SQL Server 中的数据类型
转载自:知乎 https://zhuanlan.zhihu.com/p/557455131?utm_id=0
一、字符串
(一)varchar(10)
变长字符串。例如,varchar(10) 的一个变量,虽然最多可以存 10个字节的内容,但是里面如果只存了2个字节,就只占用 2个字节的空间。
(二)char(10)
定长字符串。例如 char(10),里面最多可以存储 10个字节,且不论存了几个字节的数据,都要占用 10个字节的空间。
(三)text
长文本。用于存储几百几千几万字的文本。text虽然可以容纳很多内容,但是执行的效率会比varchar 和 char 低很多。
(四)nvarchar、nchar、ntext
varchar、char、text前面都可以加上n,变成存储 unicode 字符,对中文友好
例如 varchar(100) 可以存储 100个字母或者 50个汉字,但是 nvarchar(100) 可以存储 100个字母或者 100个汉字。
二、数值
本部分内容参考了:https://learn.microsoft.com/zh-cn/sql/t-sql/data-types/float-and-real-transact-sql?view=sql-server-ver15
(一)int、bigint、smallint 和 tinyint
使用整数数据的精确数字数据类型。 若要节省数据库空间,请使用能够可靠包含所有可能值的最小数据类型。 例如,对于一个人的年龄,tinyint 就足够了,因为没人活到 255 岁以上。 但对于建筑物的年龄,tinyint 就不再适应,因为建筑物的年龄可能超过 255 年。
| 数据类型 | 范围 | 范围表达式 | 存储 |
