
-
1 子查询
-
2 相关和不相关子查...
-
3 子查询和表连接对比
子查询
转载自:https://zhuanlan.zhihu.com/p/603197412?utm_id=0
前言
概念:
出现在其他语句内部的SELECT语句,称为子查询或内查询(其他语句:不限于SELECT语句,不过最常出现在SELECT语句内部)。与之相对地,外部的查询语句,称为外查询或主查询。
分类:
按子查询出现的位置:SELECT后面、FROM后面、WHERE或HAVING后面、EXISTS后面(相关子查询)
按查询结果的行列数:标量子查询(结果只有一行一列)、列子查询(结果只有一列多行,也称为多行子查询)、行子查询(结果有一行多列或多行多列)、表子查询(结果一般为多行多列)
SELECT后面:仅仅支持标量子查询
FROM后面:支持表子查询
WHERE或HAVING后面:主要支持标量子查询和列子查询,行子查询用得比较少
EXISTS后面:支持表子查询
1. WHERE或HAVING后面的子查询
特点:
(1)子查询放在小括号内
(2)子查询一般放在条件的右侧
(3)标量子查询一般搭配着单行操作符使用,比如:>、<、>=、<=、=、!=;列子查询一般搭配着多行操作符使用,比如IN、ANY/SOME、ALL
(4)子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果。
1.1 标量子查询
子查询结果返回标量,即1行1列。
案例1:谁的工资(salary)比 Abel 高(注:Abel是姓氏)?已知:表employees中有员工信息,包含工资字段salary。
分析:从employees中先获取姓氏为Abel的工资,然后再筛选比Abel的工资高的员工。
# ①查询Abel(姓氏)的工资 SELECT salary FROM employees WHERE last_name = 'Abel'; # ②查询员工的信息,满足salary>①的结果 SELECT * FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
因为子查询的结果只有一行一列(表中Abel姓氏的员工只有一位,对应的工资也只有1个),所以是标量子查询。
案例2:返回job_id与141号(employee_id)员工相同,salary比143号员工多的员工姓名(first_name和last_name),job_id和工资(salary)。注:以上字段均在employees表中。
分析:先从employees表中找到员工id为141号的工作id,还有员工id为143号的工资,然后再筛选工作id与前者相等,工资比后者高的员工。
# ①查询141号员工的工作id SELECT job_id FROM employees WHERE employee_id = 141; # ②查询143号员工的工资 SELECT salary FROM employees WHERE employee_id = 143; # ③查询员工的姓名、job_id和工资,要求job_id=①且salary>② SELECT first_name,last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );
这个案例中有2个子查询,说明WHERE后面可以支持多个子查询。
案例3:返回公司工资最少的员工last_name,job_id,salary。注:以上字段均在employees表中。
分析:从employees表中找到最少的工资,然后筛选出工资数目是最少工资的员工last_name,job_id,salary。
# ①查询公司的最低工资 SELECT MIN(salary) FROM employees; # ②查询last_name,job_id和salary,要求salary=① SELECT last_name,job_id,salary FROM employees WHERE salary = ( SELECT MIN(salary) FROM employees );
案例4:查询最低工资大于50号部门最低工资的部门id和其最低工资。
分析:从employees表中找到50号部门的最低工资,然后筛选部门最低工资大于前者的部门id和其最低工资。
# ①查询50号部门的最低工资 SELECT MIN(salary) FROM employees WHERE department_id = 50; # ②查询部门id,最低工资,满足最低工资>① SELECT department_id,MIN(salary) AS min_salary FROM employees GROUP BY department_id HAVING MIN(salary) > ( SELECT MIN(salary) FROM employees WHERE department_id = 50 );
这里的子查询是嵌套在HAVING后面的,因为涉及按部门id分组求最低工资。
注意:子查询的结果若不是一行一列,不能使用标量子查询,不能搭配单行操作符。
