-
1 sqlserver导入CSV...
-
2 SQL函数浅总结,使...
-
3 机器学习,KMeans...
-
4 聚类分析的基本概...
-
5 SQL函数浅总结,使...
-
6 SQL 常用函数...
-
7 数据预处理建议
-
8 基于基站定位数据...
-
9 SQL语言参考
sqlserver导入CSV文件数据
URL:https://blog.51cto.com/u_16213448/7097054
选中数据库右键->任务,右键->导入数据,打开导入页面
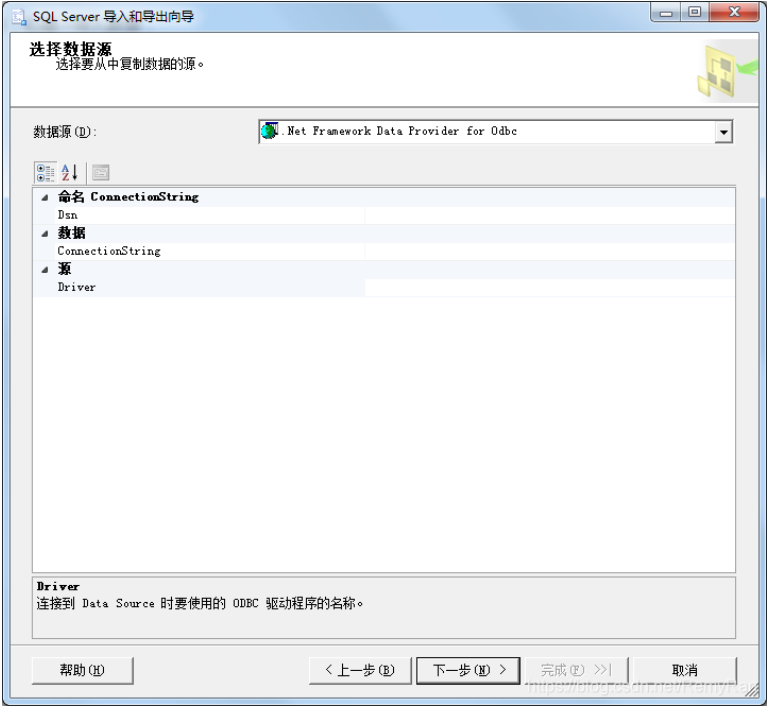
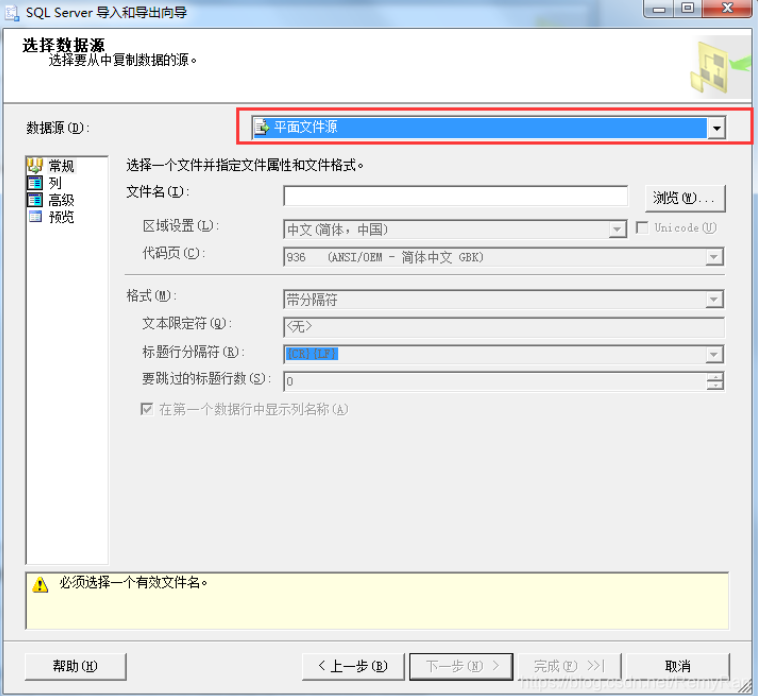
数据源选择平面文件源
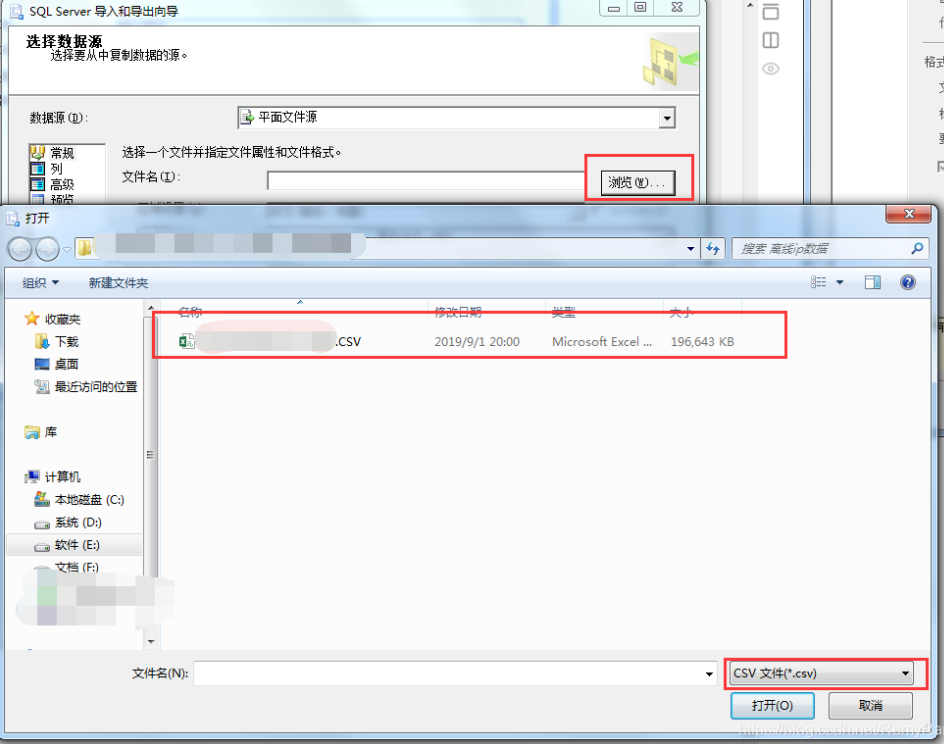
点击浏览按钮选择要导入的文件
旁边的列,高级,预览根据自己情况选择设置,下一步;
目标选择Microsoft OLE DB Provider for SQL Server,服务器我这边选择自己电脑,身份验证使用SQL Sqlserver身份验证,填写正确的用户名和密码,选择要导入到的数据库,下一步;
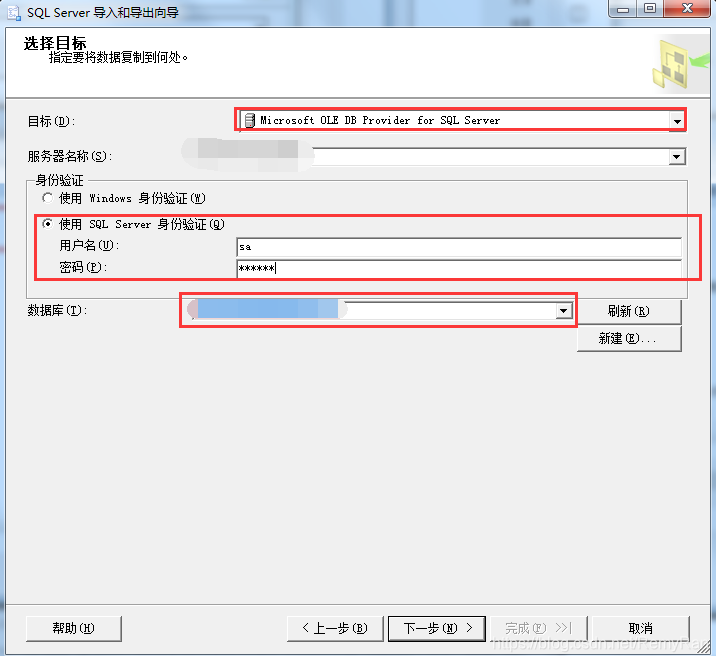
选择目标表,也可以不选择目标表,直接根据导入文件的名称创建一个新表,点击编辑映射按钮可以自行编辑创建表的SQL
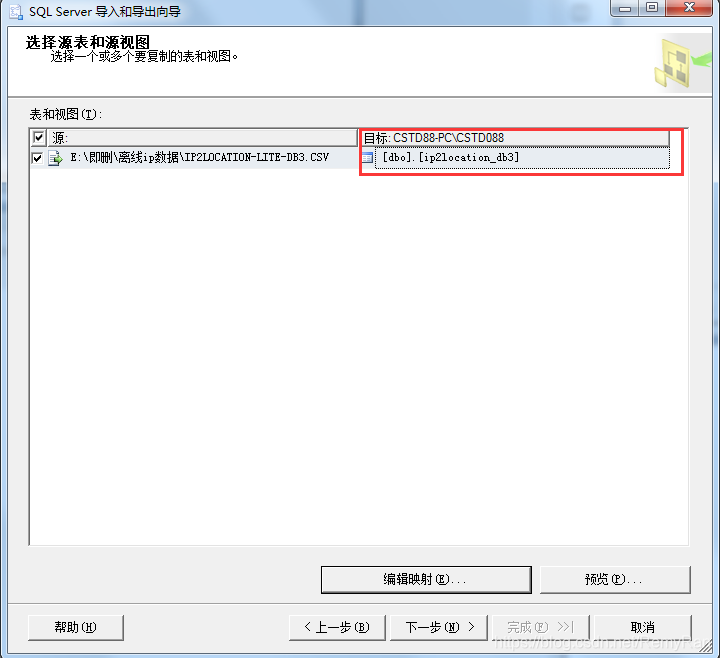
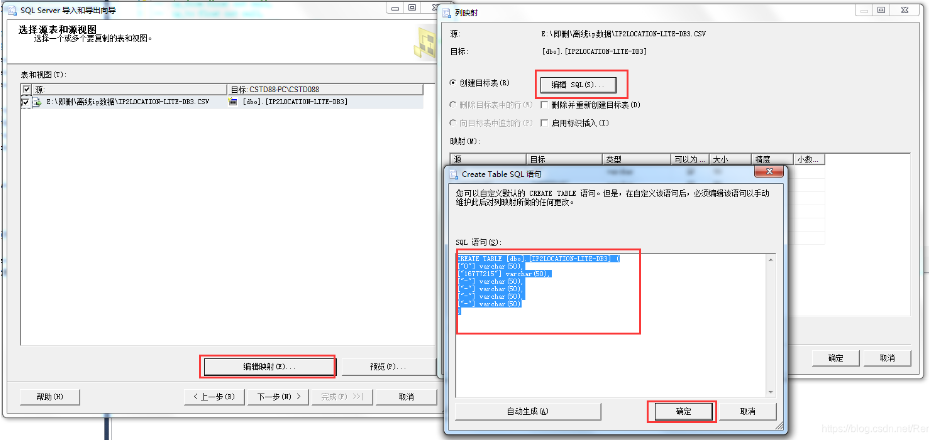
之后一直下一步,完成,就行了。
但是这样的话也不是说就一定就导入正确,你得保证你文件里的数据跟数据库定义的表数据类型一致,文件中第一行要注明列名(所以第一行每一列是不能重复的),可能还有一些其他问题。
SQL函数浅总结,使用方法及实例讲解大全
URL:https://zhuanlan.zhihu.com/p/498554620
SQL 函数
SQL 拥有很多可用于计数和计算的内建函数。
函数的语法
内建 SQL 函数的语法是:
SELECT function (列) FROM 表
函数的类型
在 SQL 中,基本的函数类型和种类有若干种。函数的基本类型是:
Aggregate 函数
Scalar 函数
合计函数(Aggregate functions)
Aggregate 函数的操作面向一系列的值,并返回一个单一的值。
注释:如果在 SELECT 语句的项目列表中的众多其它表达式中使用 SELECT 语句,则这个 SELECT 必须使用 GROUP BY 语句!