|---|
| bigint | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | -2^63 到 2^63-1 | 8 字节 |
| int | -2,147,483,648 到 2,147,483,647 | -2^31 到 2^31-1 | 4 个字节 |
| smallint | -32,768 到 32,767 | -2^15 到 2^15-1 | 2 字节 |
| tinyint | 0 到 255 | 2^0-1 到 2^8-1 | 1 字节 |
注意:
int 数据类型是 SQL Server 中的主要整数数据类型。bigint 数据类型用于整数值可能超过 int 数据类型支持范围的情况。
在数据类型优先次序表中,bigint 介于 smallmoney 和 int 之间 。
仅当参数表达式为 bigint 数据类型时,函数才返回 bigint。 SQL Server 不会自动将其他整数数据类型(tinyint、smallint 和 int)提升到 bigint。
(二)float 和 real
用于表示浮点数值数据的大致数值数据类型。 浮点数据为近似值;因此,并非数据类型范围内的所有值都能精确地表示。 real 的 ISO 同义词为 float(24) 。
float [ (n) ] 其中 n 为用于存储 float 数值尾数的位数(以科学记数法表示),因此可以确定精度和存储大小 。 如果指定了 n,则它必须是介于 1 和 53 之间的某个值 。 n 的默认值为 53 。
| n 值 | Precision | 存储大小 |
|---|
| 1-24 | 7 位数 | 4 个字节 |
