1.28.1.2 查看数据库信息
-
1.9.28.2 管理数据库
-
1.9.2.18.2.1 打开数据库
-
1.9.2.28.2.2 增加数据库容量
-
1.9.2.38.2.3 查看及修改数据库的选项设定
-
1.9.2.48.2.4 压缩数据库容量
-
1.9.2.58.2.5 更改数据库名称
-
1.9.2.68.2.6 数据库的删除
-
1.9.38.3 数据库中数据表的操作
-
1.9.3.18.3.1 SQL Server的数据类型
-
1.9.3.28.3.2 创建数据表
-
1.9.3.38.3.3 修改表的结构
-
1.9.3.48.3.4 删除表的定义
-
1.9.48.4 小结
-
1.9.5思 考 题
-
1.10第9章 SQL Server的高级应用
-
1.10.19.1 T-SQL程序设计
-
1.10.1.19.1.1 T-SQL程序结构
-
1.10.1.29.1.2 常量与变量
-
1.10.1.39.1.3 运算符
-
1.10.1.49.1.4 流控制命令
-
1.10.1.59.1.5 常用函数
-
1.10.1.69.1.6 游标
-
1.10.29.2 存储过程
-
1.10.2.19.2.1 存储过程概述
-
1.10.2.29.2.2 创建和执行存储过程
-
1.10.2.39.2.3 查看存储过程
-
1.10.2.49.2.4 修改存储过程
-
1.10.2.59.2.5 删除存储过程
-
1.10.39.3 用户定义函数
-
1.10.3.19.3.1 用户定义函数概述
-
1.10.3.29.3.2 创建和执行用户定义函数
-
1.10.3.39.3.3 查看用户定义函数
-
1.10.3.49.3.4 修改用户定义函数
-
1.10.3.59.3.5 删除用户定义函数
-
1.10.49.4 触发器
-
1.10.4.19.4.1 触发器概述
-
1.10.4.29.4.2 创建触发器
-
1.10.4.39.4.3 查看触发器
-
1.10.4.49.4.4 修改触发器
-
1.10.4.59.4.5 删除触发器
-
1.10.59.6 小结
-
1.10.6思 考 题
-
1.11第10章 SQL Server的安全管理
-
1.11.110.1 SQL Server安全认证模式
-
1.11.1.110.1.1 身份验证
-
1.11.1.210.1.2 权限认证
-
1.11.1.310.1.3 设置安全验证模式
-
1.11.210.2 服务器管理的安全性
-
1.11.2.110.2.1 服务器管理安全性概述
-
1.11.2.210.2.2 服务器角色
-
1.11.2.310.2.3 管理数据库的用户
-
1.11.310.3 管理权限
-
1.11.3.110.3.1 SQL Server的权限
-
1.11.3.210.3.2 权限设置
-
1.11.410.4 应用程序的安全管理
-
1.11.510.5 小结
-
1.11.6思 考 题
-
1.12第11章 备份与还原
-
1.12.111.1 备份与还原概述
-
1.12.1.111.1.1 备份与还原需求分析
-
1.12.1.211.1.2 数据库备份的基本概念
-
1.12.1.311.1.3 数据库还原的概念
-
1.12.211.2 备份操作和备份命令
-
1.12.2.111.2.1 创建备份设备
-
1.12.2.211.2.2 备份命令
-
1.12.2.311.2.3 使用SSMS进行备份
-
1.12.2.411.2.4 使用备份向导进行备份
-
1.12.311.3 还原操作与还原命令
-
1.12.3.111.3.1 检查点
-
1.12.3.211.3.2 数据库的还原命令
-
1.12.3.311.3.3 使用SSMS还原数据库
-
1.12.411.4 小结
-
1.12.5思 考 题
-
1.13参考文献
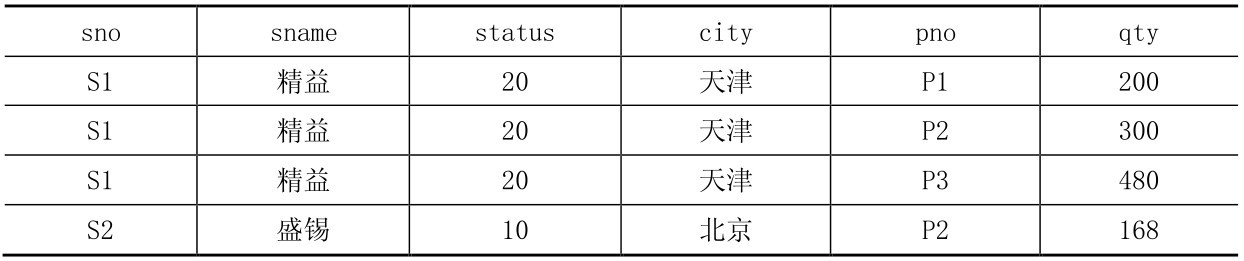
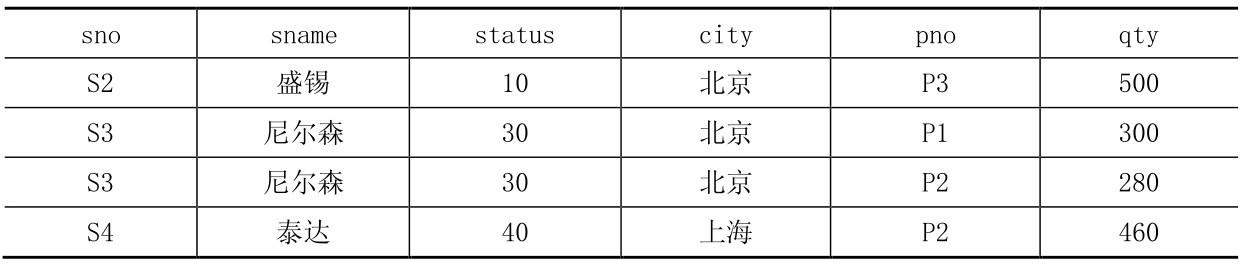
 status。
status。