"Persons" table (在大部分的例子中使用过)
| Name | Age |
| Adams, John | 38 |
| Bush, George | 33 |
| Carter, Thomas | 28 |
MS Access 中的合计函数
| 函数 | 描述 |
| AVG(column) | 返回某列的平均值 |
| COUNT(column) | 返回某列的行数(不包括 NULL 值) |
| COUNT(*) | 返回被选行数 |
| FIRST(column) | 返回在指定的域中第一个记录的值 |
| LAST(column) | 返回在指定的域中最后一个记录的值 |
| MAX(column) | 返回某列的最高值 |
| MIN(column) | 返回某列的最低值 |
| STDEV(column) | |
| STDEVP(column) | |
| SUM(column) | 返回某列的总和 |
| VAR(column) | |
| VARP(column) |
在 SQL Server 中的合计函数
| 函数 | 描述 |
| AVG(column) | 返回某列的平均值 |
| BINARY_CHECKSUM | |
| CHECKSUM | |
| CHECKSUM_AGG | |
| COUNT(column) | 返回某列的行数(不包括NULL值) |
| COUNT(*) | 返回被选行数 |
| COUNT(DISTINCT column) | 返回相异结果的数目 |
| FIRST(column) | 返回在指定的域中第一个记录的值(SQLServer2000 不支持) |
| LAST(column) | 返回在指定的域中最后一个记录的值(SQLServer2000 不支持) |
| MAX(column) | 返回某列的最高值 |
| MIN(column) | 返回某列的最低值 |
| STDEV(column) | |
| STDEVP(column) | |
| SUM(column) | 返回某列的总和 |
| VAR(column) | |
| VARP(column) |
Scalar 函数
Scalar 函数的操作面向某个单一的值,并返回基于输入值的一个单一的值。
MS Access 中的 Scalar 函数
| 函数 | 描述 |
| UCASE(c) | 将某个域转换为大写 |
| LCASE(c) | 将某个域转换为小写 |
| MID(c,start[,end]) | 从某个文本域提取字符 |
| LEN(c) | 返回某个文本域的长度 |
| INSTR(c,char) | 返回在某个文本域中指定字符的数值位置 |
| LEFT(c,number_of_char) | 返回某个被请求的文本域的左侧部分 |
| RIGHT(c,number_of_char) | 返回某个被请求的文本域的右侧部分 |
| ROUND(c,decimals) | 对某个数值域进行指定小数位数的四舍五入 |
| MOD(x,y) | 返回除法操作的余数 |
| NOW() | 返回当前的系统日期 |
| FORMAT(c,format) | 改变某个域的显示方式 |
| DATEDIFF(d,date1,date2) | 用于执行日期计算 |
SQL AVG 函数
定义和用法
AVG 函数返回数值列的平均值。NULL 值不包括在计算中。
SQL AVG() 语法
SELECT AVG (column_name) FROM table_name
SQL AVG() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
例子 1
现在,我们希望计算 "OrderPrice" 字段的平均值。
我们使用如下 SQL 语句:
SELECT AVG (OrderPrice) AS Order Average FROM Orders
结果集类似这样:
| OrderAverage |
| 950 |
例子 2
现在,我们希望找到 OrderPrice 值高于 OrderPrice 平均值的客户。
我们使用如下 SQL 语句:
SELECT Customer FROM Orders
WHERE OrderPrice>(SELECT AVG (OrderPrice) FROM Orders)
结果集类似这样:
| Customer |
| Bush |
| Carter |
| Adams |
SQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SQL COUNT() 语法
SQL COUNT(column_name) 语法
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT (column_name) FROM table_name
SQL COUNT(*) 语法
COUNT(*) 函数返回表中的记录数:
SELECT COUNT (*) FROM table_name
SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT (DISTINCTcolumn_name) FROMt able_name
注释:COUNT(DISTINCT) 适用于 ORACLE 和 Microsoft SQL Server,但是无法用于 Microsoft Access。
SQL COUNT(column_name) 实例
我们拥有下列 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望计算客户 "Carter" 的订单数。
我们使用如下 SQL 语句:
SELECT COUNT (Customer) AS CustomerNilsen FROM Orders
WHERE Customer='Carter'
以上 SQL 语句的结果是 2,因为客户 Carter 共有 2 个订单:
| CustomerNilsen |
| 2 |
SQL COUNT(*) 实例
如果我们省略 WHERE 子句,比如这样:
SELECT COUNT(*) ASNumberOfOrders FROMOrders
结果集类似这样:
| NumberOfOrders |
| 6 |
这是表中的总行数。
SQL COUNT(DISTINCT column_name) 实例
现在,我们希望计算 "Orders" 表中不同客户的数目。
我们使用如下 SQL 语句:
SELECT COUNT(DISTINCTCustomer) ASNumberOfCustomers FROMOrders
结果集类似这样:
| NumberOfCustomers |
| 3 |
这是 "Orders" 表中不同客户(Bush, Carter 和 Adams)的数目。>
SQL FIRST() 函数
FIRST() 函数
FIRST() 函数返回指定的字段中第一个记录的值。
提示:可使用 ORDER BY 语句对记录进行排序。
SQL FIRST() 语法
SELECT FIRST (column_name) FROMt able_name
SQL FIRST() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的第一个值。
我们使用如下 SQL 语句:
SELECT FIRST (OrderPrice) AS FirstOrderPrice FROM Orders
结果集类似这样:
| FirstOrderPrice |
| 1000 |
SQL LAST() 函数
LAST() 函数
LAST() 函数返回指定的字段中最后一个记录的值。
提示:可使用 ORDER BY 语句对记录进行排序。
SQL LAST() 语法
SELECT LAST (column_name) FROM table_name
SQL LAST() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最后一个值。
我们使用如下 SQL 语句:
SELECT LAST (OrderPrice) AS LastOrderPrice FROM Orders
结果集类似这样:
| LastOrderPrice |
| 100 |
SQL MAX() 函数
MAX() 函数
MAX 函数返回一列中的最大值。NULL 值不包括在计算中。
SQL MAX() 语法
SELECT MAX (column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
SQL MAX() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最大值。
我们使用如下 SQL 语句:
SELECT MAX (OrderPrice) AS LargestOrderPrice FROM Orders
结果集类似这样:
| LargestOrderPrice |
| 2000 |
SQL MIN() 函数
MIN() 函数
MIN 函数返回一列中的最小值。NULL 值不包括在计算中。
SQL MIN() 语法
SELECT MIN (column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
SQL MIN() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最小值。
我们使用如下 SQL 语句:
SELECT MIN (OrderPrice) ASS mallestOrderPrice FROM Orders
结果集类似这样:
| SmallestOrderPrice |
| 1 |
SQL SUM() 函数
SUM() 函数
SUM 函数返回数值列的总数(总额)。
SQL SUM() 语法
SELECTSUM(column_name) FROMtable_name
SQL SUM() 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 字段的总数。
我们使用如下 SQL 语句:
SELECTSUM(OrderPrice) ASOrderTotal FROMOrders
结果集类似这样:
| OrderTotal |
| 5700 |
SQL GROUP BY 语句
合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。
GROUP BY 语句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BYcolumn_name
SQL GROUP BY 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找每个客户的总金额(总订单)。
我们想要使用 GROUP BY 语句对客户进行组合。
我们使用下列 SQL 语句:
SELECT Customer,SUM (OrderPrice) FROM Orders
GROUP BY Customer
结果集类似这样:
| Customer | SUM(OrderPrice) |
| Bush | 2000 |
| Carter | 1700 |
| Adams | 2000 |
很棒吧,对不对?
让我们看一下如果省略 GROUP BY 会出现什么情况:
SELECT Customer,SUM (OrderPrice) FROM Orders
结果集类似这样:
| Customer | SUM(OrderPrice) |
| Bush | 5700 |
| Carter | 5700 |
| Bush | 5700 |
| Bush | 5700 |
| Adams | 5700 |
| Carter | 5700 |
上面的结果集不是我们需要的。
那么为什么不能使用上面这条 SELECT 语句呢?解释如下:上面的 SELECT 语句指定了两列(Customer 和 SUM(OrderPrice))。"SUM(OrderPrice)" 返回一个单独的值("OrderPrice" 列的总计),而 "Customer" 返回 6 个值(每个值对应 "Orders" 表中的每一行)。因此,我们得不到正确的结果。不过,您已经看到了,GROUP BY 语句解决了这个问题。
GROUP BY 一个以上的列
我们也可以对一个以上的列应用 GROUP BY 语句,就像这样:
SELECT Customer,OrderDate,SUM (OrderPrice) FROM Orders
GROUP BY Customer,OrderDate
SQL HAVING 语句
HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
SQL HAVING 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BYcolumn_name
HAVIN Gaggregate_function(column_name) operator value
SQL HAVING 实例
我们拥有下面这个 "Orders" 表:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找订单总金额少于 2000 的客户。
我们使用如下 SQL 语句:
SELECT Customer,SUM (OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000
结果集类似:
| Customer | SUM(OrderPrice) |
| Carter | 1700 |
现在我们希望查找客户 "Bush" 或 "Adams" 拥有超过 1500 的订单总金额。
我们在 SQL 语句中增加了一个普通的 WHERE 子句:
SELECT Customer,SUM (OrderPrice) FROM Orders
WHERE Customer='Bush'OR Customer='Adams'GROUP BY Customer
HAVING SUM (OrderPrice)>1500
结果集:
| Customer | SUM(OrderPrice) |
| Bush | 2000 |
| Adams | 2000 |
SQL UCASE() 函数
UCASE() 函数
UCASE 函数把字段的值转换为大写。
SQL UCASE() 语法
SELECT UCASE(column_name) FROM table_name
SQL UCASE() 实例
我们拥有下面这个 "Persons" 表:
| Id | LastName | FirstName | Address | City |
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为大写。
我们使用如下 SQL 语句:
SELECT UCASE (LastName) as LastName,FirstName FROM Persons
结果集类似这样:
| LastName | FirstName |
| ADAMS | John |
| BUSH | George |
| CARTER | Thomas |
SQL LCASE() 函数
LCASE() 函数
LCASE 函数把字段的值转换为小写。
SQL LCASE() 语法
SELECT LCASE (column_name) FROM table_name
SQL LCASE() 实例
我们拥有下面这个 "Persons" 表:
| Id | LastName | FirstName | Address | City |
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为小写。
我们使用如下 SQL 语句:
SELECTLCASE(LastName) as LastName,FirstName FROMPersons
结果集类似这样:
| LastName | FirstName |
| adams | John |
| bush | George |
| carter | Thomas |
SQL MID() 函数
MID() 函数
MID 函数用于从文本字段中提取字符。
SQL MID() 语法
SELECT MID (column_name,start[,length]) FROMt able_name
| 参数 | 描述 |
| column_name | 必需。要提取字符的字段。 |
| start | 必需。规定开始位置(起始值是 1)。 |
| length | 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。 |
SQL MID() 实例
我们拥有下面这个 "Persons" 表:
| Id | LastName | FirstName | Address | City |
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望从 "City" 列中提取前 3 个字符。
我们使用如下 SQL 语句:
SELECT MID (City,1,3) asSmallCity FROM Persons
结果集类似这样:
| SmallCity |
| Lon |
| New |
| Bei |
SQL LEN() 函数
LEN() 函数
LEN 函数返回文本字段中值的长度。
SQL LEN() 语法
SELECTLEN(column_name) FROMtable_name
SQL LEN() 实例
我们拥有下面这个 "Persons" 表:
| Id | LastName | FirstName | Address | City |
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望取得 "City" 列中值的长度。
我们使用如下 SQL 语句:
SELECTLEN(City) asLengthOfCity FROMPersons