| 25-53 | 15 位数 | 8 字节 |
SQL Server 将 n 视为下列两个可能值之一 。 如果 1<=n<=24,将 n 视为 24。 如果 25<=n<=53,将 n 视为 53。
SQL Server float[(n)] 数据类型从 1 到 53 之间的所有 n 值均符合 ISO 标准 。 double precision 的同义词是 float(53) 。
(三)decimal(12,2)
总长度为 12位,小数位数为 2位的小数。
三、日期和时间
(一)date
存储 年月日
(二)datetime
存储 年月日时分秒 。可以优先使用 datetime,有些低版本的数据库不支持date 类
(三)smalldatetime
比datetime 表示的时间范围小,但是效率高于 datetime 类型。
数据库和表的基本操作
转载自:知乎 https://zhuanlan.zhihu.com/p/542382649?utm_id=0
一、建库
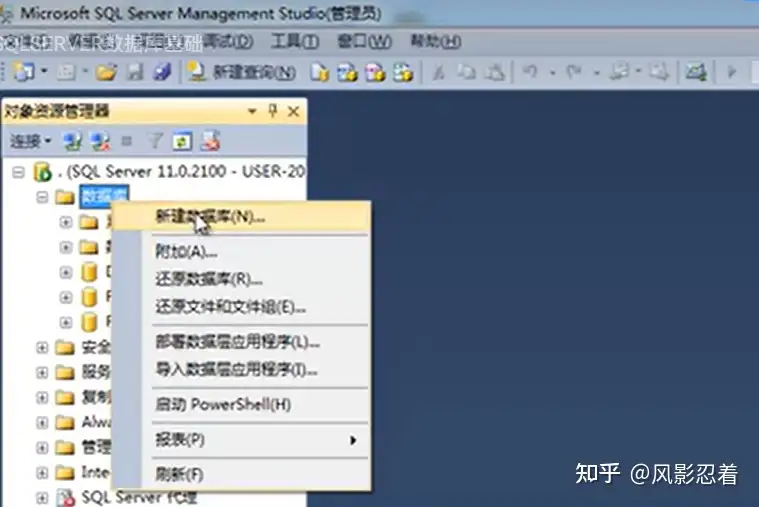
在数据库上面,右键,新建数据建库
注意,不要动系统数据库。
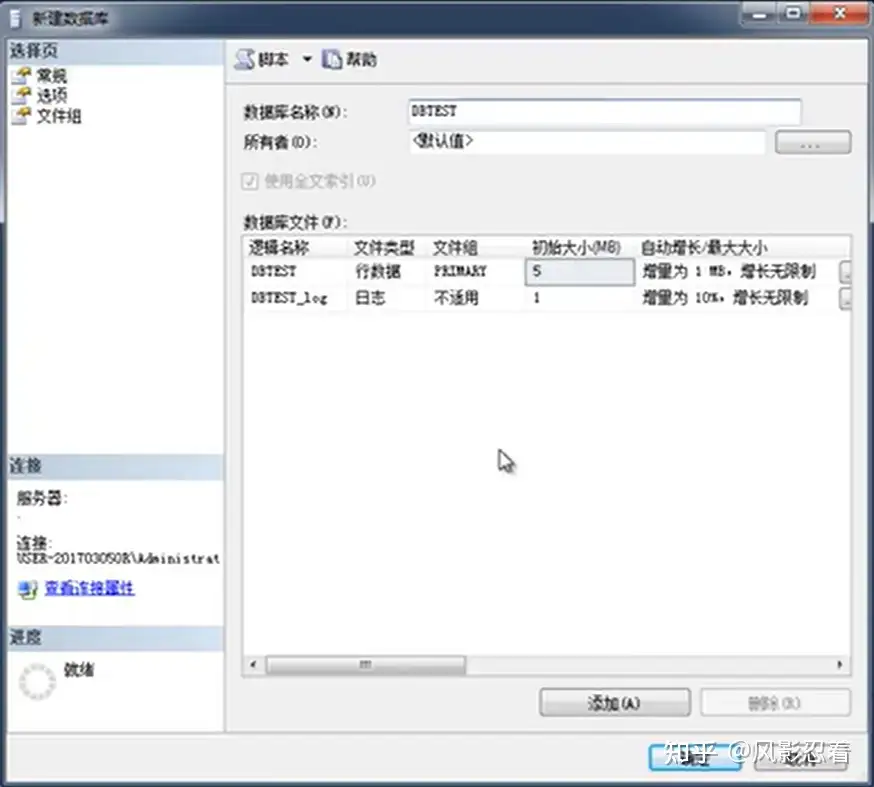
创建过程中会生成两个文件,如下图,第一个是数据库文件,第二个是数据库地日志文件。例如,第一个文件,一创建出来就是5M大小,哪怕没有数据;后面数据超过5M以后,文件大小每次增加1M。后面也有记录文件存在什么地方。
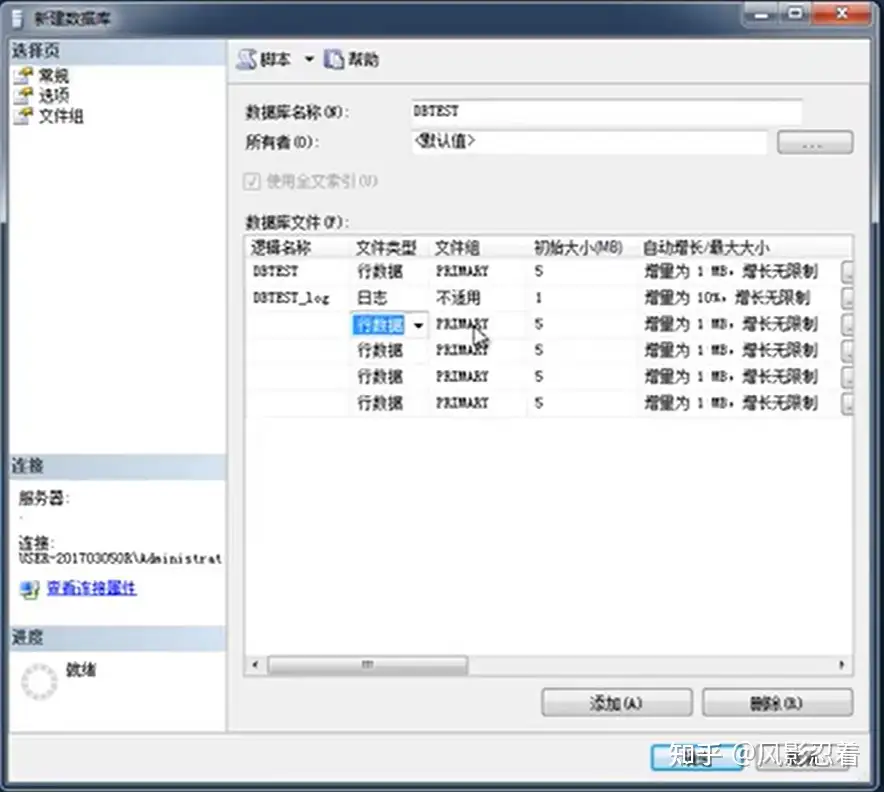
数据库创建默认有一个数据文件和一个日志文件。我们也可以添加成多个数据文件。通常情况下学习,只要一个数据文件。只有数据量比较大,需要份文件存储提高效率地时候,会用到多个数据文件。