1.2 列子查询(多行子查询)
子查询结果返回1列多行。
| 操作符 | 含义 |
|---|---|
| (NOT) IN | 等于列表中的任意一个 |
| ANY|SOME | 和子查询返回的某一个值比较(列表中某一个满足条件) |
| ALL | 和子查询返回的所有值比较(列表中均满足条件) |
事实上,IN()与= ANY()达到的效果一样;NOT IN()与!= ALL()效果一样。
案例1:返回location_id是1400或1700的部门中的所有员工姓名。location_id字段在departments表中,员工姓名在employees表中,二表共有字段是department_id。
分析:从departments表中查询location_id是1400或1700的部门id(department_id),然后从employees表中找到部门id在前者中的员工姓名。
# ①查询location_id是1400或1700的部门id(在departments表中) SELECT department_id FROM departments WHERE location_id IN (1400,1700); # ②查询员工姓名,要求部门号是①列表中的一个(在employees表中) SELECT first_name,last_name FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location_id IN (1400,1700) );
子查询中返回location_id是1400或1700的部门id是多行的,因此是列子查询(多行子查询)。
案例2:返回其它工种中比job_id为'IT_PROG'工种任一工资低的员工的员工号(employee_id)、last_name、job_id、salary。注:以上字段均在employees表中。
分析:从employees表中找到job_id为'IT_PROG'工种的所有工资,然后查询其它工种中工资低于前者列表中任一值的员工信息,注意:其它工种就表明job_id不能等于'IT_PROG'。
# ①查询job_id为'IT_PROG'的部门工资 SELECT salary FROM employees WHERE job_id = 'IT_PROG'; # ②查询employee_id、last_name、job_id、salary,要求salary<①中任一值,且job_id不是'IT_PROG' SELECT employee_id,last_name,job_id,salary FROM employees WHERE salary < ANY( SELECT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id != 'IT_PROG';
案例3:返回其它工种中比job_id为'IT_PROG'工种所有工资都低的员工的员工号(employee_id)、last_name、job_id、salary。注:以上字段均在employees表中。
# ①查询job_id为'IT_PROG'的部门工资 SELECT salary FROM employees WHERE job_id = 'IT_PROG'; # ②查询employee_id、last_name、job_id、salary,要求salary<①中所有值,且job_id不是'IT_PROG' SELECT employee_id,last_name,job_id,salary FROM employees WHERE salary < ALL( SELECT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id != 'IT_PROG';
1.3 行子查询
子查询结果返回1行多列或多行多列,重点是多列。
案例1:查询员工编号(employee_id)最小且工资(salary)最高的员工信息。
分析:这道题可以采用标量子查询的思想,具体做法类似1.1节中的案例2。从employees表中分别查询最小的员工编号和最高的员工工资,筛选同时符合这两个条件的员工信息。
# ①查询最小的员工编号 SELECT MIN(employee_id) FROM employees; # ②查询最高的员工工资 SELECT MAX(salary) FROM employees; # ③查询员工信息,要求employee_id=①且salary=② SELECT * FROM employees WHERE employee_id = ( SELECT MIN(employee_id) FROM employees ) AND salary = ( SELECT MAX(salary) FROM employees );
但是,我们这里可以换一种思路,采用行子查询,查询结果不变。
