高速缓冲存储器
Cache是一种高速缓冲存储器,是为了解决CPU和主存之间速度不匹配而采用的一项重要技术。
访问局部性原理:
在程序执行过程中, 处理器访问存储器中的指令和数据倾向于成块进行。 程序通常包含许多迭代循环和子程序,一旦进入了一个循环或子程序, 则需要重复访问一小组指令, 同样, 对于表和数组的操作, 包含存取一块块的数据字。 在一长段时间内, 使用的块是变化的, 而在一个小段时间内, 处理器主要访问存储器中的固定块。
功能
cache是一种高速缓冲存储器,是为了解决CPU和主存之间速度不匹配而采用的一项重要技术。cache是介于CPU和主存之间的小容量存储器,但存取速度比主存快。
基本原理
Cache和主存都被分成若干个大小相等的块,每块由若干字节组成。由于cache的容量远小于主存的容量,所以cache中的块数要远小于主存的块数,它保存的信息只是主存中最急需执行的若干块的副本。
CPU与Cache之间的数据交换是以块为单位的。当CPU读取主存中一个字时,便发出此字的内存地址到CACHE和主存。此时CACHE控制逻辑依据地址判断此字当前是否在CACHE 中,若是,为命中,此字立即传送给CPU;若非,为不命中则用主存读周期把此字从内存读出送到CPU,与此同时,把含由这个字的整个数据块从主存读出送到CACHE中。

图5.4-1 Cache 原理图
命中率
在一个程序执行期间,设Nc表示完成存取的总次数,Nm表示主存完成存取的总次数,h定义为命中率。则有:

 若tc表示命中时的CACHE访问时间,tm表示未命中时的主存访问时间,1-h表示未命中率,则CACHE/主存系统的平均访问时间ta为:
若tc表示命中时的CACHE访问时间,tm表示未命中时的主存访问时间,1-h表示未命中率,则CACHE/主存系统的平均访问时间ta为:

例如:CPU执行一段程序时,cache完成存取的次数为1900此,主存完成存取的次数为100次,已知cache存取周期为50ns,主存存取后期为250ns,求cache/主存系统的效率和平均访问时间。