二、建表
在数据库里面,在“表”这个文件夹上面,右键,新建表。
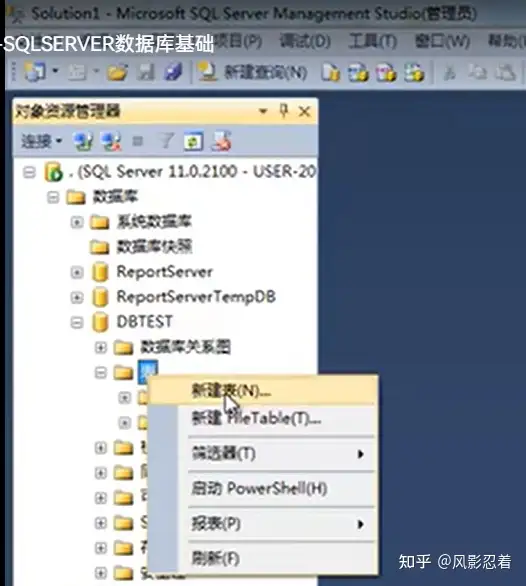
输入列名、数据类型、允许 null 值
主键:唯一标识一个记录,不允许重复。
CTRL+S保存
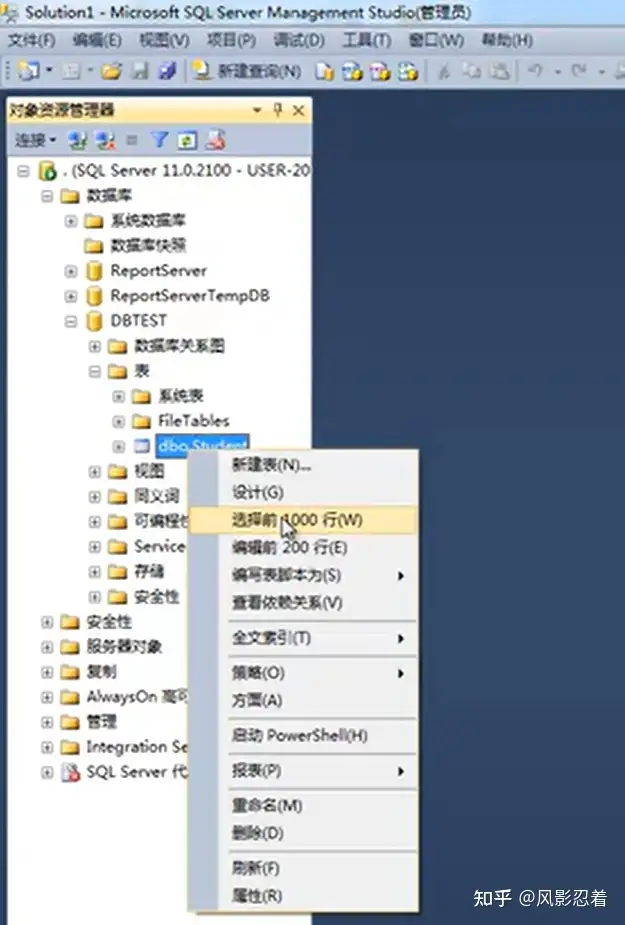
三、查询表
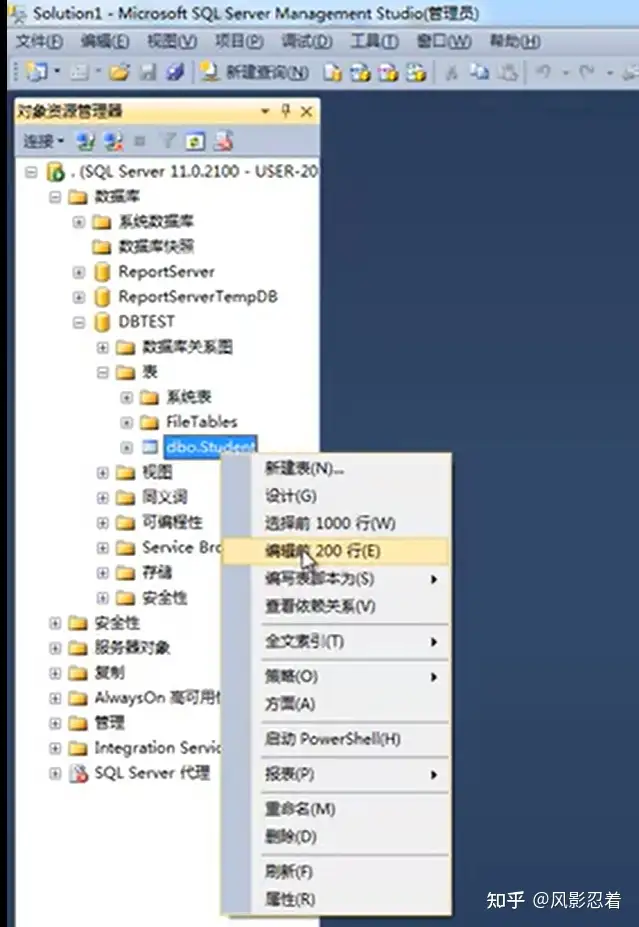
四、编辑表
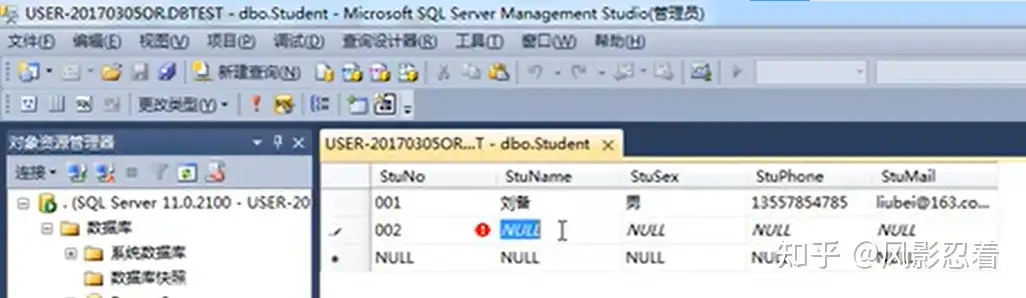
删除数据
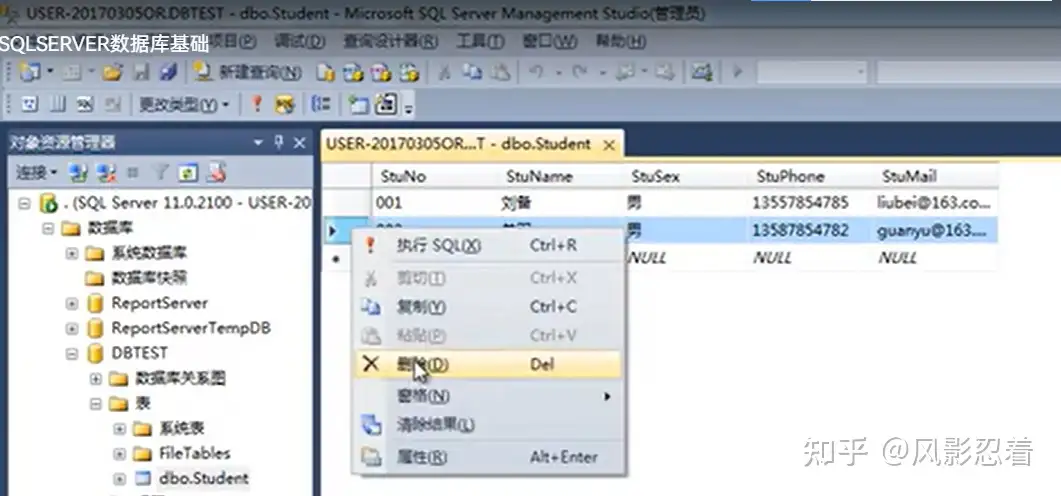
五、数据库迁移
(一)数据库的分离和附加
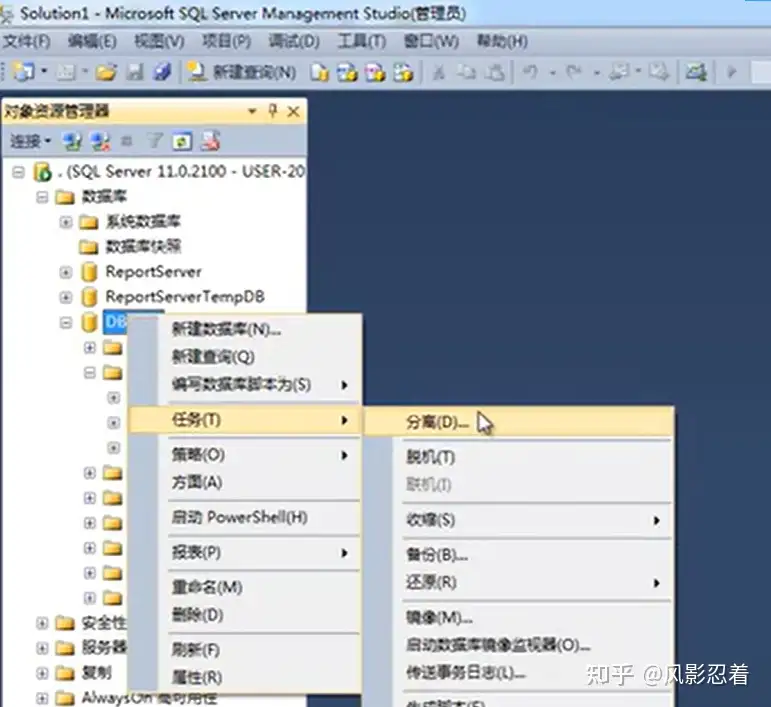
1.数据库的分离
首先分离数据库,这样操作以后,数据库文件就从数据库服务中脱离开来,文件就结束被占用,就可以成功复制数据库文件了。
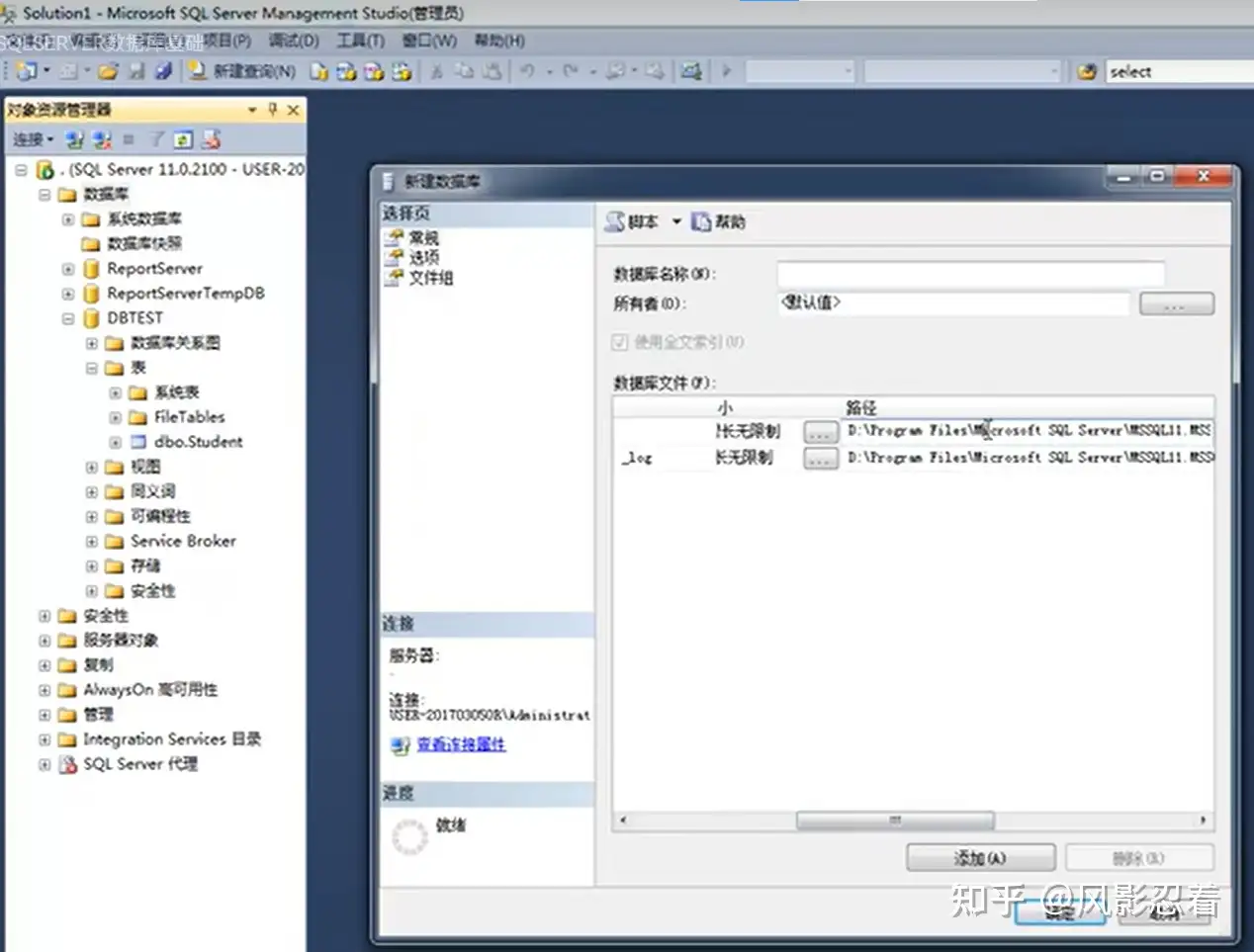
在新建数据库的时候,有指定数据库的保存位置。我们前往数据库的保存位置。
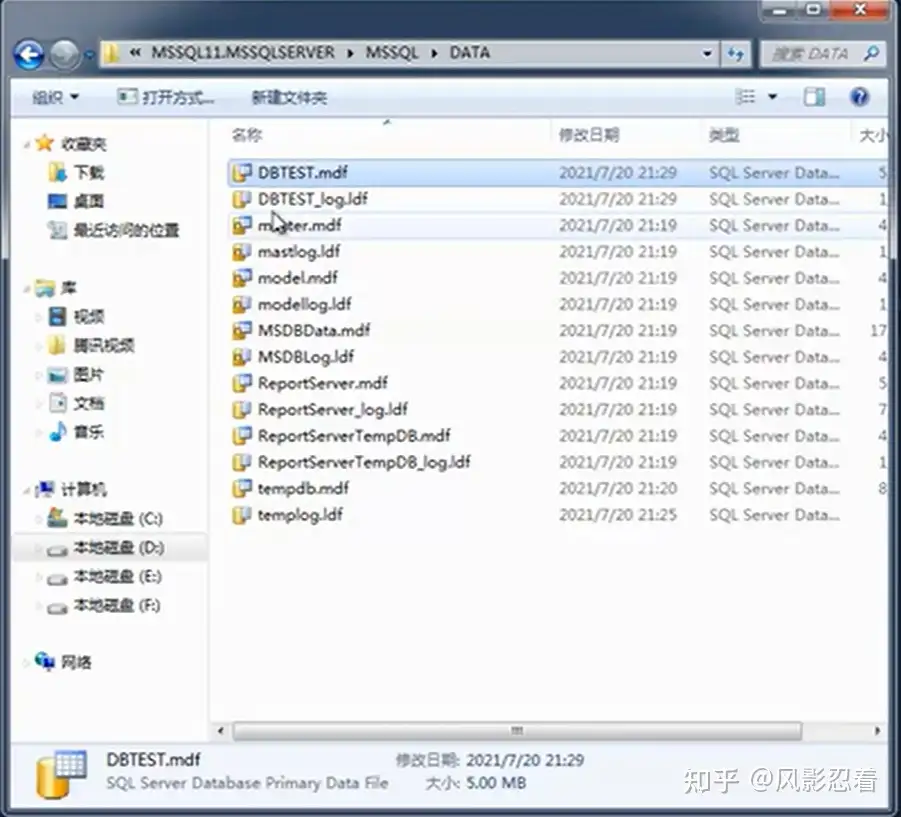
Mdf 是数据文件,ldf 是日志文件。
2.数据库的附加
在数据库上右键,点击“附加”
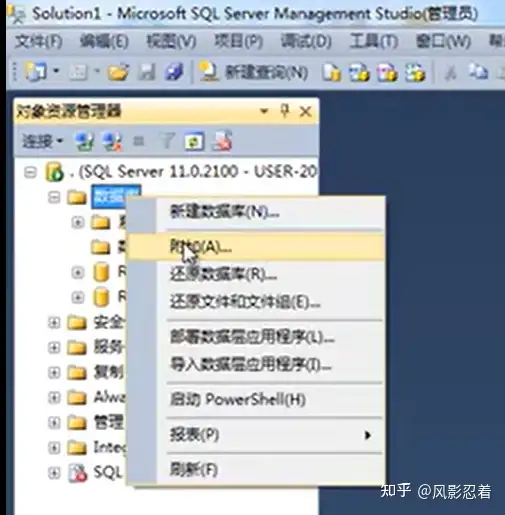
点击“添加”
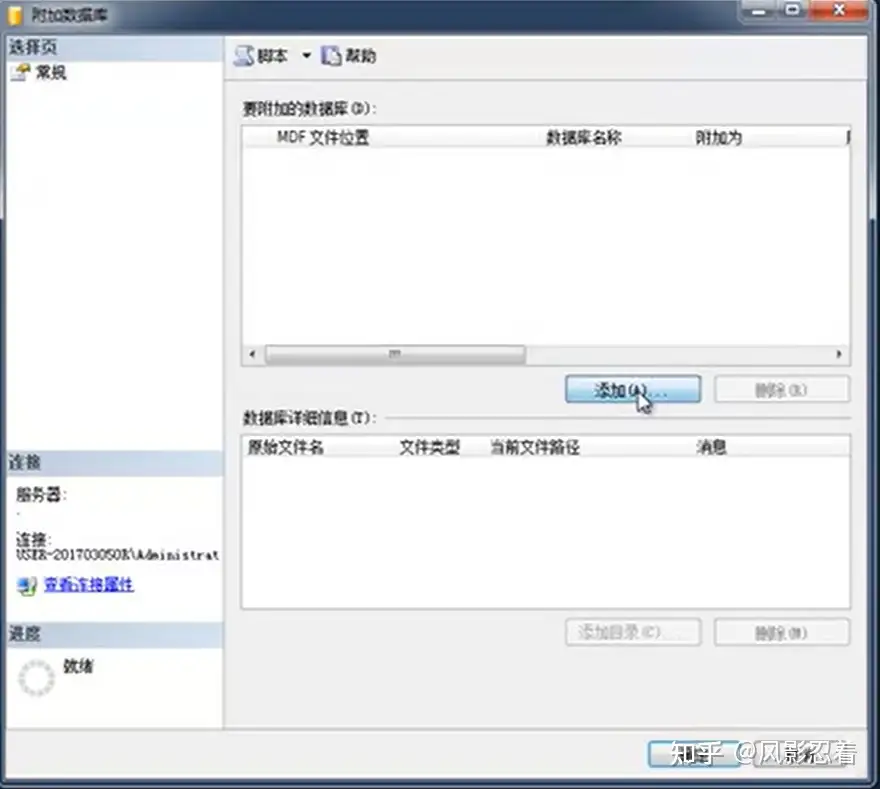
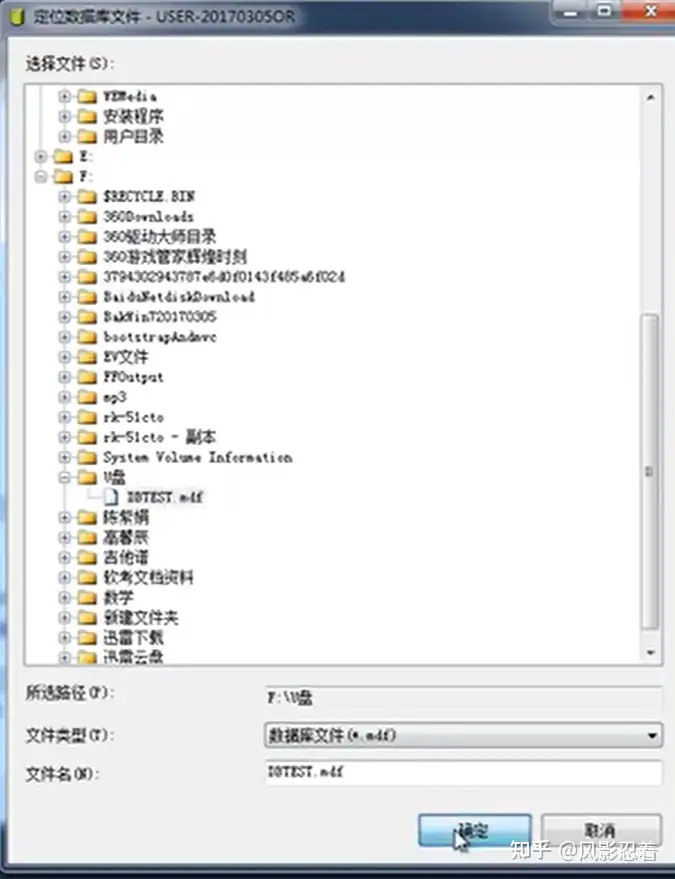
选中数据库文件,点击“确定”