# 行子查询 SELECT * FROM employees WHERE (employee_id,salary) = ( SELECT MIN(employee_id),MAX(salary) FROM employees );
行子查询具有局限性,子查询的多个字段(列)需要有一样的操作符,比如这个案例中employee_id和salary都用=这个操作符进行筛选,因此可以把(employee_id,salary)看作一个虚拟的字段。
2. SELECT后面的子查询
SELECT后面仅仅支持标量子查询,即1行1列。
案例1:查询每个部门(department_id)的员工个数。注:不能仅从employees表中计算员工个数,因为employees表中只包含有员工的部门,存在一些部门没有员工的情况。
分析:departments表中罗列了所有的部门,有些部门有员工,员工信息出现在employees表中,可在employees表中统计个数,但有些部门没有员工,员工个数就是0。因此,主查询的表是departments,子查询的表是employees,且子查询中必须要满足这两个表格的部门id相等。具体查询语句如下,根据SQL的执行顺序得知此子查询的结果返回的是一个标量。
# 子查询 SELECT *,( SELECT COUNT(employee_id) FROM employees e WHERE e.department_id = d.department_id) AS counts FROM departments d;
当然,这个案例可以采用连接的方法,因为涉及两个表(employees和departments),且有公共字段(department_id),具体查询语句如下:
# 连接查询 SELECT d.*, COUNT(employee_id) AS counts FROM departments d LEFT JOIN employees e ON d.`department_id` = e.`department_id` GROUP BY d.`department_id`;
3. FROM后面的子查询
FROM后面一般是表,代表数据源,因此是把子查询的结果当作一张表,且必须给这张表起别名。
案例1:查询每个部门的平均工资的工资等级。
已知工资等级表(job_grades):
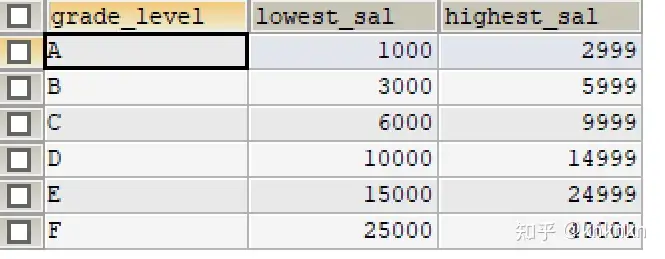
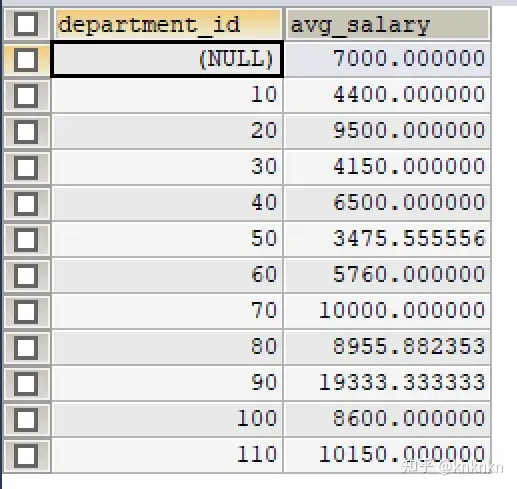
# ①查询每个部门的平均工资 SELECT department_id,AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
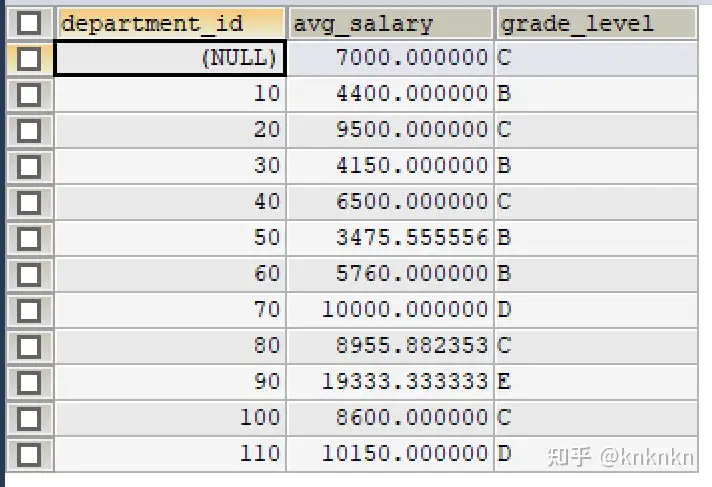
根据平均工资在工资等级表的情况,可以判别每个部门平均工资的工资等级,这里就涉及非等值连接,判断平均工资是否介于某等级的最低工资和最高工资之间。
# ②查询工资等级,判断平均工资在哪个等级 SELECT avg_dep.*,grade_level FROM ( SELECT department_id,AVG(salary) AS avg_salary FROM employees GROUP BY department_id ) avg_dep LEFT JOIN job_grades g ON avg_salary BETWEEN lowest_sal AND highest_sal;
4. EXISTS后面的子查询
EXISTS后面的子查询也叫做相关子查询。
语法:EXISTS(完整的查询语句),括号内的查询语句可以1行1列,也可以多行多列。
结果:1或0,当括号内有查询结果时,返回1,当括号内没有查询结果时,返回0。在逻辑判断中,1可认为是True,0可认为是False。
一般来讲,EXISTS后面的子查询都可以用IN后面的子查询代替,所以用得不是很多。
案例1:查询有员工的部门名。
# 采用IN的方式 SELECT department_name FROM departments d WHERE d.department_id IN ( SELECT department_id FROM employees ); # 采用EXISTS的方式 SELECT department_name FROM departments d WHERE EXISTS( SELECT department_id FROM employees e WHERE e.`department_id` = d.`department_id` );
总结
(1)WHERE或HAVING后面的子查询结果可以是1行1列(标量),多行1列,或者1行多列,这里的子查询结果是作为筛选条件的,一般可使用单行运算符,比如<、>、=、<=、>=、!=,也可使用多行运算符,比如IN、ANY、SOME、ALL,常用的是IN。
(2)SELECT后面的子查询结果必须是1个标量,即1行1列,这里的子查询结果一般是生成新的字段。
(3)FROM后面的子查询结果一般是多行多列,充当一张表,且这张表必须取别名。
(4)EXISTS后面的子查询一般可以用IN后面的子查询代替。