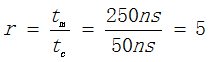

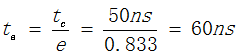
地址映射
为了把主存块放到cache中,必须应用某种方法把主存地址定位到cache中,称作地址映射。主要方式有:直接映射方式、相联映射方式、组相联映射方式。
Cache的数据块的大小称为行,用Li表示,其中i=0,1,2,…m-1,共有m=2r行。主存的数据块大小称为块,用Bj表示,其中j=0,1,2,…n-1,共有n=2s块。行与块是等长的,每个块(行)是由k=2w个连续的字组成,字是CPU每次访问存储器时可存取的最小单位。
全相联映射方式
在全相联映象中,主存中任一个块能够映象到Cache中任意一个块的位置。将主存中的一个块的地址(块号)与块的内容(字)一起存于cache的行中,其中块地址存于cache行的标记部分中。
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,Cache的行数=不由地址格式确定,标记大小=s位
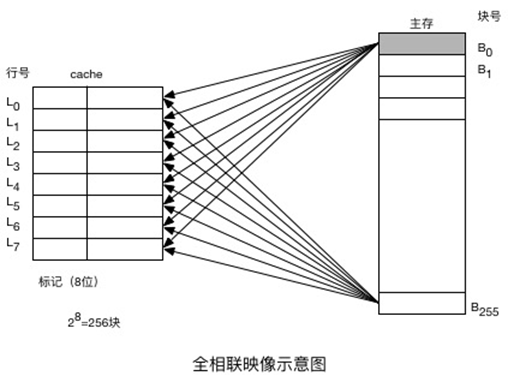
(a)全相联映射示意图
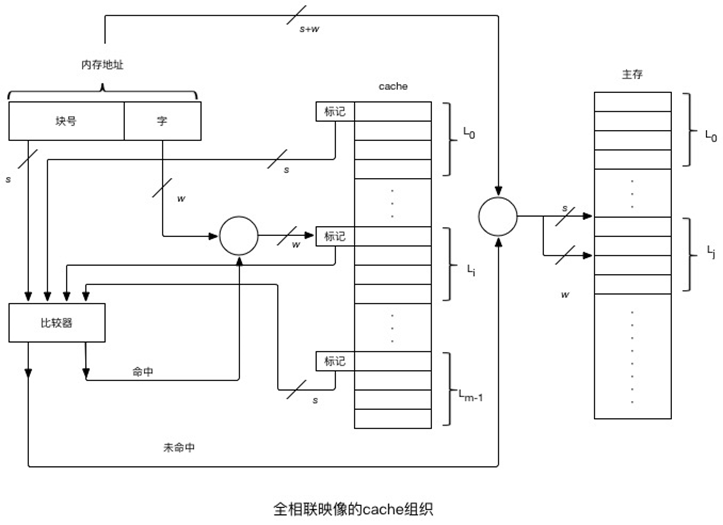
(b)全相联cache的检索过程
图5.4-2 全相联映射的cache组织
检索过程:CPU访存指令制定了一个内存地址(包括主存和cache),为了快速检索,指令中的块号与cache中所有行的标记同时在比较器中进行比较。如果块号命中,则按字地址从cache中读取一个字;如果块号未命中,则按内存地址从主存中读取这个字。
全相联方式的主要缺点是比较器电路难于设计和实现,因此只适合小容量cache采用。
直接映射方式
一种多对一的映射关系,一个主存块只能拷贝到cache一个特定行的位置上。
在直接映象Cache中, 地址被划分未标志、页号和偏移量。页号用于确定数据地址在Cache存储器中的物理位置。
直接映象方式:根据Cache的大小把主存分成若干个区,因此主存容量是Cache容量的若干倍。
i=j mod m
式中:m为cache的总行数
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,Cache的行数=m=2r,标记大小=(s-r)位。

(a)直接映射示意图

(b)直接映射cache的检索过程
图5.4-3 直接映射的cache组织