结果集类似这样:
| LengthOfCity |
| 6 |
| 8 |
| 7 |
SQL ROUND() 函数
ROUND() 函数
ROUND 函数用于把数值字段舍入为指定的小数位数。
SQL ROUND() 语法
SELECT ROUND (column_name,decimals) FROM table_name
| 参数 | 描述 |
| column_name | 必需。要舍入的字段。 |
| decimals | 必需。规定要返回的小数位数。 |
SQL ROUND() 实例
我们拥有下面这个 "Products" 表:
| Prod_Id | ProductName | Unit | UnitPrice |
| 1 | gold | 1000 g | 32.35 |
| 2 | silver | 1000 g | 11.56 |
| 3 | copper | 1000 g | 6.85 |
现在,我们希望把名称和价格舍入为最接近的整数。
我们使用如下 SQL 语句:
SELECT ProductName, ROUND (UnitPrice,0) as UnitPrice FROM Products
结果集类似这样:
| ProductName | UnitPrice |
| gold | 32 |
| silver | 12 |
| copper | 7 |
SQL NOW() 函数
NOW() 函数
NOW 函数返回当前的日期和时间。
提示:如果您在使用 Sql Server 数据库,请使用 getdate() 函数来获得当前的日期时间。
SQL NOW() 语法
SELECT NOW() FROM table_name
SQL NOW() 实例
我们拥有下面这个 "Products" 表:
| Prod_Id | ProductName | Unit | UnitPrice |
| 1 | gold | 1000 g | 32.35 |
| 2 | silver | 1000 g | 11.56 |
| 3 | copper | 1000 g | 6.85 |
现在,我们希望显示当天的日期所对应的名称和价格。
我们使用如下 SQL 语句:
SELECT ProductName, UnitPrice, Now () asPerDate FROM Products
结果集类似这样:
| ProductName | UnitPrice | PerDate |
| gold | 32.35 | 12/29/2008 11:36:05 AM |
| silver | 11.56 | 12/29/2008 11:36:05 AM |
| copper | 6.85 | 12/29/2008 11:36:05 AM |
SQL FORMAT() 函数
FORMAT() 函数
FORMAT 函数用于对字段的显示进行格式化。
SQL FORMAT() 语法
SELECT FORM AT (column_name,format) FROM table_name
参数 | 描述 |
column_name | 必需。要格式化的字段。 |
format | 必需。规定格式。 |
SQL FORMAT() 实例
我们拥有下面这个 "Products" 表:
| Prod_Id | ProductName | Unit | UnitPrice |
| 1 | gold | 1000 g | 32.35 |
| 2 | silver | 1000 g | 11.56 |
| 3 | copper | 1000 g | 6.85 |
现在,我们希望显示每天日期所对应的名称和价格(日期的显示格式是 "YYYY-MM-DD")。
我们使用如下 SQL 语句:
SELECT ProductName, UnitPrice, FORM AT(Now(),'YYYY-MM-DD') asPerDate
FROM Products
结果集类似这样:
| ProductName | UnitPrice | PerDate |
| gold | 32.35 | 12/29/2008 |
| silver | 11.56 | 12/29/2008 |
| copper | 6.85 | 12/29/2008 |
机器学习,KMeans聚类分析详解
URL:https://baijiahao.baidu.com/s?id=1705888895322977701&wfr=spider&for=pc
大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分。聚类的基本思想是"物以类聚、人以群分",将大量数据集中相似的数据样本区分出来,并发现不同类的特征。
聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。尽管全球每日新增数据量以PB或EB级别增长,但是大部分数据属于无标注甚至非结构化。所以相对于监督学习,不需要标注的无监督学习蕴含了巨大的潜力与价值。聚类根据数据自身的距离或相似度将他们划分为若干组,划分原则是组内样本最小化而组间距离最大化。
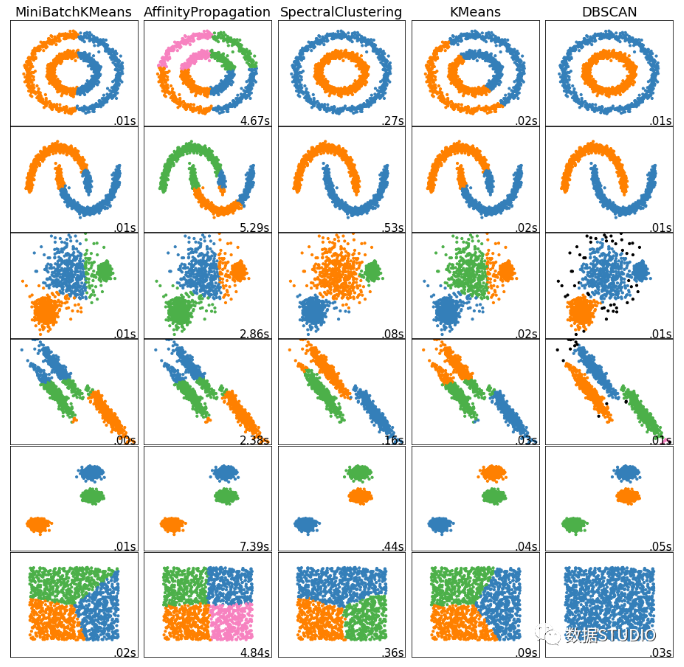
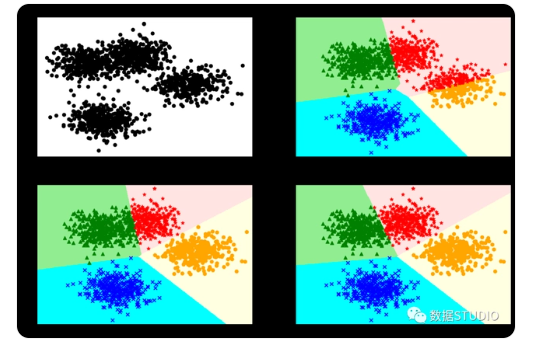
常见聚类算法聚类效果对比图
聚类分析常用于数据探索或挖掘前期
没有先验经验做探索性分析
样本量较大时做预处理
常用于解决
数据集可以分几类;每个类别有多少样本量
不同类别中各个变量的强弱关系如何
不同类型的典型特征是什么
一般应用场景
群类别间的差异性特征分析
群类别内的关键特征提取
图像压缩、分割、图像理解
异常检测
数据离散化
当然聚类分析也有其缺点
无法提供明确的行动指向
数据异常对结果有影响
本文将从算法原理、优化目标、sklearn聚类算法、算法优缺点、算法优化、算法重要参数、衡量指标以及案例等方面详细介绍KMeans算法。
KMeans
K均值(KMeans)是聚类中最常用的方法之一,基于点与点之间的距离的相似度来计算最佳类别归属。
KMeans算法通过试着将样本分离到 个方差相等的组中来对数据进行聚类,从而最小化目标函数 (见下文)。该算法要求指定集群的数量。它可以很好地扩展到大量的样本,并且已经在许多不同领域的广泛应用领域中使用。
被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。常用于客户分群、用户画像、精确营销、基于聚类的推荐系统。
算法原理
从 个样本数据中随机选取 个质心作为初始的聚类中心。质心记为
定义优化目标
开始循环,计算每个样本点到那个质心到距离,样本离哪个近就将该样本分配到哪个质心,得到K个簇
对于每个簇,计算所有被分到该簇的样本点的平均距离作为新的质心
直到 收敛,即所有簇不再发生变化。
KMeans迭代示意图
优化目标
KMeans 在进行类别划分过程及最终结果,始终追求"簇内差异小,簇间差异大",其中差异由样本点到其所在簇的质心的距离衡量。在KNN算法学习中,我们学习到多种常见的距离 ---- 欧几里得距离、曼哈顿距离、余弦距离。
在sklearn中的KMeans使用欧几里得距离:
则一个簇中所有样本点到质心的距离的平方和为:
其中, 为一个簇中样本的个数, 是每个样本的编号。这个公式被称为簇内平方和(cluster Sum of Square), 又叫做Inertia。
而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum of Square),又叫做Total Inertia。Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。因此 KMeans 追求的是,求解能够让Inertia最小化的质心。
KMeans有损失函数吗?
损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。KMeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一 种探索。
另外,在决策树中有衡量分类效果的指标准确度accuracy,准确度所对应的损失叫做泛化误差,但不能通过最小化泛化误差来求解某个模型中需要的信息,我们只是希望模型的效果上表现出来的泛化误差很小。因此决策树,KNN等算法,是绝对没有损失函数的。
虽然在sklearn中只能被动选用欧式距离,但其他距离度量方式同样可以用来衡量簇内外差异。不同距离所对应的质心选择方法和Inertia如下表所示, 在KMeans中,只要使用了正确的质心和距离组合,无论使用什么样的距离,都可以达到不错的聚类效果。
距离度量质心Inertia欧几里得距离均值最小化每个样本点到质心的欧式距离之和曼哈顿距离中位数最小化每个样本点到质心的曼哈顿距离之和余弦距离均值最小化每个样本点到质心的余弦距离之和
sklearn.cluster.KMeans
语法:
sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm='auto')
参数与接口详解见文末附录
例:
>>> from sklearn.cluster import KMeans>>> import numpy as np>>> X = np.array([[1, 2], [1, 4], [1, 0],... [10, 2], [10, 4], [10, 0]])>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)>>> kmeans.labels_array([1, 1, 1, 0, 0, 0], dtype=int32)>>> kmeans.predict([[0, 0], [12, 3]])array([1, 0], dtype=int32)>>> kmeans.cluster_centers_array([[10., 2.], [ 1., 2.]])
KMeans算法优缺点
优点
KMeans算法是解决聚类问题的一种经典算法, 算法简单、快速 。
算法尝试找出使平方误差函数值最小的 个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好 。
缺点
KMeans方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
要求用户必须事先给出要生成的簇的数目 。
对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
不适合于发现非凸面形状的簇,或者大小差别很大的簇。
KMeans本质上是一种基于欧式距离度量的数据划分方法,均值和方差大的维度将对数据的聚类结果产生决定性影响。所以在聚类前对数据(具体的说是每一个维度的特征)做归一化(点击查看归一化详解)和单位统一至关重要。此外,异常值会对均值计算产生较大影响,导致中心偏移,因此对于"噪声"和孤立点数据最好能提前过滤 。
KMeans算法优化
KMeans算法虽然效果不错,但是每一次迭代都需要遍历全量的数据,一旦数据量过大,由于计算复杂度过大迭代的次数过多,会导致收敛速度非常慢。
由KMeans算法原来可知,KMeans在聚类之前首先需要初始化 个簇中心,因此 KMeans算法对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。因初始化是个"随机"过程,很有可能 个簇中心都在同一个簇中,这种情况 KMeans 聚类算法很大程度上都不会收敛到全局最小。
想要优化KMeans算法的效率问题,可以从以下两个思路优化算法,一个是样本数量太大,另一个是迭代次数过多。
MiniBatchKMeans 聚类算法
mini batch 优化思想非常朴素,既然全体样本当中数据量太大,会使得我们迭代的时间过长,那么随机从整体当中做一个抽样,选取出一小部分数据来代替整体以达到缩小数据规模的目的。
mini batch 优化非常重要,不仅重要而且在机器学习领域广为使用。在大数据的场景下,几乎所有模型都需要做mini batch优化,而MiniBatchKMeans就是mini batch 优化的一个应用。直接上模型比较MiniBatchKMeans和KMeans两种算法计算速度(样本量1,000,000)
KMeans用时接近 6 秒钟,而MiniBatchKMeans 仅用时不到 1 秒钟
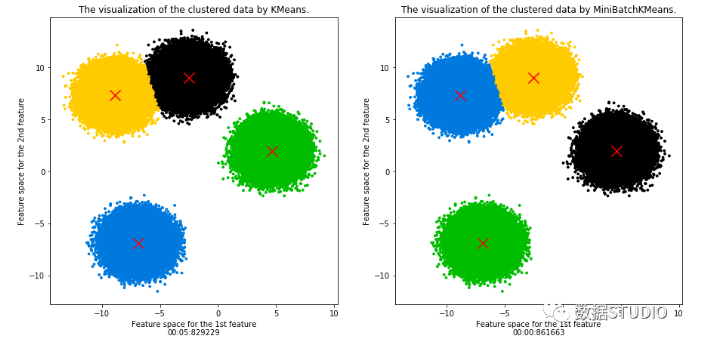
且聚类中心基本一致
>>> KMeans.cluster_centers_array([[-2.50889102, 9.01143598], [-6.88150415, -6.88090477], [ 4.63628843, 1.97271152], [-8.83895916, 7.32493568]])>>> MiniBatchKMeans.cluster_centers_array([[-2.50141353, 8.97807161], [-6.88418974, -6.87048909], [ 4.65410395, 1.99254911], [-8.84903186, 7.33075289]])
mini batch优化方法是通过减少计算样本量来达到缩短迭代时长,另一种方法是降低收敛需要的迭代次数,从而达到快速收敛的目的。收敛的速度除了取决于每次迭代的变化率之外,另一个重要指标就是迭代起始的位置。
2007年Arthur, David, and Sergei Vassilvitskii三人发表了论文"k-means++: The advantages of careful seeding" http://ilpubs.stanford.edu:8090/778/1/2006-13.pdf,他们开发了'k-means++'初始化方案,使得初始质心(通常)彼此远离,以此来引导出比随机初始化更可靠的结果。
'k-means++' 聚类算法
'k-means++'聚类算法是在KMeans算法基础上,针对迭代次数,优化选择初始质心的方法。sklearn.cluster.KMeans 中默认参数为 init='k-means++',其算法原理为在初始化簇中心时,逐个选取 个簇中心,且离其他簇中心越远的样本越有可能被选为下个簇中心。
算法步骤:
从数据即 中随机(均匀分布)选取一个样本点作为第一个初始聚类中心
计算每个样本与当前已有聚类中心之间的最短距离;再计算每个样本点被选为下个聚类中心的概率,最后选择最大概率值所对应的样本点作为下一个簇中心
重复上步骤,直到选择个聚类中心
'k-means++'算法初始化的簇中心彼此相距都十分的远,从而不可能再发生初始簇中心在同一个簇中的情况。当然'k-means++'本身也具有随机性,并不一定每一次随机得到的起始点都能有这么好的效果,但是通过策略,我们可以保证即使出现最坏的情况也不会太坏。
'k-means++' code:
def InitialCentroid(x, K): c1_idx = int(np.random.uniform(0, len(x))) # Draw samples from a uniform distribution. centroid = x[c1_idx].reshape(1, -1) # choice the first center for cluster. k = 1 n = x.shape[0] # number of samples while k < K: d2 = [] for i in range(n): subs = centroid - x[i, :] # D(x) = (x_1, y_1) - (x, y) dimension2 = np.power(subs, 2) # D(x)^2 dimension_s = np.sum(dimension2, axis=1) # sum of each row d2.append(np.min(dimension_s)) new_c_idx = np.argmax(d2) centroid = np.vstack([centroid, x[new_c_idx]]) k += 1 return centroid
重要参数
初始质心
KMeans算法的第一步"随机"在样本中抽取 个样本作为初始质心,因此并不符合"稳定且更快"的需求。因此可通过random_state参数来指定随机数种子,以控制每次生成的初始质心都在相同位置。
一个random_state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则 sklearn中的KMeans并不会只选择一个随机模式扔出结果,而会在每个随机数种子下运行多次,并使用结果最好的一个随机数种子来作为初始质心。我们可以使用参数n_init来选择,每个随机数种子下运行的次数。
而以上两种方法仍然避免不了基于随机性选取 个质心的本质。在sklearn中,我们使用参数init ='k-means++'来选择使用'k-means++'作为质心初始化的方案。
init : 可输入"k-means++","random"或者一个n维数组。这是初始化质心的方法,默认"k-means++"。输入"k- means++":一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
random_state : 控制每次质心随机初始化的随机数种子。
n_init : 整数,默认10,使用不同的质心随机初始化的种子来运行KMeans算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出。
迭代停止
max_iter : 整数,默认300,单次运行的KMeans算法的最大迭代次数。
tol : 浮点数,默认1e-4,两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下。
衡量指标
聚类模型的结果不是某种标签输出,并且聚类的结果是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。那么如何衡量聚类的效果呢?