分离和删除的区别在于,硬盘上是否还留存有数据库文件
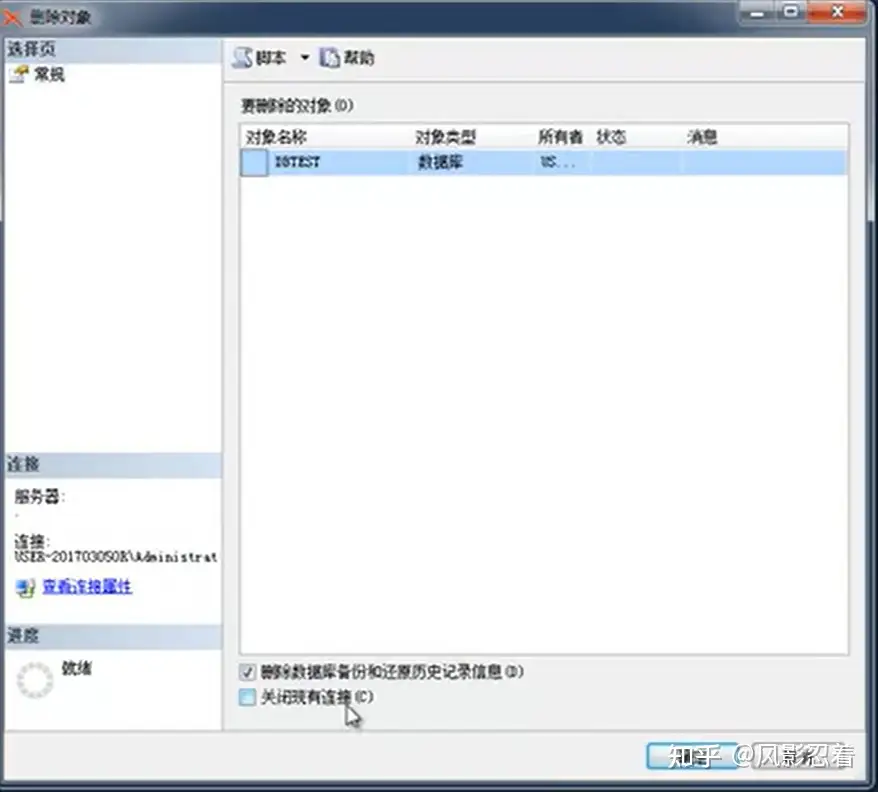
(二)数据库的备份和还原
前面分离、附加的操作的缺点在于,在分离以后,对应的整个数据库就不能用了。
可以保证在操作的时候,数据库仍然可以使用。
1.备份
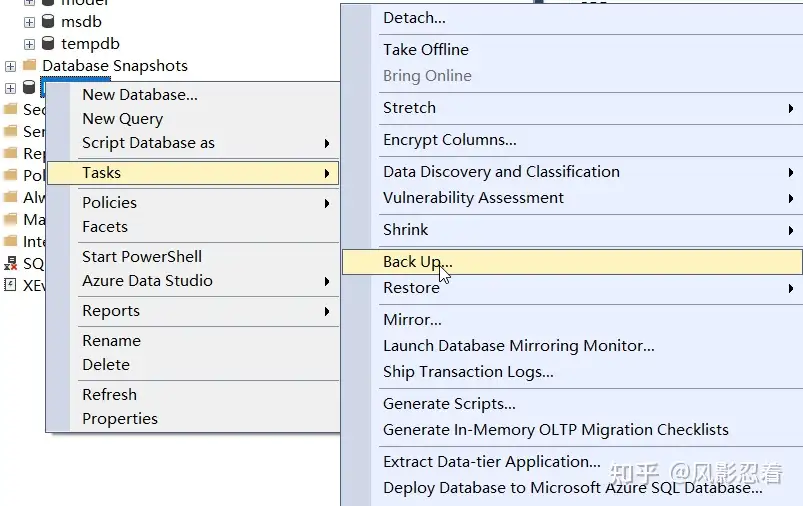
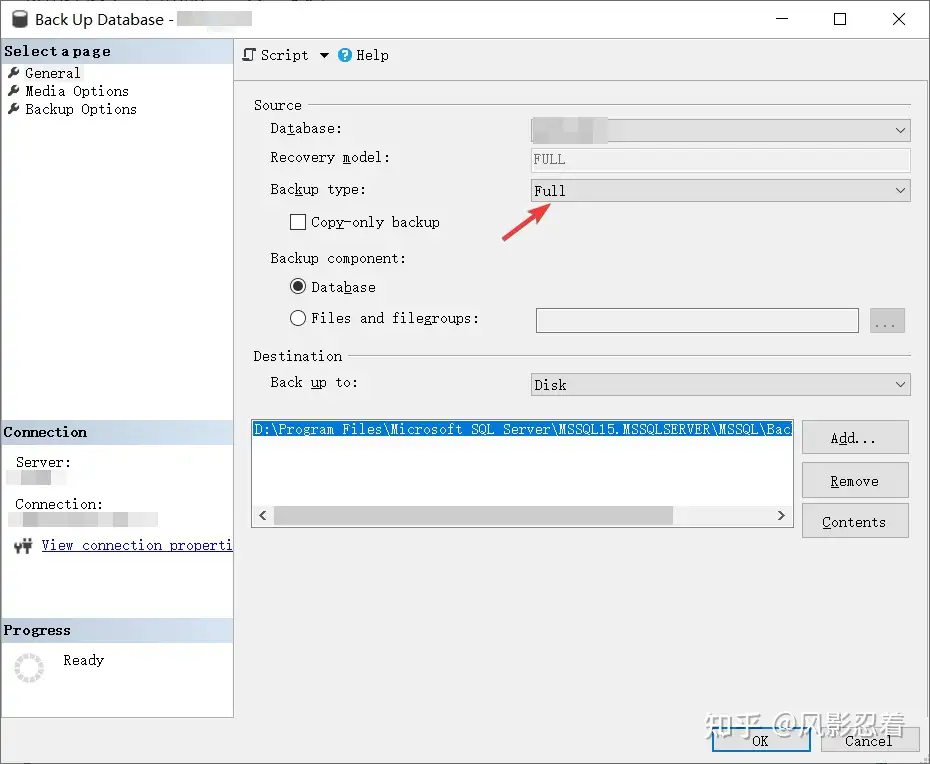
这里选择了最简单的“完整 Full”备份。
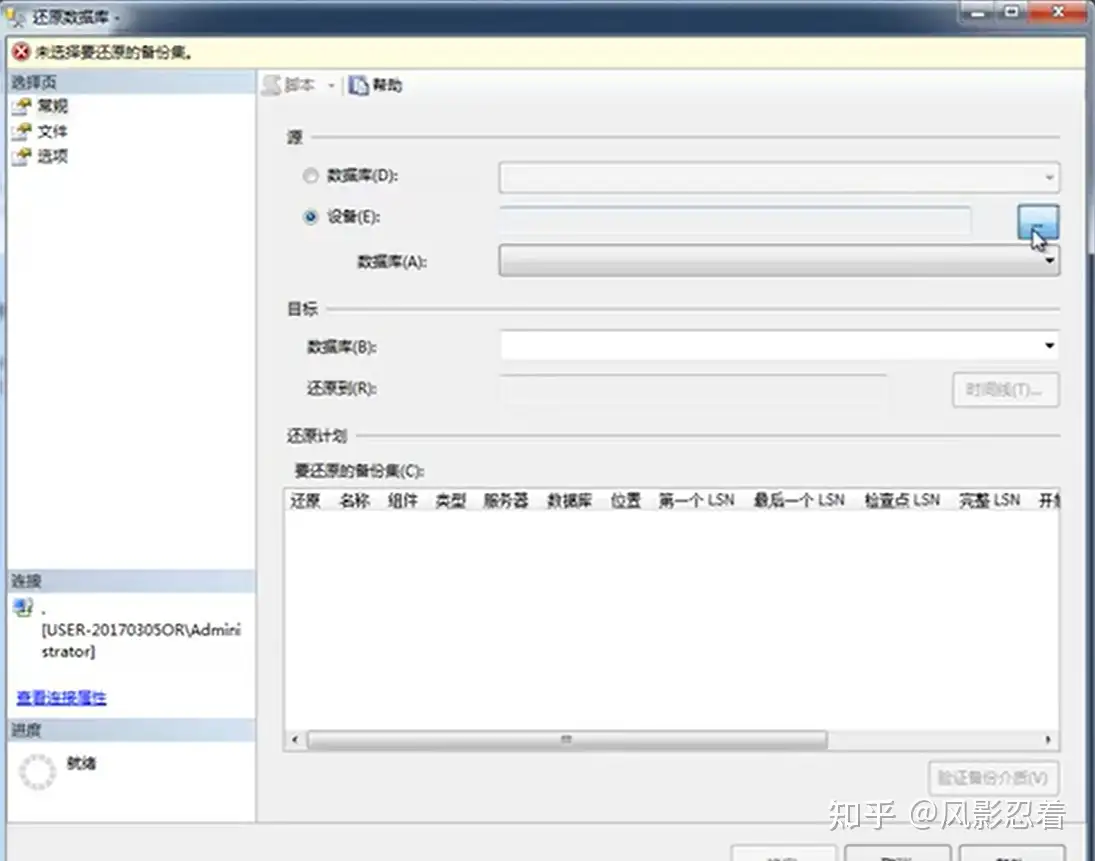
2.还原
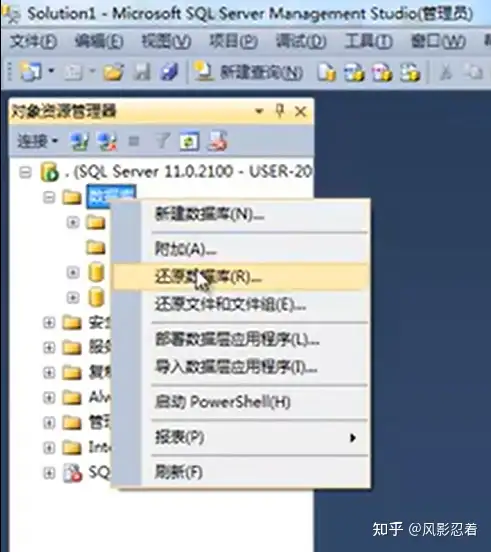
在“源”的位置选择“设备”,点击右边三个点,找到数据库备份文件的路径。
(三)数据库脚本保存
1.脚本保存
用脚本的方式把创建数据库过程导出来,再通过运行脚本的方式把数据恢复回来。
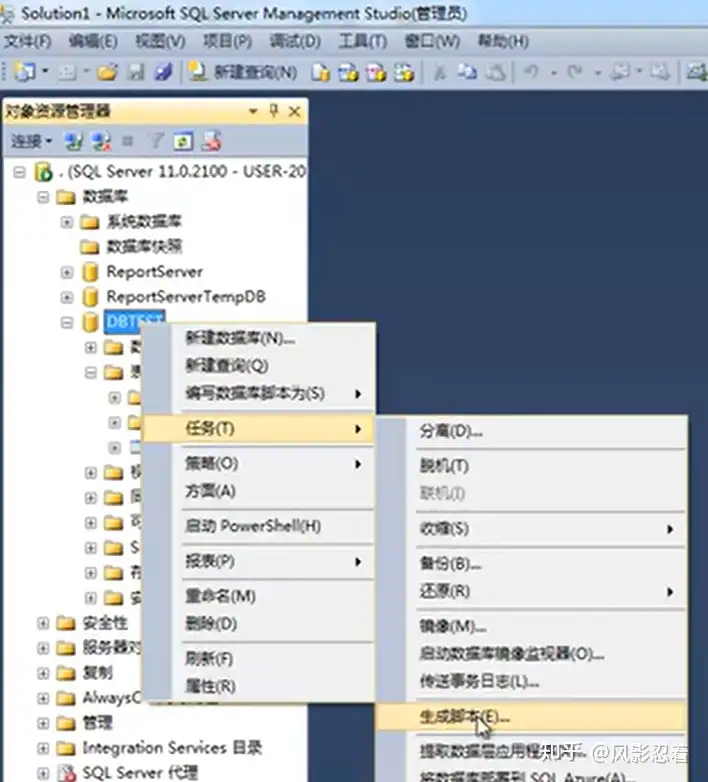
对于“简介”和“选择对象”,直接点下一步。
在“设置脚本编写选项”里面,选择高级,
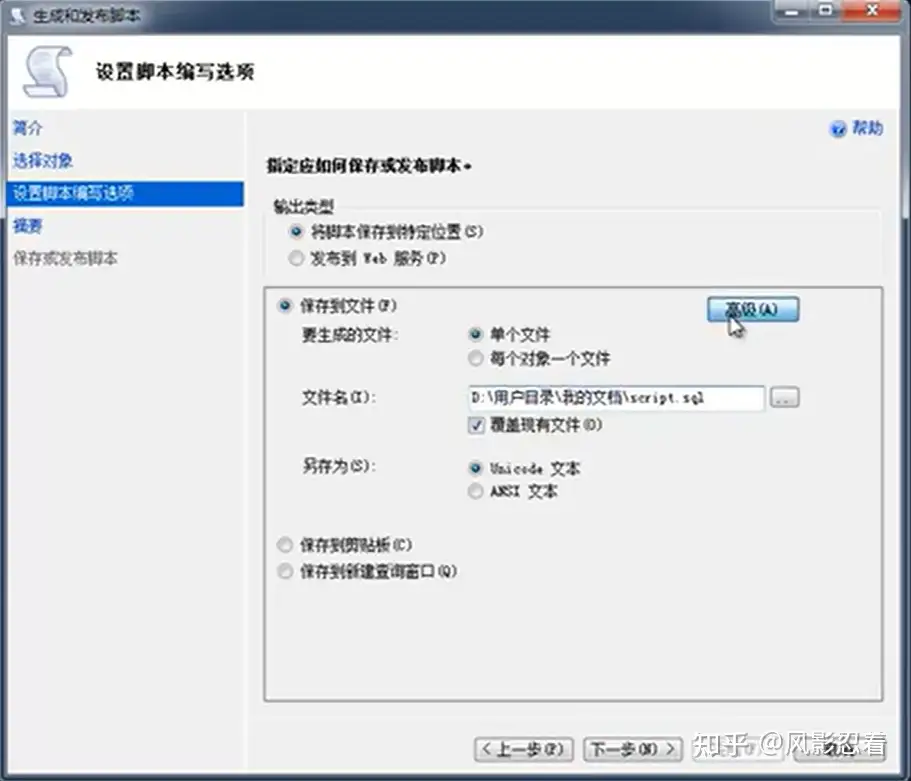
要编写脚本的数据类型,选择架构和数据。仅限架构就只有表的结构。
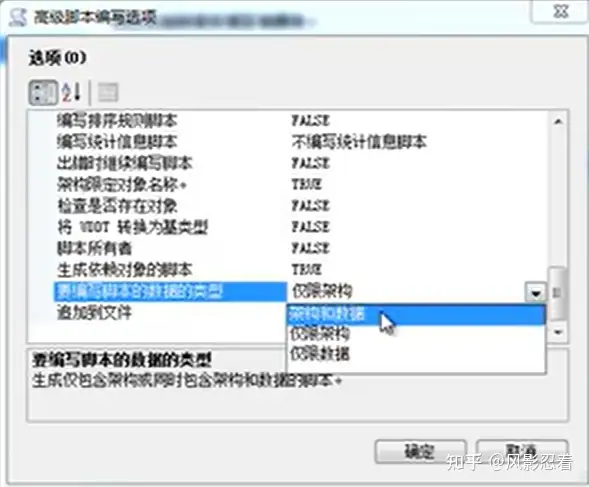
再点下一步、完成即可。
2.用脚本导入
用SSMS打开之前保存的脚本。
下拉框选到 master
再执行一下脚本即可。
数据库杂谈之:如何优雅的进行表结构设计
转自:https://zhuanlan.zhihu.com/p/20785905