检索过程:Cache将s位的块地址分为两部分:r位作为cache的行地址,s-r位作为标记(tag)与块数据一起保存在该行。当CPU以一个给定的内存地址访问cache时,首先用r位行号找到cache中的此行,然后用地址中的s-r位标记部分与此行的标记在比较器中做比较;若相符即命中,在cache中找到所需要的块;而后用地址中的最低的w位读取所需要的字;若不符, 则未命中,有主存读取所需要的字。
直接映射方式的优点是硬件简单,成本低。缺点是每个主存块只有一个固定的行位置可存放。效率低下。直接映射方式适合于需要大容量cache的场合,更多的行数可以减少冲突的机会。
组相联映像
组相联映象提供了在性能和价格之间的一种良好平衡。组相联映象是直接映象和相联映象的结合。组内是全相联映象, 组间是直接映象。
这种方式将cache分为u组,每组v行。主存块存放到哪个组是固定的,至于存到该组的哪一行是灵活的,即有如下函数关系:
m=u ╳ v
组号 q=j mod u
块内存地址中 s 位块号划分成两部分:低序的d位(2d=u)用于表示cache组号,高序的s-d位作为标记(tag)与块数据一起存于此组的某行中。
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,每组的行数=k,第组的v=2d,Cache的行数=kv,标记大小=(s-r)位

(a)组相联映射示意图(4组)

(b)组相联cache的检索过程
图5.4-4 组相联的cache组织
cache的每一小框代表的不是“字”而是“行”。当CPU给定一个内存地址访问cache时,首先用块号域的低d位找到cache的相应组,然后将块号域的高s-d位与该组v行中的所有标记同时进行比较。哪行的标记与之相符,哪行即命中。此后再以内存地址的w位字域部分检索此行的具体字,并完成所需要求得存取操作。如果词组没有一行的标记与之相符,即cache未命中,次数需要按内存地址访问内存。
举例:
一个组相联cache由64个行组成,每组4行,主存储器包含4K个块,每块128个字,请表示内存地址的格式。
解:块大小=行大小=2w个字=128=27,所以w=7
每组的行数=k=4
Cache的行数=kv=K╳2d=4╳2d=64, 所以d=4
组数=v=2d=24=16
主存的块数=28=4K=22╳210=212,所以s=12
标记大小(s-d)位=12-4=8位
主存地址长度(s+w)位=12+7=19位
主存寻址单元数2s+w=219