衡量簇内差异来衡量聚类的效果
簇内平方和:Total_Inertia
肘部法(手肘法)认为图上的拐点就是 的最佳值。
# 应用肘部法则确定 kmeans方法中的kfrom scipy.spatial.distance import cdist # 计算两个输入集合的每对之间的距离。from sklearn.cluster import KMeansimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom sklearn.datasets import make_blobsplt.style.use('seaborn')plt.rcParams['font.sans-serif']=['Simhei'] #显示中文plt.rcParams['axes.unicode_minus']=False #显示负号X, y = make_blobs(n_samples=5000, centers=4, cluster_std = 2.5, n_features=2,random_state=42)K=range(1,10)# 直接计算ssesse_result=[]for k in K: kmeans=KMeans(n_clusters=k, random_state=666) kmeans.fit(X) sse_result.append(sum(np.min(cdist(X,kmeans.cluster_centers_,'euclidean'),axis=1))/X.shape[0])plt.figure(figsize=(16,5))plt.subplot(1,2,1)plt.plot(K,sse_result,'gp-')plt.xlabel('k',fontsize=20)plt.ylabel(u'平均畸变程度')plt.title(u'肘部法则确定最佳的K值(1)',fontdict={'fontsize':15})# 第二种,使用inertia_L = []for k in K: kmeans = KMeans(n_clusters=k, random_state=666) kmeans.fit(X) L.append((k, kmeans.inertia_))a = pd.DataFrame(L)a.columns = ['k', 'inertia']plt.subplot(1,2,2)plt.plot(a.k, a.inertia,'gp-')plt.xlabel('k',fontsize=20)plt.ylabel('inertia')plt.title(u'肘部法则确定最佳的K值(2)',fontdict={'fontsize':15})plt.xticks(a.k)plt.show();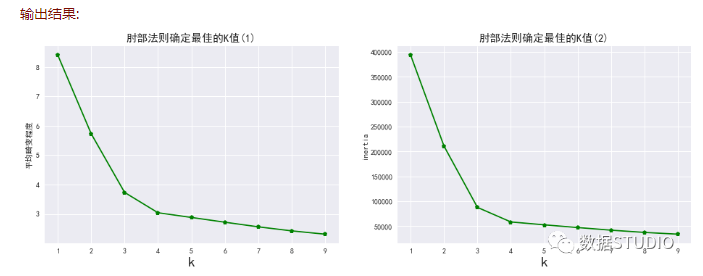
但其有很大的局限:
它的计算太容易受到特征数目的影响。
它不是有界的,Inertia是越小越好,但并不知道合适达到模型的极限,能否继续提高。
它会受到超参数 的影响,随着 越大,Inertia注定会越来越小,但并不代表模型效果越来越好。
Inertia对数据的分布有假设,它假设数据满足凸分布,并且它假设数据是各向同性的( isotropic),所以使用Inertia作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳。
其他衡量指标
1、真实标签已知时
可以用聚类算法的结果和真实结果来衡量聚类的效果。但需要用到聚类分析的场景,大部分均属于无真实标签的情况,因此以下模型评估指标了解即可。
模型评估指标说明互信息分
普通互信息分
metrics.adjusted_mutual_info_score (y_pred, y_true)
调整的互信息分
metrics.mutual_info_score (y_pred, y_true)
标准化互信息分
metrics.normalized_mutual_info_score (y_pred, y_true)取值范围在(0,1)之中越接近1,
聚类效果越好在随机均匀聚类下产生0分。V-measure:基于条件上分析的一系列直观度量
同质性:是否每个簇仅包含单个类的样本
metrics.homogeneity_score(y_true, y_pred)
完整性:是否给定类的所有样本都被分配给同一个簇中
metrics.completeness_score(y_true, y_pred)
同质性和完整性的调和平均,叫做V-measure
metrics.v_measure_score(labels_true, labels_pred)
三者可以被一次性计算出来:
metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)取值范围在(0,1)之中越接近1,
聚类效果越好由于分为同质性和完整性两种度量,可以更仔细地研究,模型到底哪个任务做得不够好。对样本分布没有假设,在任何分布上都可以有不错的表现在随机均匀聚类下不会产生0分。调整兰德系数
metrics.adjusted_rand_score(y_true, y_pred)取值在(-1,1)之间,负值象征着簇内的点差异巨大,甚至相互独立,正类的 兰德系数比较优秀,
越接近1越好对样本分布没有假设,在任何分布上都可以有不错的表现,尤其是在具有"折叠"形状的数据上表现优秀,在随机均匀聚类下产生0分。2、真实标签未知时
轮廓系数
对没有真实标签的数据进行探索,常用轮廓系数评价聚类算法模型效果。
样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离 。
样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中的所有点之间的平均距离。
根据聚类的要求"簇内差异小,簇外差异大",我们希望b永远大于a,并且大得越多越好。单个样本的轮廓系数计算为:
组内差异,组间差异
取值范围越大越好。
越接近 1 表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。
当轮廓系数为 0 时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。
语法:
from sklearn.metrics import silhouette_score# 返回所有样本的轮廓系数的均值from sklearn.metrics import silhouette_samples# 返回的是数据集中每个样本自己的轮廓系数silhouette_score(X,y_pred)silhouette_score(X,cluster_.labels_)silhouette_samples(X,y_pred)
例:
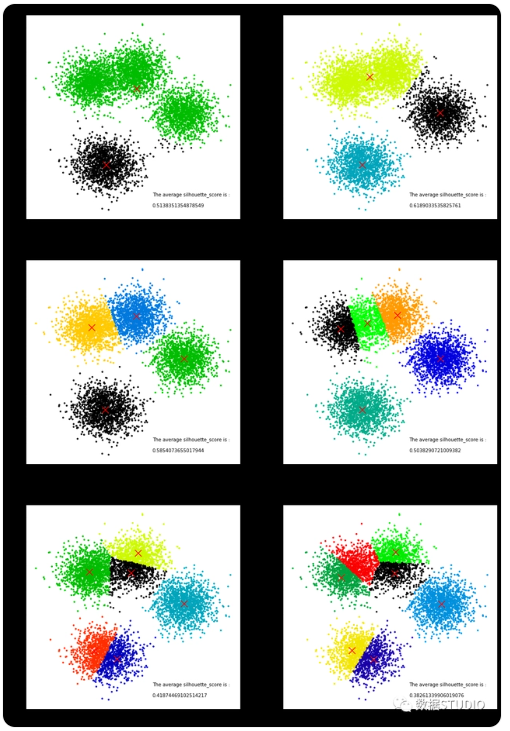
L = []for i in range(2, 20): k = i kmeans = KMeans(n_clusters=i) kmeans.fit(X) L.append([i, silhouette_score(X, kmeans.labels_)])a = pd.DataFrame(L)a.columns = ['k', '轮廓系数']plt.figure(figsize=(8, 5), dpi=70)plt.plot(a.k, a.轮廓系数,'gp-')plt.xticks(a.k)plt.xlabel('k')plt.ylabel('轮廓系数')plt.title('轮廓系数确定最佳的K值',fontdict={'fontsize':15})输出结果:
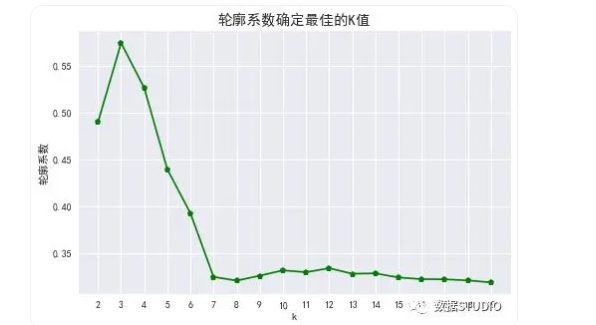
轮廓系数看出,k=3时轮廓系数最大,肘部法的拐点亦是k=3,从数据集可视化图(文末案例)中也能看出数据集可以清洗分割3个簇(虽然初始创建了四个簇,但上面两个簇边界并不清晰,几乎连到一起)。
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个"参考"。并且轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。
其它评估指标
评估指标sklearn.metrics卡林斯基-哈拉巴斯指数
Calinski-Harabaz
Indexcalinski_harabaz_score (X, y_pred)戴维斯-布尔丁指数
Davies-Bouldindavies_bouldin_score (X, y_pred)权变矩阵
Contingencycluster.contingency_matrix (X, y_pred)
这里简单介绍卡林斯基-哈拉巴斯指数,有 个簇的聚类而言, Calinski-Harabaz指数写作如下公式:
其中为数据集中的样本量,为簇的个数(即类别的个数), 是组间离散矩阵,即不同簇之间的协方差矩阵, 是簇内离散矩阵,即一个簇内数据的协方差矩阵,而表示矩阵的迹。在线性代数中,一个矩阵的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作。
数据之间的离散程度越高,协方差矩阵的迹就会越大。组内离散程度低,协方差的迹就会越小,也就越小,同时,组间离散程度大,协方差的的迹也会越大,就越大,因此Calinski-harabaz指数越高越好。
虽然calinski-Harabaz指数没有界,在凸型的数据上的聚类也会表现虚高。但是比起轮廓系数,其计算非常快速。
案例
from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_samples, silhouette_scoreimport matplotlib.pyplot as pltimport matplotlib.cm as cmimport numpy as npimport pandas as pdfrom sklearn.datasets import make_blobsX, y = make_blobs(n_samples=6000, centers=4, cluster_std = 2.5, n_features=2,center_box=(-12.0, 12.0), random_state=42)data = pd.DataFrame(X)fig, axes = plt.subplots(3, 2)fig.set_size_inches(18, 27)n_clusters = 2for i in range(3): for j in range(2): n_clusters = n_clusters clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X) cluster_labels = clusterer.labels_ silhouette_avg = silhouette_score(X, cluster_labels) print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg) sample_silhouette_values = silhouette_samples(X, cluster_labels) colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters) axes[i,j].scatter(X[:, 0], X[:, 1] ,marker='o' ,s=8 ,c=colors ) centers = clusterer.cluster_centers_ axes[i,j].scatter(centers[:, 0], centers[:, 1], marker='x', c="red", alpha=1, s=200) axes[i,j].set_title(f"The visualization of the clustered data when n_Clusters = {n_clusters}.") axes[i,j].set_xlabel("Feature space for the 1st feature") axes[i,j].set_ylabel("Feature space for the 2nd feature") axes[i,j].text(0,-17,f"The average silhouette_score is :\n\n{silhouette_avg}",fontsize=10) n_clusters += 1plt.show()输出结果:
扩展--其他聚类算法
DBSCAN
从向量数组或距离矩阵执行DBSCAN聚类。
一种基于密度的带有噪声的空间聚类 。它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据集中发现任意形状的聚类。
基于密度的空间聚类与噪声应用。寻找高密度的核心样本,并从中扩展星团。适用于包含相似密度的簇的数据。