数据库表结构设计作为后端软件开发不可或缺的一环,是每个后端工程师都会经历的过程。笔者也多次经历过这样的过程,也尝试过多种不同的设计方案,也从一些优秀的框架中学到不少,但并没有发现相关的文章对其进行总结。所以本文尝试把笔者看到的、学到的总结下来,希望对阅读本文的读者有所启发。
表结构设计主要有两个目的,一是让表结构更加的更具有表现力,做到数据库表的自描述,减少注释甚至不使用注释;二是满足系统效率和扩展性的需要,让系统性能更好,后期维护更简单。
本文主要探讨的是如何优雅的设计表结构,让人能够直观的从命名中窥探设计意图,传达设计者的设计目的,让团队成员达成共识,减少沟通成本。本文不讨论表结构设计对性能的影响,也不讨论数据库设计中的范式与反范式设计。本文将从数据库表的命名和字段的命名两个方面展开。
数据库表的命名
使用名词作为表名
仔细想想便可发现,数据库表中存在的所有数据都是现实世界各种操作的结果,它们有的是中间过程结果,有的是最终数据结果。不论怎样,它们是一份一份没有任何动作的,静态的记录。而表本身就是存储这些记录的容器,从这样的层面理解,表名应该采用名词的形式是完全符合逻辑的。
比如我们要设计一个存储用户邀请的表,invitation 就比 invite 更加的优雅。
相关表采用统一前缀
我们知道,大型系统的设计往往按模块或者子系统进行划分,一个一个模块的处理问题,保证模块间的低耦合,模块内的高内聚。数据库表设计也一样,我们可以对相关联的表采用相同的前缀,使开发人员一眼看上去就知道哪几个表是相关的。
比如对于用户基本信息表、用户的详细信息表和用户的微信绑定表如下的命名更可取:
user
user_profile
user_wechat
字段的命名
本节先介绍几个比较通用的原则,使得字段的含义更容易理解,描述性更强,之后进行简单的总结分类,以便让我们明白这些原则背后的逻辑。