替换策略和写策略
替换策略
当一个新的主存块需要拷贝到cache,而允许存放此块的行位置都被其他主存块占满时,就要产生替换。
常用的替换算法主要有以下三种:
(1)最不经常使用(LFU)算法
LFU算法认为应将一段时间内被访问次数最少的那行数据换出。
(2)近期最少使用(LRU)算法
LRU算法将近期内长久未被访问过的行换出。
(3)随机替换
从特定的行位置中随机地选取一行换出即可。
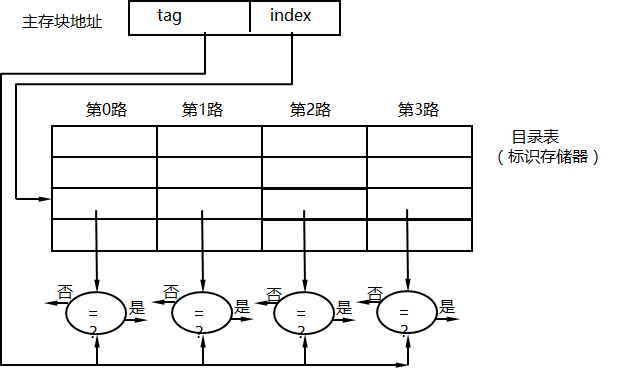
图5.4-5
Cache写
在Cache存储器与主存储器只能关键保持一致是很重要的。 一种方法是只写Cache,在页替换时再传送给主存。另一种方法是只要对缓存写操作, 就要同时写至主存中。有三种写操作策略:分别是写操作策略、写回法、全写法写一次法。
写回法:当CPU写CACHE命中时,只修改CACHE的内容,而不立即写入主存。只有当此行被换出时才写回主存。如果CPU写CACHE未命中,为了包含欲写字的主存块在CACHE分配一行,将此块整个拷贝到CACHE后对其进行修改。
全写法:当写CACHE命中时,CACHE与主存同时发生写修改,因而较好地维护了CACHE和主存内容的一致性。当写CACHE未命中时,只能直接项主存进行写入。
写一次法:写命中与写未命中的处理方法与写回法基本相同,指示第一次写命中时同时要写入主存。
程序局部性
一个编写良好的计算机程序常常具有良好的局部性(locality)。也就是,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向性, 被称为局都性原理( princple of locality),是一个持久的概念,对硬件和软件系统的设计都有极大的影响。
局部性通常有两种不同的形式:时间局部性( temporal locality)和空间局部性( spatial locality),在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来再被多次引用。在一个具有良好空间局部性的程序中,如果一个内存位置被引用了,那么程序很可能在不远的将来引用附近的一个内存位置。
程序员应该理解局部性原理, 因为一般而言, 有良好局部性的程序比局部性差的程序行得更快,现代计算机系统的各个层次,从硬件到操作系统、再到应用程序,它们的设计都利用了局部性。在硬件层,局部性原理允许计算机设计者通过引入称为高速缓存存储器的小而快速的存储器来保存最近被引用的指令和数据项,从而提高对主存的访问速度。在操作系统级,局部性原理允许系统使用主存作为虚拟地址空间最近被引用块的高速缓存。类似地,操作系统用主存来缓存磁盘文件系统中最近被使用的磁盘块。局部性原理在应用租序的设计中也扮演看重要的角色。例如,Web浏览器将最近被引用的文档放在次想盘上,利用的就是时间局部性,大容量的Web服务器将最近被请求的文档放在前端磁盘高速缓存中,这些缓存能满足对这些文档的请求,而不需要服务器的任何干预。
量化评价程序中局部性的一些简单原则为:
1. 重复引用相同变量的程序有良好的时间局部性。
2. 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好。具有步长为1的引用模式的程序有很好的空间局部性。在内存中以大步长跳来跳去的程序空间局部性会很差;
3. 对于取指令来说,循环有好的时间和空间局部性。循环体越小,循环选代次数越多, 局部性越好。
计算机高速缓冲存储器( Cache) 命中率的分析
从 Cache 的容量、空间逻辑组织结构的组大小、块大小、数据的替换算法和写入 Cache 的数据地址流对
Cache 命中率的影响进行分析,选择合适的参数可提高 Cache 的命中率,有效地提高计算机的运算速度.
关键词: 存储器; Cache 命中率; 组大小; 块大小; 替换算法
0 引言
提高计算机的存取速度除了从计算机硬件介质上解决外,更多的是从数据存取方法上不断地提出新的
方法. 处在计算机多级存储层次的计算机高速缓冲存储器( Computer Cache Memory,以下简称 Cache) ,直接
解决了 CPU 和主存速度不匹配的问题,Cache 的大小、容量的组织方式、访问方法等直接影响了 CPU 处理数
据的速度.
1 计算机存储器体系层的次结构介绍
计算机的存储体系是为了满足人们对计算机存储器“容量大、速度快、价格低”的要求而设计的. 存储体
系的层次结构如图 1 所示,其中 M1,M2,M3,…,Mn 为不同技术实现的存储器. 最靠近 CPU 的 M1 速度最快,
但单位存储容量的价格最高. Mn 离 CPU 最远,这一层的存储器速度最慢,容量最大,单位容量价格最低. 存
储体系在工作时,以块或者页面为单位进行数据传递. 对用户来说,使用计算机时,存储数据的速度接近 M1,
而存储容量相当于 Mn,整体的存储器的价格相对较低,这就满足了最初存储体系设计目的. 在当前的计算机
存储系统中,通常为三级存储器体系,即高速缓冲存储器( Cache) 、主存和外存.