DBSCAN算法将聚类视为由低密度区域分隔的高密度区域。由于这种相当通用的观点,DBSCAN发现的集群可以是任何形状,而k-means假设集群是凸形的。DBSCAN的核心组件是核心样本的概念,即位于高密度区域的样本。因此,一个集群是一组彼此接近的核心样本(通过一定的距离度量)和一组与核心样本相近的非核心样本(但它们本身不是核心样本)。算法有两个参数,min_samples和eps,它们正式定义了我们所说的密集。较高的min_samples或较低的eps表示较高的密度需要形成一个集群。
根据定义,任何核心样本都是集群的一部分。任何非核心样本,且与核心样本的距离至少为eps的样本,都被算法认为是离群值。
而主要控制参数min_samples宽容的算法对噪声(在嘈杂和大型数据集可能需要增加此参数),选择适当的参数eps至关重要的数据集和距离函数,通常不能在默认值。它控制着点的局部邻域。如果选择的数据太小,大多数数据根本不会聚集在一起(并且标记为-1表示"噪音")。如果选择太大,则会导致关闭的集群合并为一个集群,并最终将整个数据集作为单个集群返回。
例:
>>> from sklearn.cluster import DBSCAN>>> import numpy as np>>> X = np.array([[1, 2], [2, 2], [2, 3],... [8, 7], [8, 8], [25, 80]])>>> clustering = DBSCAN(eps=3, min_samples=2).fit(X)>>> clustering.labels_array([ 0, 0, 0, 1, 1, -1])>>> clusteringDBSCAN(eps=3, min_samples=2)
eps float, default=0.5
两个样本之间的最大距离,其中一个样本被认为是相邻的。这不是集群内点的距离的最大值,这是为您的数据集和距离函数选择的最重要的DBSCAN参数。
min_samples int, default=5
被视为核心点的某一邻域内的样本数(或总权重)。这包括点本身。
更多DBSCAN聚类请参见
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN
层次聚类
层次聚类Hierarchical Clustering 通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并和自上而下分裂两种方法。
层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。
简单来说 通过计算每一个类别的数据点与所有数据点之间的欧式距离来确定它们之间的相似性,距离越小,相似度越高 。并将距离最近的两个数据点或类别进行组合,生成聚类树。
例:
>>> from sklearn.cluster import AgglomerativeClustering>>> import numpy as np>>> X = np.array([[1, 2], [1, 4], [1, 0],... [4, 2], [4, 4], [4, 0]])>>> clustering = AgglomerativeClustering().fit(X)>>> clusteringAgglomerativeClustering()>>> clustering.labels_array([1, 1, 1, 0, 0, 0])
层次化聚类是一种通用的聚类算法,它通过合并或分割来构建嵌套的聚类。集群的层次结构表示为树(或树状图)。树的根是收集所有样本的唯一集群,叶子是只有一个样本的集群。
聚类对象使用自底向上的方法执行分层聚类: 每个观察从它自己的聚类开始,然后聚类依次合并在一起。连接标准决定了用于合并策略的度量。
最大或完全连接使簇对观测之间的最大距离最小。
平均连接使簇对的所有观测值之间的平均距离最小化。
单连接使簇对的最近观测值之间的距离最小。
当与连通性矩阵联合使用时,团聚向量聚合也可以扩展到大量的样本,但是当样本之间不加连通性约束时,计算开销就大了:它在每一步都考虑所有可能的合并。
更多层次聚类请参见
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html#sklearn.cluster.AgglomerativeClustering
附录
KMeans参数
n_clusters int, default=8
要聚成的簇数,以及要生成的质心数。
init {‘k-means++’, ‘random’, ndarray, callable}, default=’k-means++’
这是初始化质心的方法,输入"k- means++": 一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
n_init int, default=10
使用不同的质心随机初始化的种子来运行KMeans算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出。
max_iter int, default=300
单次运行的KMeans算法的最大迭代次数。
tol float, default=1e-4
两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下。
precompute_distances {‘auto’, True, False}, default=’auto’
预计算距离(更快,但需要更多内存)。
'auto': 如果 n_samples * n_clusters > 1200万,不要预先计算距离。这对应于使用双精度来学习,每个作业大约100MB的内存开销。
True: 始终预先计算距离。False:从不预先计算距离。
verbose int, default=0
计算中的详细模式。
random_state int, RandomState instance, default=None
确定质心初始化的随机数生成。使用int可以是随机性更具有确定性。
copy_x bool, default=True
在预计算距离时,若先中心化数据,距离的预计算会更加准确。如果copy_x为True(默认值),则不会修改原始数据,确保特征矩阵X是c-contiguous。如果为False,则对原始数据进行修改,在函数返回之前放回原始数据,但可以通过减去数据平均值,再加上数据平均值,引入较小的数值差异。注意,如果原始数据不是c -连续的,即使copy_x为False,也会复制,这可能导致KMeans 计算量显著变慢。如果原始数据是稀疏的,但不是CSR格式的,即使copy_x是False的,也会复制一份。
n_jobs int, default=None
用于计算的作业数。计算每个n_init时并行作业数。
这个参数允许KMeans在多个作业线上并行运行。给这个参数正值n_jobs,表示使用 n_jobs 条处理器中的线程。值-1表示使用所用可用的处理器。值-2表示使用所有可能的处理器-1个处理器,以此类推。并行化通常以内存为代价增加计算(这种情况下,需要存储多个质心副本,每个作业一个)
algorithm {“auto”, “full”, “elkan”}, default=”auto”
使用KMeans算法。经典的EM风格的算法是"full"的。通过使用三角不等式,"elkan"变异在具有定义明确的集群的数据上更有效。然而,由于分配了额外的形状数组(n_samples、n_clusters),它会占用更多的内存。目前,"auto" 为密集数据选择 "elkan" 为稀疏数据选择"full"。
KMeans属性
cluster_centers_ ndarray of shape (n_clusters, n_features)
收敛到的质心坐标。如果算法在完全收敛之前已停止(受到'tol'和'max_iter'参数的控制),这些返回的内容将与'labels_'中反应出的聚类结果不一致。
labels_ ndarray of shape (n_samples,)
每个样本对应的标签。
inertia_ float
每个样本点到它们最近的簇中心的距离的平方的和,又叫做"簇内平方和"。
n_iter_ int
实际迭代的次数。
聚类分析的基本概念和方法
URL:https://blog.csdn.net/qq_51294669/article/details/128048680/
一、什么是聚类分析
聚类分析: 是把一个数据对象划分成子集的过程,每个子集是一个簇,满足一下两点:
簇中对象彼此相似。
簇间对象彼此相异。
说到了聚类分析,就离不开无监督学习:没有预先定义的类
聚类分析典型的应用:
作为洞悉数据分布的独立工具。
作为其他算法的预处理步骤。
1、聚类分析基本流程与步骤
1、特征选择:
选择跟任务相关的信息。
最小化信息冗余。
2、邻近性度量:两个特征向量的相似性。
3、聚类准则:通过成本函数或一些规则表示。
4、聚类算法:选择聚类算法。
5、聚类评估:验证测试。
6、结果解释:集成在应用中。
2、 什么是好的聚类方法
一个好的聚类方法可以产生高质量的簇:
高类内相似性,簇内的内聚性。
低类间相似性,簇间区别。
聚类方法的质量取决于:
该方法采用的相似度量和它的实现。
它能够发现一些或所有隐藏的模式。
说白了,就是把数据集分成几个子集,越容易区分越好。
3、聚类的模型评估
相似性度量:
相似性度量通常用距离表示:d(i, j).
不同类型的数据(布尔值、分类、序数比、向量变量),距离函数存在很大的差异。
根据应用和数据语义,权重应该与不同的变量相关联。
聚类质量:
通常有一个单独的 “质量” 函数来度量簇的 “质量”。
很难定义 “足够相似” 和 “足够好”,答案通常都是非常主管的。
4、聚类分析的比较
划分标准:单层分区与分层分区(通常多级分层分区更容易描述)。
簇的分离性:排他性(一个客户只属于一个区域)与非排他性(一个文档可能属于多个类)。
相似性度量:基于距离的(欧几里得,曼哈顿、切比雪夫),基于联通的(密度或连通性)。
聚类空间:全空间(通常在低纬度)与子空间(通常在高纬度集群中)
5、聚类分析的挑战
可伸缩性:对多有数据进行聚类,而不是对样本聚类。
能够处理不同类型的属性:数值的、二元的、序数的。
基于约束的聚类:用户可以输入约束条件,使用领域知识确定输入参数。
用于决定输入参数的领域知识最小化。可解释性和可应用性强。
其他:发现具有任意形状的簇,能够处理有噪声的数据,增量聚类和对输入顺序不敏感,高纬度数据。
二、基本聚类方法概述
划分方法:构造不同的分区,然后根据一些标准对他们进行评估。典型的方法有:K-means,K-中心点,CLARANS.
层次方法:使用一些标准对数据集分层。典型的方法:Diana,Agnes,BIRCH,CAMELEON.
基于密度的方法:基于连通性和密度函数。典型方法:DBSCAN,OPTICS,DenClue.
基于网络的方法:基于多粒度结构。典型的方法:STING,WaveCluster,CLIQUE
方法 一般特点
划分方法 ①发现球形互斥的簇 ②基于距离 ③可以使用均值或中心点等代表簇中心 ④对中小数据规模有效
层次方法 ①聚类是一个层次分解 ②不能纠正错误的合并或划分 ③可以集成其他技术,如微聚类或考虑对象链接
基于密度方法 ①可以发现任意形状的簇 ②簇是对象空间中被低密度区域分隔的稠密区域 ③簇密度:每个点的邻域内必须具有多少个点(阈值点)④可能过滤离群点
基于网络的方法 ①使用一种多分辨率网格数据结构 ②快速处理(典型地,独立于数据对象,但依赖于网格大小)
三、划分算法
1、基本概念

2、k-means 聚类方法

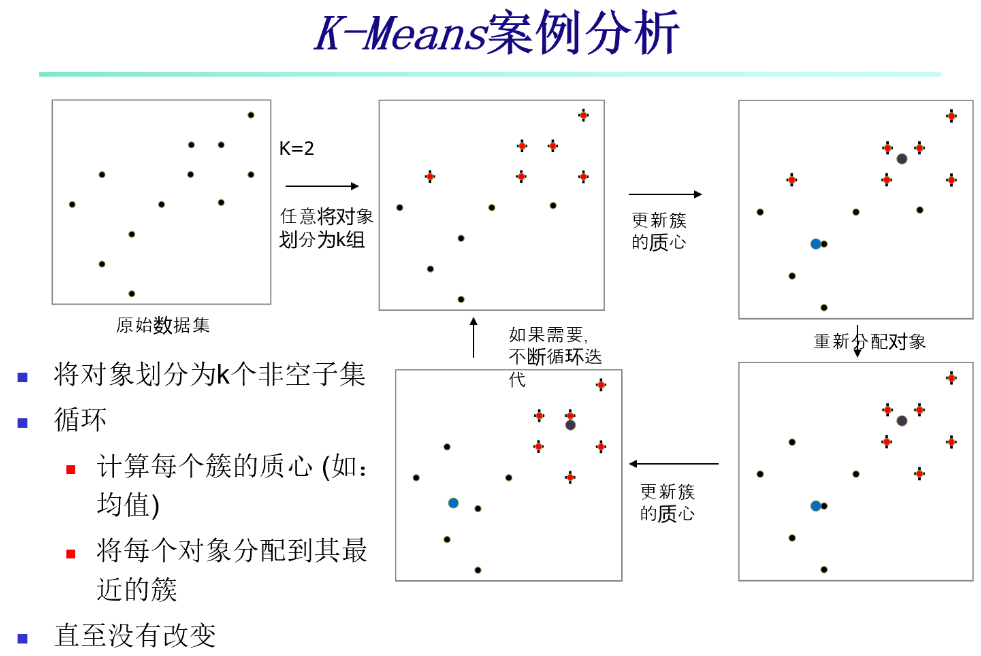
1、k-means 方法的优缺点
优点:
擅长处理球状分布的数据,当结果聚类是密集的,而且类和类直接的区别比较明显时,k-means 算法的效
果较好。
对于处理大数据集,是相对可伸缩和高效的,复杂度是 O(nkt), n 是对象个数,k 是簇的数目,t 是迭代的
次数。
相比较其他的算法简单,容易掌握。
缺点:
需要预先指定集群的数量 k (有自动确定 k 最佳的方法)
对噪声和离群点敏感。
不适合发现非凸形状的簇。
2、k-means 方法的变种
大多数 k-means 方法的变种在于以下几个方面;
初始 k 平均值的选择。
相异度的计算。(距离公式)
计算聚类平均值的策略。(中心点)
处理分类数据 k-众数:
用众数代替聚类的平均值。
使用新的相异性度量方法来处理分类对象。
用基于频率的方法来更新聚类的众数。
k-prototype:一种混合处理分类数据和数值数据的方法。
注意:k-means 算法对孤立点很敏感:均值由于极大值的对象可能会严重的扭曲数据的分布。
3、k-中心聚类方法
k-medoids(k-中心) :不采用簇中对象的平均值作为参照点,而是选用簇中位置最中心的对象最为参照点
,也就是簇中心肯定是一个对象。
k-中心 基本思想:
首先为每个簇随意选择一个代表对象;剩余的对象根据其与代表对象的距离分配给最近的一个簇。
反复地使用非代表对象来替代代表对象,以改进聚类的质量。
聚类结果的质量用一个代价函数来估算,该函数评估了对象与其参照对象之间的平均相异度。
PMA (Partitioning Around Medoids,1987)就是利用上述方法,它对于较小的数据集非常有效,但不能很好