使用动词被动形式+描述性后缀
通过前面我们知道,数据库表中的所有记录都是静态的结果性数据,它是由一定的用户操作产生的。那么它是如何产生的?经过什么样的操作产生的呢?
在解答之前先看一个例子,下面是一个简单的 article 表结构:
id: integer
title: varchar
content: text
user_id: integer
create_time: timestamp
这样的设计本身是没有问题的,目前用的也很多。这个设计主要的问题是没有体现出 user_id 与这篇文章的关系,需要经过一定的猜测和思考才能得出。create_time 虽然还比较直观,但没有体现出这篇文章实在过去的某个时间创建的。
然后我们在来看修改后的设计:
id: integer
title: varchar
content: text
created_by: integer
created_at: timestamp
通过把 user_id 替换为 created_by、create_time 替换为 created_at,使得我们更容易理解对应的文章是被指定的人在指定的时间创建出来的,而不需要我们的多方猜测或者查阅文档,使得整个表结构的描述性更强。
时间区分当前时间和未来时间
英语中表时间的时候, at 一般跟一个时间点,而 in 有表示在未来的某个时间之内的意思。结合起来,笔者倾向于用 at 表示过去或者现在的时间,而用 in 表示未来的时间。比如日历中的 event 有开始时间和结束时间的概念,我觉得如下的命名是比较合理的:
starts_at 事件的开始时间,相对 ends_in 它属于当前时间,采用 _at 后缀
ends_in 事件的结束时间,相对 ends_in 它属于未来时间,从用 _in 后缀