图 1 存储器的层次结构
Fig. 1 Hierarchical structure of memory
2 高级缓冲存储器的工作原理
高级缓冲存储器是存在于 CPU 和主存之间的存
储体,用于弥补主存速度的不足. 从 CPU 看来,整个
存储体系的速度接近 Cache,而容量却接近主存. CPU
在取数据时,先从 Cache 中寻找数据,如果要找的数
据存在于 Cache 中,就称为命中,否则称为不命中. 命中的次数与总的访问次数的比称为命中率. 此时 CPU
把数据从 Cache 中取出进行处理. 如果没有在 Cache 中找到需要的数据,就直接到主存中查找,然后对找到
的数据进行处理,同时把这些数据回写到 Cache 中,以备下次使用时直接从 Cache 中取数据. 因为 Cache 的
存取速度比主存的存取速度高得多,所以提高了存储数据的速度. 如果 CPU 从 Cache 中查找数据的命中次
数提高,也就是命中率高,就可大大地提高计算机的存储速度,从而提高计算的性能.
3 影响 Cache 命中率的因素分析
Cache 命中率的高低主要与 Cache 中块的大小、组的大小、Cache 容量和 Cache 中数据的替换算法和地
址流的簇聚性有关.
3. 1 Cache 命中率与 Cache 容量的关系
如果 CPU 每次需要访问的数据都存在于 Cache 中,也就是每次访问 Cache 都命中,那么 Cache 的容量就
要足够大,如果容量达到和存储体系末端存储体的容量一样大,那么 CPU 每次都能在 Cache 中找到需要的数据,Cache 的命中率是 100% . 而事实上 Cache 的容量不可能有这么大,因为它违背了存储体系“容量大、速
度快、价格低”的设计中“价格低”的要求,目前市场上的计算机的 Cache 大小为几十 MB. 但我们可以看到,
Cache 容量的大小直接影响到 Cache 的命中率,命中率的大小与 Cache 的容量的关系如图 2 所示,Hc 为命中
率,s 为 Cache 的容量,它符合关系式:
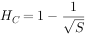
3. 2 Cache 命中率与 Cache 中块的大小的关系
为了存取方便,把 Cache 的存储空间分为若干大小相等的小空间,这些小的空间就称为块. 当 CPU 访问
Cache 时,查找需要的数据是否存在于块内,如果存在,则命中该块. 由于 Cache 的设计是基于存储器数据的局
部性而设计的,如果块的空间过小,存放数据过少,造成部分数据不存在,存储空间的局部性就没有得到很好
的利用,命中率就不会很高. 这样,当块达到一定大小的时候,块内存储的数据能满足 CPU 的需求,命中率就会
提高,当块的大小继续扩大时,Cache 内包括的总块数就会减少,这也降低了 CPU 对 Cache 块的命中率,所以存
在一个平衡点,在该平衡点附近,Cache 的命中率最高,命中率和块的大小关系如图 3 所示.
3. 3 Cache 命中率与 Cache 中组数的关系
Cache 中的组是指把 Cache 中的连续的块组合在一起,形成一个新的逻辑存储空间,这些空间就是称为
Cache 的组. 在 Cache 和主存映射关系中,组与组的映射关系是一种很重要的映射关系,也是存储体系实现
“容量大、速度快、价格低”的方法. 在组相连映射方式中,如果 Cache 的组数过多,就像块分得越多一样,组
的空间就会越小,直接映像的成分增加,映射到 Cache 中的块数减少,命中率下降; 反之,命中率增加.
3. 4 Cache 命中率与替换算法的关系
由于 Cache 的容量是有限的,主存中的内容不可能全部映射到 Cache 中,为了利用存储器数据的局部
性,采用一种方法把某时间段内常用的数据存放到 Cache 中,替换掉原来的数据,这就是 Cache 数据的替换
算法,常见的替换算法有随机法( Random,RAND) 、先进先出( First-In-First-Out,FIFO) 算法、最近最少使用
( Least Recently Used,LRU) 算法. 随机法没有固定规律可循,随机替换掉 Cache 中的数据,高的命中率很
难保证; 先进先出算法不能突出存储器数据的局部性,即使使用频率不高的数据也会被新调用的数据替换
掉,命中率也不会高; 最近最少使用算法最能突出存储器数据的局部性,在某一时段内,用新的数据把使用次
数最少的数据替换掉,这样 Cache 中存储的数据总是最近使用频率最高的数据,CPU 在调用数据时在 Cache
中找到的几率也会高,也就是命中率较高.
3. 5 Cache 命中率与地址流的关系
地址流是指写入 Cache 中的数据地址的集合. 在写入 Cache 的过程中,如果地址流具有局部性,即有些
数据反复写入 Cache,特别是在 LRU 替换方法下,具有较高局部性的地址流能够有效提高 Cache 的命中率.
如果地址流的数量过小,也就是 Cache 的块容量过大的情况下,就不能很好地体现出地址流的局部性,此时
Cache 的命中率就会降低. 所以地址流对 Cache 命中率的影响是在 Cache 的替换方法和块大小确定的情况下
才能够衡量.
通过以上分析,Cache 命中率和 Cache 容量的大小、组的大小、块的大小、替换算法和地址流的簇聚性都
有关系. 只有选择合适的参数,才能提高 Cache 的命中率,有效地提高计算机的运算速度
小结
Cache 命中率的高低直接影响到计算机处理数据的速度,不仅用逻辑方法从数据的处理上提高 Cache
的命中率,比如数据的替换方法等,还可以从物理上改进 Cache 存储器的存取速度,比如 Cache 的材质、存取
电路的改进等,从而进一步提高计算机的性能.
原文引自:第 21 卷 第 3 期 河南教育学院学报( 自然科学版) Vol. 21 No. 3
2012 年 9 月 Journal of Henan Institute of Education ( Natural Science Edition) Sep. 2012,计算机高速缓冲存储器( Cache) 命中率的分析
席红旗
( 河南教育学院 信息技术系,河南 郑州 450046