的扩展到大型数据集。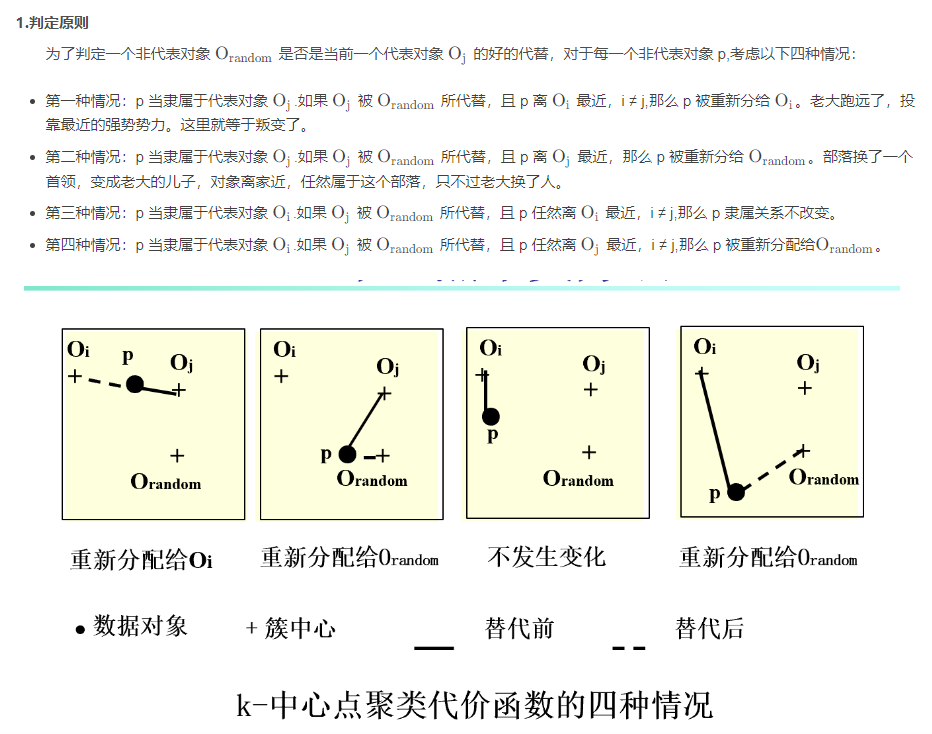
2、步骤
算法 k-中心:
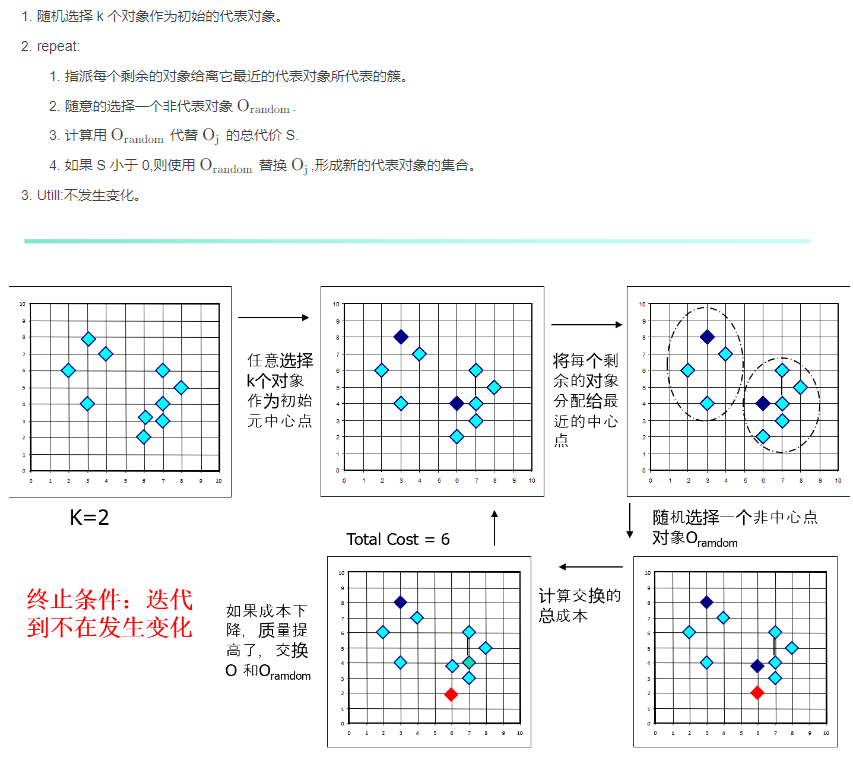
层次聚类
使用距离矩阵作为聚类准则。这个方法不需要簇 k 的数量作为输入,但是需要一个终止条件。
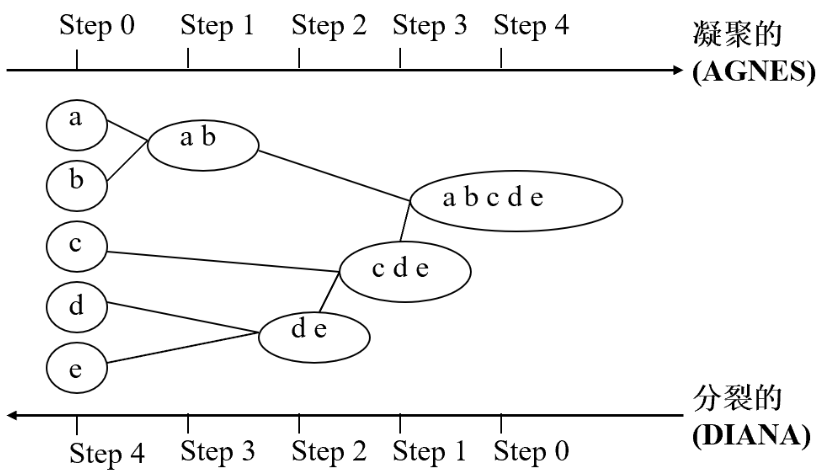
上图就是 AGNES 算法和 DIANA 算法简略图,这个不作为重点学习,需要了解的请查阅别处资料。
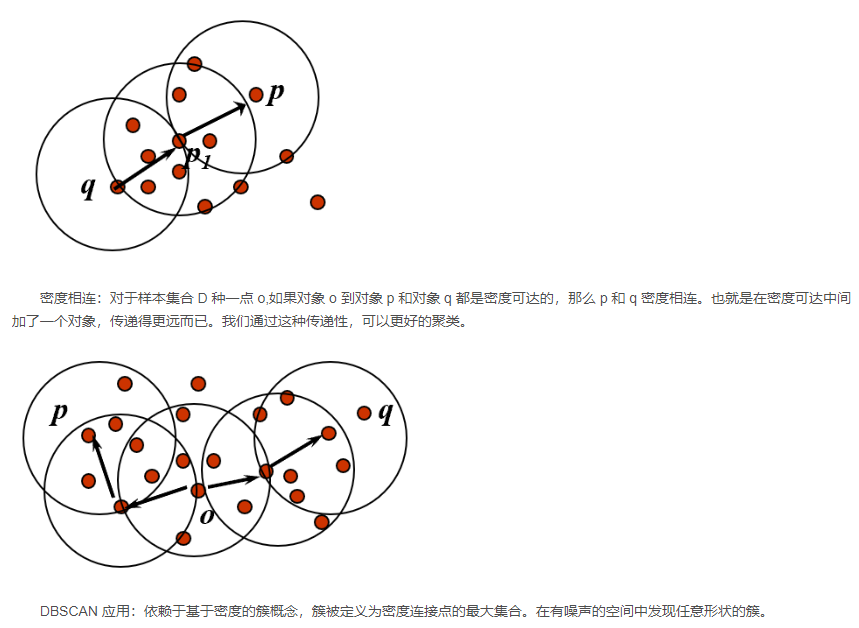
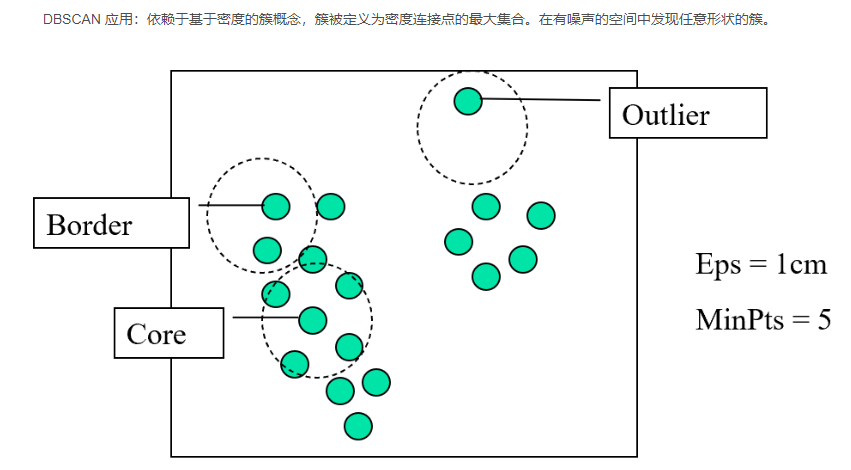
4、 密度聚类(重点DBSCAN)

心得
介绍了聚类里面基础的知识和几个三个经典的聚类算法。这只是一种认识,希望可以带来入门级的理解,需要熟练掌握的话要多用。对于机器学习的友友们,算法的基本流程可能不能满足你们,实现出来或者要看清怎么实现的具体细节还需要自己去哔站搜索。算法是美丽的,过程简单,实现简单,关键要我们怎么开拓思维。好的数学功底,编程能力,语言组织(怎么转换成数学语言,怎么讲清刚认识的算法)都是干我们这行所具备的。模仿吧,模仿多了直到那些人的作品不好,再往后面知道怎么改造形成自己喜欢的风格,最后就是你自己的了。
SQL函数浅总结,使用方法及实例讲解大全
URL:https://zhuanlan.zhihu.com/p/498554620?utm_id=0
SQL 函数
SQL 拥有很多可用于计数和计算的内建函数。
函数的语法
内建 SQL 函数的语法是:
SELECT function (列) FROM 表
函数的类型
在 SQL 中,基本的函数类型和种类有若干种。函数的基本类型是:
Aggregate 函数
Scalar 函数
合计函数(Aggregate functions)
Aggregate 函数的操作面向一系列的值,并返回一个单一的值。
注释:如果在 SELECT 语句的项目列表中的众多其它表达式中使用 SELECT 语句,则这个 SELECT 必须使用 GROUP BY 语句!
"Persons" table (在大部分的例子中使用过)
Name | Age |
Adams, John | 38 |
Bush, George | 33 |
Carter, Thomas | 28 |
MS Access 中的合计函数
函数 | 描述 |
AVG(column) | 返回某列的平均值 |
COUNT(column) | 返回某列的行数(不包括 NULL 值) |
COUNT(*) | 返回被选行数 |
FIRST(column) | 返回在指定的域中第一个记录的值 |
LAST(column) | 返回在指定的域中最后一个记录的值 |
MAX(column) | 返回某列的最高值 |
MIN(column) | 返回某列的最低值 |
STDEV(column) | |
STDEVP(column) | |
SUM(column) | 返回某列的总和 |
VAR(column) | |
VARP(column) |
在 SQL Server 中的合计函数
函数 | 描述 |
AVG(column) | 返回某列的平均值 |
BINARY_CHECKSUM | |
CHECKSUM | |
CHECKSUM_AGG | |
COUNT(column) | 返回某列的行数(不包括NULL值) |
COUNT(*) | 返回被选行数 |
COUNT(DISTINCT column) | 返回相异结果的数目 |
FIRST(column) | 返回在指定的域中第一个记录的值(SQLServer2000 不支持) |
LAST(column) | 返回在指定的域中最后一个记录的值(SQLServer2000 不支持) |
MAX(column) | 返回某列的最高值 |
MIN(column) | 返回某列的最低值 |
STDEV(column) | |
STDEVP(column) | |
SUM(column) | 返回某列的总和 |
VAR(column) | |
VARP(column) |
Scalar 函数
Scalar 函数的操作面向某个单一的值,并返回基于输入值的一个单一的值。
MS Access 中的 Scalar 函数
函数 | 描述 |
UCASE(c) | 将某个域转换为大写 |
LCASE(c) | 将某个域转换为小写 |
MID(c,start[,end]) | 从某个文本域提取字符 |
LEN(c) | 返回某个文本域的长度 |
INSTR(c,char) | 返回在某个文本域中指定字符的数值位置 |
LEFT(c,number_of_char) | 返回某个被请求的文本域的左侧部分 |
RIGHT(c,number_of_char) | 返回某个被请求的文本域的右侧部分 |
ROUND(c,decimals) | 对某个数值域进行指定小数位数的四舍五入 |
MOD(x,y) | 返回除法操作的余数 |
NOW() | 返回当前的系统日期 |
FORMAT(c,format) | 改变某个域的显示方式 |
DATEDIFF(d,date1,date2) | 用于执行日期计算 |
SQL AVG 函数
定义和用法
AVG 函数返回数值列的平均值。NULL 值不包括在计算中。
SQL AVG() 语法
SELECT AVG (column_name) FROM table_name
SQL AVG() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
例子 1
现在,我们希望计算 "OrderPrice" 字段的平均值。
我们使用如下 SQL 语句:
SELECT AVG (OrderPrice) AS Order Average FROM Orders
结果集类似这样:
OrderAverage |
950 |
例子 2
现在,我们希望找到 OrderPrice 值高于 OrderPrice 平均值的客户。
我们使用如下 SQL 语句:
SELECT Customer FROM Orders
WHERE OrderPrice>(SELECT AVG (OrderPrice) FROM Orders)
结果集类似这样:
Customer |
Bush |
Carter |
Adams |
SQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SQL COUNT() 语法
SQL COUNT(column_name) 语法
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT (column_name) FROM table_name
SQL COUNT(*) 语法
COUNT(*) 函数返回表中的记录数:
SELECT COUNT (*) FROM table_name
SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT (DISTINCTcolumn_name) FROMt able_name
注释:COUNT(DISTINCT) 适用于 ORACLE 和 Microsoft SQL Server,但是无法用于 Microsoft Access。
SQL COUNT(column_name) 实例
我们拥有下列 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望计算客户 "Carter" 的订单数。
我们使用如下 SQL 语句:
SELECT COUNT (Customer) AS CustomerNilsen FROM Orders
WHERE Customer='Carter'
以上 SQL 语句的结果是 2,因为客户 Carter 共有 2 个订单:
CustomerNilsen |
2 |
SQL COUNT(*) 实例
如果我们省略 WHERE 子句,比如这样:
SELECT COUNT(*) ASNumberOfOrders FROMOrders
结果集类似这样:
NumberOfOrders |
6 |
这是表中的总行数。
SQL COUNT(DISTINCT column_name) 实例
现在,我们希望计算 "Orders" 表中不同客户的数目。
我们使用如下 SQL 语句:
SELECT COUNT(DISTINCTCustomer) ASNumberOfCustomers FROMOrders
结果集类似这样:
NumberOfCustomers |
3 |
这是 "Orders" 表中不同客户(Bush, Carter 和 Adams)的数目。>
SQL FIRST() 函数
FIRST() 函数
FIRST() 函数返回指定的字段中第一个记录的值。
提示:可使用 ORDER BY 语句对记录进行排序。
SQL FIRST() 语法
SELECT FIRST (column_name) FROMt able_name
SQL FIRST() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的第一个值。
我们使用如下 SQL 语句:
SELECT FIRST (OrderPrice) AS FirstOrderPrice FROM Orders
结果集类似这样:
FirstOrderPrice |
1000 |
SQL LAST() 函数
LAST() 函数
LAST() 函数返回指定的字段中最后一个记录的值。
提示:可使用 ORDER BY 语句对记录进行排序。
SQL LAST() 语法
SELECT LAST (column_name) FROM table_name
SQL LAST() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最后一个值。
我们使用如下 SQL 语句:
SELECT LAST (OrderPrice) AS LastOrderPrice FROM Orders
结果集类似这样:
LastOrderPrice |
100 |
SQL MAX() 函数
MAX() 函数
MAX 函数返回一列中的最大值。NULL 值不包括在计算中。
SQL MAX() 语法
SELECT MAX (column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
SQL MAX() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最大值。
我们使用如下 SQL 语句:
SELECT MAX (OrderPrice) AS LargestOrderPrice FROM Orders
结果集类似这样:
LargestOrderPrice |
2000 |
SQL MIN() 函数
MIN() 函数
MIN 函数返回一列中的最小值。NULL 值不包括在计算中。
SQL MIN() 语法
SELECT MIN (column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
SQL MIN() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 列的最小值。
我们使用如下 SQL 语句:
SELECT MIN (OrderPrice) ASS mallestOrderPrice FROM Orders
结果集类似这样:
SmallestOrderPrice |
1 |
SQL SUM() 函数
SUM() 函数
SUM 函数返回数值列的总数(总额)。
SQL SUM() 语法
SELECTSUM(column_name) FROMtable_name
SQL SUM() 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找 "OrderPrice" 字段的总数。
我们使用如下 SQL 语句:
SELECTSUM(OrderPrice) ASOrderTotal FROMOrders
结果集类似这样:
OrderTotal |
5700 |
SQL GROUP BY 语句
合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句。
GROUP BY 语句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BYcolumn_name
SQL GROUP BY 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找每个客户的总金额(总订单)。
我们想要使用 GROUP BY 语句对客户进行组合。
我们使用下列 SQL 语句:
SELECT Customer,SUM (OrderPrice) FROM Orders
GROUP BY Customer
结果集类似这样:
Customer | SUM(OrderPrice) |
Bush | 2000 |
Carter | 1700 |
Adams | 2000 |
很棒吧,对不对?