其他我们比较常用的比如 created_at、updated_at、expires_in 都属于这种类型。
使用第三人称单数
当我们采用动词+介词的时候我更倾向与使用第三人称单数,因为字段描述的这个实体是单数的,通过使用第三人称单数,我们可以自然语言的方式表达出需要的意思。比如以 event 为例,翻译成英语是这样的:
The event starts at 2016-05-05 12:00:00
完全符合英语的语法,也表达了我们想要表达的意思。
区分单数与复数
单数与复数主要是对字段内容的描述,比如通知(notification)有接收人这个字段,如果我们需要通知能够发送给多个人,那么 receivers 这样的字段名称明显好于 receiver,因为 receivers 体现了通知可以发送给多个人这一个事实。
前面从四个原则出发介绍了如何让字段更具有描述性,简单总结下来我觉得从语义上来说,字段可以分为两种类型:描述性字段和动作性字段。
描述性字段是对对应数据库记录(或者说实体)的补充说明,比如以人作为实体,那么人的身高、体重和血压就属于这类描述性字段。
描述性字段如果是动词+介词的形式,动词需要采用第三人称单数的形式,比如 starts_at。然后根据字段的内容,如果内容有多个元素或实体,我们需要使用复数,否则使用单数形式。
动作性字段不仅能对所属实体进行补充说明,还能对这个实体的所涉及操作有所描述。比如我们有 article 这个实体, article 的 created_by 和 created_at 就属于动作性字段,因为它不仅表达了 article 的创建者和创建时间这层信息,它还表达了这个 article 是指定的人被创建的,而不是凭空生成的。