让我们看一下如果省略 GROUP BY 会出现什么情况:
SELECT Customer,SUM (OrderPrice) FROM Orders
结果集类似这样:
Customer | SUM(OrderPrice) |
Bush | 5700 |
Carter | 5700 |
Bush | 5700 |
Bush | 5700 |
Adams | 5700 |
Carter | 5700 |
上面的结果集不是我们需要的。
那么为什么不能使用上面这条 SELECT 语句呢?解释如下:上面的 SELECT 语句指定了两列(Customer 和 SUM(OrderPrice))。"SUM(OrderPrice)" 返回一个单独的值("OrderPrice" 列的总计),而 "Customer" 返回 6 个值(每个值对应 "Orders" 表中的每一行)。因此,我们得不到正确的结果。不过,您已经看到了,GROUP BY 语句解决了这个问题。
GROUP BY 一个以上的列
我们也可以对一个以上的列应用 GROUP BY 语句,就像这样:
SELECT Customer,OrderDate,SUM (OrderPrice) FROM Orders
GROUP BY Customer,OrderDate
SQL HAVING 语句
HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
SQL HAVING 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BYcolumn_name
HAVIN Gaggregate_function(column_name) operator value
SQL HAVING 实例
我们拥有下面这个 "Orders" 表:
O_Id | OrderDate | OrderPrice | Customer |
1 | 2008/12/29 | 1000 | Bush |
2 | 2008/11/23 | 1600 | Carter |
3 | 2008/10/05 | 700 | Bush |
4 | 2008/09/28 | 300 | Bush |
5 | 2008/08/06 | 2000 | Adams |
6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找订单总金额少于 2000 的客户。
我们使用如下 SQL 语句:
SELECT Customer,SUM (OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000
结果集类似:
Customer | SUM(OrderPrice) |
Carter | 1700 |
现在我们希望查找客户 "Bush" 或 "Adams" 拥有超过 1500 的订单总金额。
我们在 SQL 语句中增加了一个普通的 WHERE 子句:
SELECT Customer,SUM (OrderPrice) FROM Orders
WHERE Customer='Bush'OR Customer='Adams'GROUP BY Customer
HAVING SUM (OrderPrice)>1500
结果集:
Customer | SUM(OrderPrice) |
Bush | 2000 |
Adams | 2000 |
SQL UCASE() 函数
UCASE() 函数
UCASE 函数把字段的值转换为大写。
SQL UCASE() 语法
SELECT UCASE(column_name) FROM table_name
SQL UCASE() 实例
我们拥有下面这个 "Persons" 表:
Id | LastName | FirstName | Address | City |
1 | Adams | John | Oxford Street | London |
2 | Bush | George | Fifth Avenue | New York |
3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为大写。
我们使用如下 SQL 语句:
SELECT UCASE (LastName) as LastName,FirstName FROM Persons
结果集类似这样:
LastName | FirstName |
ADAMS | John |
BUSH | George |
CARTER | Thomas |
SQL LCASE() 函数
LCASE() 函数
LCASE 函数把字段的值转换为小写。
SQL LCASE() 语法
SELECT LCASE (column_name) FROM table_name
SQL LCASE() 实例
我们拥有下面这个 "Persons" 表:
Id | LastName | FirstName | Address | City |
1 | Adams | John | Oxford Street | London |
2 | Bush | George | Fifth Avenue | New York |
3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为小写。
我们使用如下 SQL 语句:
SELECTLCASE(LastName) as LastName,FirstName FROMPersons
结果集类似这样:
LastName | FirstName |
adams | John |
bush | George |
carter | Thomas |
SQL MID() 函数
MID() 函数
MID 函数用于从文本字段中提取字符。
SQL MID() 语法
SELECT MID (column_name,start[,length]) FROMt able_name
参数 | 描述 |
column_name | 必需。要提取字符的字段。 |
start | 必需。规定开始位置(起始值是 1)。 |
length | 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。 |
SQL MID() 实例
我们拥有下面这个 "Persons" 表:
Id | LastName | FirstName | Address | City |
1 | Adams | John | Oxford Street | London |
2 | Bush | George | Fifth Avenue | New York |
3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望从 "City" 列中提取前 3 个字符。
我们使用如下 SQL 语句:
SELECT MID (City,1,3) asSmallCity FROM Persons
结果集类似这样:
SmallCity |
Lon |
New |
Bei |
SQL LEN() 函数
LEN() 函数
LEN 函数返回文本字段中值的长度。
SQL LEN() 语法
SELECTLEN(column_name) FROMtable_name
SQL LEN() 实例
我们拥有下面这个 "Persons" 表:
Id | LastName | FirstName | Address | City |
1 | Adams | John | Oxford Street | London |
2 | Bush | George | Fifth Avenue | New York |
3 | Carter | Thomas | Changan Street | Beijing |
现在,我们希望取得 "City" 列中值的长度。
我们使用如下 SQL 语句:
SELECTLEN(City) asLengthOfCity FROMPersons
结果集类似这样:
LengthOfCity |
6 |
8 |
7 |
SQL ROUND() 函数
ROUND() 函数
ROUND 函数用于把数值字段舍入为指定的小数位数。
SQL ROUND() 语法
SELECT ROUND (column_name,decimals) FROM table_name
参数 | 描述 |
column_name | 必需。要舍入的字段。 |
decimals | 必需。规定要返回的小数位数。 |
SQL ROUND() 实例
我们拥有下面这个 "Products" 表:
Prod_Id | ProductName | Unit | UnitPrice |
1 | gold | 1000 g | 32.35 |
2 | silver | 1000 g | 11.56 |
3 | copper | 1000 g | 6.85 |
现在,我们希望把名称和价格舍入为最接近的整数。
我们使用如下 SQL 语句:
SELECT ProductName, ROUND (UnitPrice,0) as UnitPrice FROM Products
结果集类似这样:
ProductName | UnitPrice |
gold | 32 |
silver | 12 |
copper | 7 |
SQL NOW() 函数
NOW() 函数
NOW 函数返回当前的日期和时间。
提示:如果您在使用 Sql Server 数据库,请使用 getdate() 函数来获得当前的日期时间。
SQL NOW() 语法
SELECT NOW() FROM table_name
SQL NOW() 实例
我们拥有下面这个 "Products" 表:
Prod_Id | ProductName | Unit | UnitPrice |
1 | gold | 1000 g | 32.35 |
2 | silver | 1000 g | 11.56 |
3 | copper | 1000 g | 6.85 |
现在,我们希望显示当天的日期所对应的名称和价格。
我们使用如下 SQL 语句:
SELECT ProductName, UnitPrice, Now () asPerDate FROM Products
结果集类似这样:
ProductName | UnitPrice | PerDate |
gold | 32.35 | 12/29/2008 11:36:05 AM |
silver | 11.56 | 12/29/2008 11:36:05 AM |
copper | 6.85 | 12/29/2008 11:36:05 AM |
SQL FORMAT() 函数
FORMAT() 函数
FORMAT 函数用于对字段的显示进行格式化。
SQL FORMAT() 语法
SELECT FORM AT (column_name,format) FROM table_name
参数 | 描述 |
column_name | 必需。要格式化的字段。 |
format | 必需。规定格式。 |
SQL FORMAT() 实例
我们拥有下面这个 "Products" 表:
Prod_Id | ProductName | Unit | UnitPrice |
1 | gold | 1000 g | 32.35 |
2 | silver | 1000 g | 11.56 |
3 | copper | 1000 g | 6.85 |
现在,我们希望显示每天日期所对应的名称和价格(日期的显示格式是 "YYYY-MM-DD")。
我们使用如下 SQL 语句:
SELECT ProductName, UnitPrice, FORM AT(Now(),'YYYY-MM-DD') asPerDate
FROM Products
结果集类似这样:
ProductName | UnitPrice | PerDate |
gold | 32.35 | 12/29/2008 |
silver | 11.56 | 12/29/2008 |
copper | 6.85 | 12/29/2008 |
SQL 常用函数及示例
URL: https://www.cnblogs.com/canyangfeixue/p/3203588.html
--SQL 基础-->常用函数
--==================================
/*
一、函数的分类
SQL函数一般分为两种
单行函数 基于单行的处理,一行产生一个结果
多行函数 基于多行的处理,对多行进行汇总,多行产生结果
二、函数形式
function_name [(arg1, arg2,...)]
三、常用的单行函数:
1. 字符函数:
lower(x) 转小写
upper(x) 转大写
initcap(x) 单词首字母转大写
concat(x,y) 字符连接与| | 功能类似
substr(x,start [,length]) 取子串
格式: substr('asdfasdfasdfasddf',1,3)
length(x) 取字符串长度
lpad | rpad(x,width [,pad_string]) 字符定长,(不够长度时,左|右填充)
trim([trim_charFROM] x) 删除首部、尾部字符
格式:trim('h' from 'hello hello')
trim 默认删除方式是both
leading 只删首部 trim(leading 'h' from 'hello helloh')
trailing 只删尾部 trim(trailing 'h' from 'hello helloh')
ltrim(x[,trim_string]) 从x右边删除字符 等价于使用trailing
rtrim(x[,trim_string]) 从x左边删除字符 等价于使用leading
instr 返回子字符串在字符串中的位置
格式:instr(string,substring,position,occurence)
replace(x,search_string,replace_string) 字符替换
格式:replace('字符', '字符' ,'字符')
将字符中的字符,替换成字符
2. 数值函数:
round(x [,y]) 四舍五入
trunc(x,[,y]) 截断
mod(m,n) 求余
ceil(x) 返回特定的最小数(大于等于x的最小整数)
floor(x) 返回特定的最大数(小于等于x的最大整数)
3. 日期函数:
sysdate 返回系统当前日期
实际上ORACLE内部存储日期的格式是:世纪,年,月,日,小,分钟,秒。
不管如何输入都这样
9i开始,默认的日期格式是:DD-MON-RR,之前是DD-MON-YY
RR 和YY 都是世纪后的两位,但有区别
ORACLE的有效日期范围是:公元前年月日-年月日
RR日期格式:
1、如果当前年份最后两位是:-,并且指定年份的最后两位也为-,则返回本世纪
例:当前年:, 01--,表示2008 年
2、如果当前年份最后两位是:-,指定年份最后两位为50-则返回上世纪。
例:当前年:,01--,表示1998
3、如果当前年最后两位为:-,指定年份最后两位为0-,则返回下世纪。
例:当前年:,--表示的是年
4、如果当前年最后两位是:-,指定年份最后两位为:- 则返回本世纪。
例:当前年:,--表示的是年
months_between(x,y) 两个日期之间相差的月数
例:查询最近个月入职的员工
add_months(x,y) 返回x上加上y个月后的结果
last_day(x) 返回指定日期所在月最后一天的日期
next_day(x,day) 返回指定日期的下一day的时间值,day是一个文本串,比如SATURDAY
extract 提取日期
select extract(day from sysdate) from dual
select extract(month from sysdate) from dual;
select extract(year from sysdate) from dual;
4. 转换函数:
TO_DATE(char[, 'format_model']) TO_DATE函数将一个字符串转换成日期格式
函数有个fx 修饰语。这个修饰语为TO_DATE函数的字符函
数中的独立变量和日期格式指定精确匹配.
TO_CHAR(date, 'format_model') 转换为CHAR类型,
必须与单引号一起嵌入,区分大小写,
用逗号把日期数值分开,有一个fm 移除填补空白或者阻止零开头
TO_CHAR(number, 'format_model')
TO_NUMBER(char[, 'format_model']) TO_NUMBER 函数将一个字符串转换成一个数字格式:
select to_date('1999-09-23','yyyy-mm-dd') from dual;
数据类型的转换分为隐式数据类型转换和显式数据类型转换
在表达式中, Oracle服务器能自动地转换下列各项,即隐式转换:
VARCHAR2 or CHAR =====〉NUMBER
VARCHAR2 or CHAR =====〉DATE
对表达式赋值, Oracle服务器能自动地转换下列各项,即隐式转换:
NUMBER =======〉VARCHAR2 or CHAR
DATE =======〉VARCHAR2 or CHAR
日期格式元素:
YYYY 数字年份
YEAR 英文年份
MM 数字月
MONTH 英文月
MON 英文缩写
DD 数字日
DY 英文缩写
DAY 英文
5. 通用函数
decode 条件判断
格式:decode (col|expression,search1,result1 [,search2,result2,...] [,default])
判断col|exporession的值,当search1匹配时,则返回,result1,
与search2匹配时,返回result2 ... 如果都不匹配,返回default。
select EMPNO,ENAME,JOB,SAL,
decode(job,'CLERK',SAL*1.15,'SALESMAN',SAL*1.1,SAL*1.12) NEW_SAL
FROM SCOTT.EMP;
if then else 条件判断
case 表达式
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
--lower函数
SQL> select lower('SQL') from dual;
LOW
---
sql
SQL> select EMPNO,ENAME,JOB from scott.emp where lower(ename) like 'a%';
EMPNO ENAME JOB
---------- ---------- ---------
7499 ALLEN SALESMAN
7876 ADAMS CLERK
SQL> insert into scott.emp(empno,ename) values(9999,'albert');
1 row created.
SQL> select * from scott.emp where lower(ename) like 'a%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ---------- ---------- ---------- ----------
9999 albert
7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30
7876 ADAMS CLERK 7788 1987-05-23 1100 20
SQL> select * from scott.emp where ename like 'A%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ---------- ---------- ---------- ----------
7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30
7876 ADAMS CLERK 7788 1987-05-23 1100 20
--upper函数
SQL> select upper('SQL Course') as Upper_Char from dual;
UPPER_CHAR
----------
SQL COURSE
--单词首子母转大写
SQL> select initcap(ename) as initcap_name scott.emp where ename = 'albert';
INITCAP_NAME
----------
Albert
--字符的拼接,||与concat等效
SQL> select ename || ' is an ' || job from scott.emp where ename = 'SCOTT';
ENAME||'ISAN'||JOB
---------------------------
SCOTT is an ANALYST
SQL> select concat(concat(ename,' is an '),job) as concat_str from scott.emp where ename = 'SCOTT';
CONCAT_STR
--------------------------
SCOTT is an ANALYST
--SUBSTR,截取子串,下面的例子从第个位置开始连续截取个字符
SQL> select substr('HelloWorld',2,3) from dual;
SUB
---
ell
--LENGTH 取字符串长度
SQL> select length('HelloWord') as String_length from dual;
STRING_LENGTH
-------------
9
-- lpad | rpad 字符串的填充
-- lpad,左填充,直到达到指定长度为止
SQL> select lpad('salary',10,'*') as String_Lpad from dual;
STRING_LPA
----------
****salary
--指定长度为,多出的部分被截断
SQL> select lpad('salary',4,'*') as String_Lpad from dual;
STRI
----
sala
--rpad,右填充,直到达到指定长度为止
SQL> select rpad('salary',10,'|') as String_Rpad from dual;
STRING_RPA
----------
salary||||
--指定长度为,多出的部分被截断
SQL> select rpad('salary',5,'|') as String_Rpad from dual;
STRIN
-----
salar
-- trim 删除首尾字符,格式:trim('h' from 'hello hello'),默认的方式为both
SQL> select trim('h' from 'hello helloh') as String_Trim from dual;
STRING_TRI
----------
ello hello
-- trim 删除首尾字符,指定leading只删首部
SQL> select trim(leading 'h' from 'hello helloh') as Trim_Leading from dual;
TRIM_LEADIN
-----------
ello helloh
-- trim 删除首尾字符,指定trailing只删尾部
SQL> select trim(trailing 'h' from 'hello helloh') as Trim_Trailling from dual;
TRIM_TRAILL
-----------
hello hello
--rtrim ,ltrim
SQL> select rtrim('hello helloh','h') as Rtrim_String ,
2 ltrim('hello helloh','h') as Ltrim_String
3 from dual;
RTRIM_STRIN LTRIM_STRIN
----------- -----------
hello hello ello helloh
--replace 字符替换
SQL> select replace('Jack and Johnson','J','Bl') as String_Replace from dual;
STRING_REPLACE
------------------
Black and Blohnson
--instr 下面的示例从第个字符开始,返回第二个OR的位置
SQL> select instr('CORPORATE FOLLOR','OR',3,2) as Instring from dual;
INSTRING
----------
15
--round 四舍五入函数
SQL> select round(102.253,2) as round_func from dual;
ROUND_FUNC
----------
102.25
SQL> select round(102.253,0) as round_func from dual;
ROUND_FUNC
----------
102
SQL> select round(102.253,-1) as round_func from dual;
ROUND_FUNC
----------
100
--trunc 截断函数
SQL> select trunc(2010.328) as trunc_func_1,
2 trunc(2010.328,1) as trunc_func_2,
3 trunc(2010.328,-1) as trunc_func_3
4 from dual;
TRUNC_FUNC_1 TRUNC_FUNC_2 TRUNC_FUNC_3
------------ ------------ ------------
2010 2010.3 2010
--#MOD(m,n) 取余函数
SQL> select mod(2010,3) as mod_func from dual;
MOD_FUNC
----------
0
SQL> select mod(5,3) as mod_func from dual;
MOD_FUNC
----------
2
--ceil(x) 返回特定的最小数(大于等于x的最小整数)
SQL> select ceil(593.3) as ceil_func from dual;
CEIL_FUNC
----------
594
--floor(x) 返回特定的最大数(小于等于x的最大整数)
SQL> select floor(593.4) as floor_func from dual;
FLOOR_FUNC
----------
593
--month_between(日期,日期)两个日期相差的月数
SQL> select empno,ename,job,months_between(sysdate,hiredate) as diff_month from scott.emp;
EMPNO ENAME JOB DIFF_MONTH
---------- ---------- --------- ----------
9999 albert
7369 SMITH CLERK 351.370601
7499 ALLEN SALESMAN 349.273827
7521 WARD SALESMAN 349.209311
7566 JONES MANAGER 347.854472
7654 MARTIN SALESMAN 342
7698 BLAKE MANAGER 346.88673
7782 CLARK MANAGER 345.628666
7788 SCOTT ANALYST 275.306085
7839 KING PRESIDENT 340.370601
7844 TURNER SALESMAN 342.660924
SQL> select * from scott.emp where months_between(sysdate,hiredate) <= 300;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ---------- ---------- ---------- ----------
7788 SCOTT ANALYST 7566 1987-04-19 3000 20
7876 ADAMS CLERK 7788 1987-05-23 1100 20
--add_months(日期,n) 返回在指定的日期后,加上n个月后的日期
SQL> select add_months(sysdate,5) from dual;
ADD_MONTHS
----------
2010-08-28
--last_day(sysdate) 返回指定日期所在月最后一天的日期
SQL> select last_day(sysdate) from dual;
LAST_DAY(S
----------
2010-03-31
--next_day 返回指定日期的下一day的时间值,day是一个文本串,比如SATURDAY
SQL> select next_day('05-FEB-2005','TUESDAY') as nextday from dual;
NEXTDAY
---------
08-FEB-05
/*EXTRACT*/
SQL> select extract(day from sysdate) from dual;
EXTRACT(DAYFROMSYSDATE)
-----------------------
28
SQL> select extract(month from sysdate) from dual;
EXTRACT(MONTHFROMSYSDATE)
-------------------------
3
SQL> select extract(year from sysdate) from dual;
EXTRACT(YEARFROMSYSDATE)
------------------------
2010
--使用ROUND 和TRUNC函数处理日期
--round(sysdate,'MONTH') 当月第一天
--round(sysdate,'YEAR') 当年的第一天
--trunc(sysdate,'MONTH') 当月第一天
--trunc(sysdate,'YEAR') 当年的第一天
SQL> select sysdate,round(sysdate,'MONTH'),round(sysdate,'YEAR'),
2 trunc(sysdate,'MONTH'),trunc(sysdate,'YEAR')
3 from dual;
SYSDATE ROUND(SYS ROUND(SYS TRUNC(SYS TRUNC(SYS
--------- --------- --------- --------- ---------
15-APR-10 01-APR-10 01-JAN-10 01-APR-10 01-JAN-10
--类型转换
-- to_char
SQL> select empno,ename,hiredate,to_char(hiredate,'fmDD Month YYYY') as hiredate2,
2 to_char(hiredate,'DD MM YYYY') as hiredate3
3 from scott.emp
4 where sal > 2500;
EMPNO ENAME HIREDATE HIREDATE2 HIREDATE3
---------- ---------- --------- ----------------- ----------
7566 JONES 02-APR-81 2 April 1981 02 04 1981
7698 BLAKE 01-MAY-81 1 May 1981 01 05 1981
7788 SCOTT 19-APR-87 19 April 1987 19 04 1987
7839 KING 17-NOV-81 17 November 1981 17 11 1981
7902 FORD 03-DEC-81 3 December 1981 03 12 1981
SQL> select to_char(12345.67) as char1,to_char(12345.67,'99,999.99') as char2
2 from dual;
CHAR1 CHAR2
-------- ----------
12345.67 12,345.67
--当被转换的数据位数超过格式指定位数,则出现错误。
SQL> select to_char(12345678.90,'99,999.99') as char1 from dual;
CHAR1
----------
##########
--to_number
SQL> select to_number('970.13') as number1,
2 to_number('970.13') + 35.5 as nunber2,
3 to_number('-$12,345.67','$99,999.99') as number3
4 from dual;
NUMBER1 NUNBER2 NUMBER3
---------- ---------- ----------
970.13 1005.63 -12345.67
--to_date
--注意:最终日期采用默认格式DD-MON—YY显示
SQL> select to_date('05-JUL-2008') as date1,to_date('05-JUL-08') as date2,
2 to_date('July 5,2008','MONTH DD,YYYY') as date3,
3 to_date('7.4.08','MM.DD.YY') as date4
4 from dual;
DATE1 DATE2 DATE3 DATE4
--------- --------- --------- ---------
05-JUL-08 05-JUL-08 05-JUL-08 04-JUL-08
--case when
SQL> select empno,ename,sal,deptno,case deptno when 20 then 1.10 * sal
2 when 30 then 1.20 * sal
3 else 1.30 * sal end as newsal
4 from scott.emp order by deptno;
EMPNO ENAME SAL DEPTNO NEWSAL
---------- ---------- ---------- ---------- ----------
7782 CLARK 2450 10 3185
7839 KING 5000 10 6500
7934 MILLER 1300 10 1690
7566 JONES 2975 20 3272.5
7902 FORD 3000 20 3300
7876 ADAMS 1100 20 1210
7369 SMITH 800 20 880
7788 SCOTT 3000 20 3300
7521 WARD 1250 30 1500
7844 TURNER 1500 30 1800
/*DECODE*/
SQL> select empno,ename,job,sal, decode(job,'CLERK',sal*1.5,'SALESMAN',sal*1.1,sal*1.2) as newsal from scott.emp;
EMPNO ENAME JOB SAL NEWSAL
---------- ---------- --------- ---------- ----------
9999 albert
7369 SMITH CLERK 800 1200
7499 ALLEN SALESMAN 1600 1760
7521 WARD SALESMAN 1250 1375
7566 JONES MANAGER 2975 3570
7654 MARTIN SALESMAN 1250 1375
7698 BLAKE MANAGER 2850 3420
7782 CLARK MANAGER 2450 2940
7788 SCOTT ANALYST 3000 3600
7839 KING PRESIDENT 5000 6000
7844 TURNER SALESMAN 1500 1650数据预处理建议
数据预处理是数据分析和机器学习项目中的关键步骤,可以显著影响最终的模型性能和分析结果。以下是一些建议,帮助您进行数据预处理:
l数据清洗: 首先,检查数据中是否存在缺失值、异常值和重复数据。对于缺失值,可以选择删除相关记录、填充缺失值,或使用插值方法来估计缺失值。异常值可能需要被修正或移除,以免对模型造成负面影响。
l数据标准化和归一化: 如果数据集包含具有不同量纲的特征,应考虑对其进行标准化或归一化,以确保模型训练的稳定性。常用的方法包括Z-score标准化和最小-最大归一化。
l特征选择: 在数据中可能存在冗余或不相关的特征。使用特征选择技术可以帮助缩小特征空间,提高模型效率。常见的方法包括方差阈值、相关性分析和特征重要性评估。
l数据编码: 将分类数据转换为数值形式,以便机器学习算法能够处理。常用的编码方法包括独热编码(One-Hot Encoding)和标签编码(Label Encoding)。
l处理类别不平衡: 如果数据中存在类别不平衡问题(某些类别样本数量明显不足),可以考虑使用过采样、欠采样或合成少数类样本的方法来平衡类别分布。
l特征工程: 根据领域知识和数据的特点,创建新的特征或进行特征变换,以提供更多有关数据的信息。这可以提高模型的性能。
l时间序列数据处理: 如果您的数据是时间序列数据,考虑进行滞后处理、平滑或季节性调整,以捕获时间相关性和趋势。
l交叉验证: 在数据预处理之前,划分训练集、验证集和测试集。这有助于评估模型的性能,同时避免数据泄漏。
l记录数据预处理步骤: 记录所有数据预处理步骤,以便能够重现和追溯分析过程。这对于数据科学项目的透明性和可重复性非常重要。
l可视化分析: 使用可视化工具来探索数据,理解特征分布和关系,以帮助做出数据预处理决策。
l评估影响: 在应用每个数据预处理步骤后,评估其对数据质量和模型性能的影响。确保它们有助于达到项目的目标。
l数据预处理是数据科学项目中的一个迭代过程,需要不断尝试不同的方法和技术,以找到最适合问题的方法。定期监控数据质量和模型性能,随着项目的进行进行调整和改进。
SQL语言参考
URL:https://www.w3school.com.cn/sql/index.asp